
 |
云端运营数据存储服务-Materialize
专用API
【更新时间: 2024.08.22】
Materialize云端运营数据存储服务是操作型数据仓库,它以数据仓库的便捷性提供流式传输的速度。借助 Materialize,组织只需使用 SQL 即可操作实时数据。
|
浏览次数
30
采购人数
0
试用次数
0
 SLA: N/A
响应: N/A
适用于个人&企业
SLA: N/A
响应: N/A
适用于个人&企业
收藏
×
完成
取消
×
书签名称
确定
|


- API详情
- 定价
- 使用指南
- 常见 FAQ
- 关于我们
- 相关推荐


什么是Materialize的云端运营数据存储服务?
Materialize云端运营数据存储服务是一种结合了数据仓库的易用性和流式处理速度的新型数据库系统。它旨在提供新鲜、一致的数据,以满足需要实时或近实时数据支持的复杂业务场景。Materialize 通过其独特的架构和基于差异数据流的引擎,能够在数据变化时立即提供更新的结果,从而支持高效的运营决策和业务自动化。
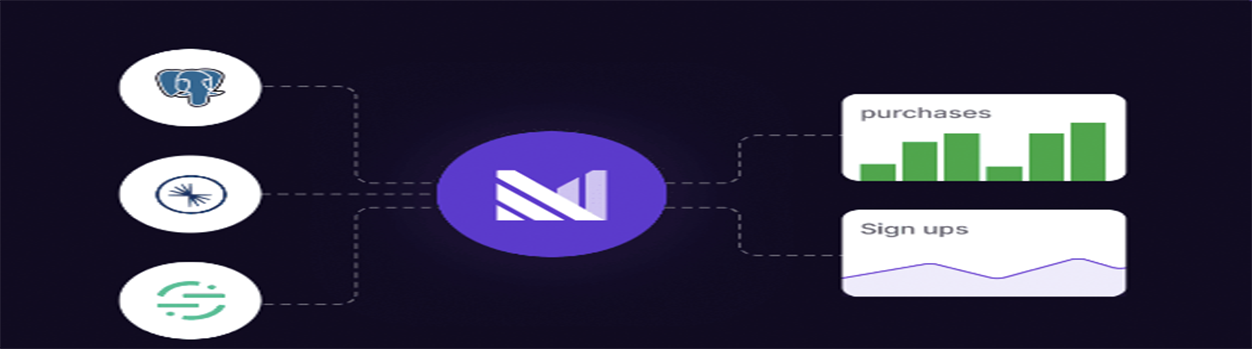
Materialize的云端运营数据存储服务有哪些核心功能?
- 实时数据流处理:Materialize能够处理快速变化的数据,并在亚秒级别内更新结果。
- 强一致性视图:提供强一致性而非最终一致性的数据视图。
- SQL交互式查询:支持通过SQL快速且交互地使用结果。
- 物化视图:持续计算物化视图的更新以获得最新结果。
- 流输出选项:允许订阅查询更新或将更新发送到数据仓库或流媒体平台。
- 存储-计算分离:实现工作负载隔离和无限规模。
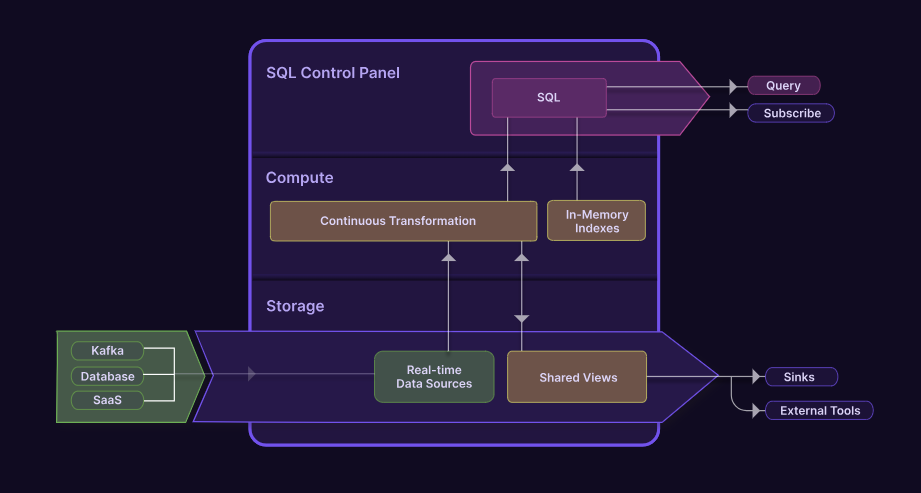
Materialize的云端运营数据存储服务的技术原理是什么?
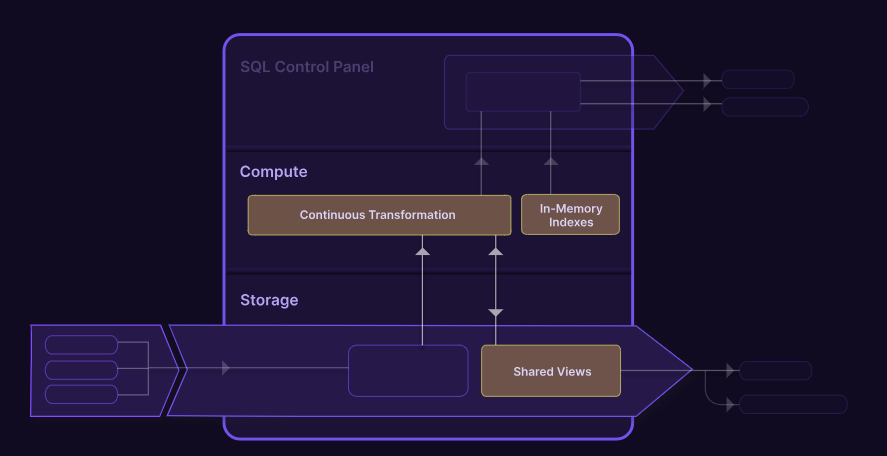
| 从分离存储和计算开始 存储-计算分离可实现工作负载隔离和无限规模。 |
 |
| 2. 添加实时数据源 Materialize 有多个流输入源,可以不断从上游 OLTP 数据库、流平台、Web 钩子和其他系统提取数据。 |
 |
| 3. 逐步转换并使用 SQL 查询结果 与运行一次性批量转换不同,支持物化视图的数据在计算层中不断转换。与提取加载和转换不同,请考虑提取加载和增量转换 (ELiT)。只需使用 SQL,即可像标准 Postgres 视图一样查询结果。 |
 |
| 4. 添加流输出选项 除了提供高并发性和低延迟的读取密集型 SQL 查询之外,用户还可以订阅查询的更新或将更新发送到数据仓库或流媒体平台。 |
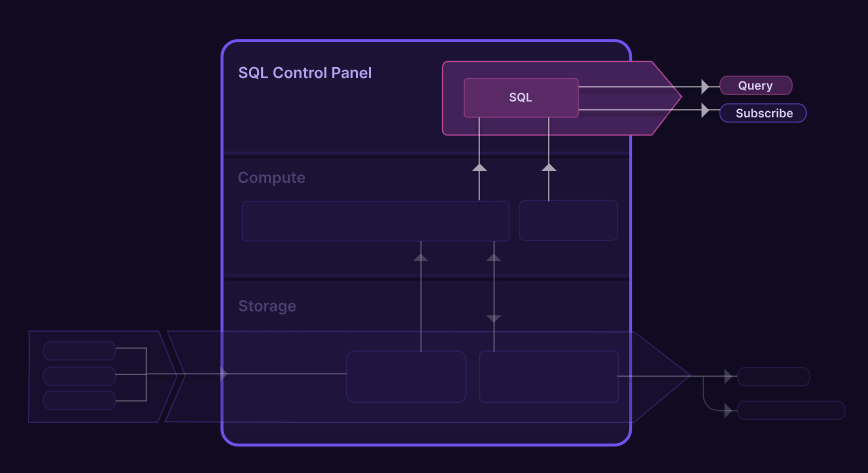 |
| 5. 连接、查询和传递快速变化数据的更好方法 在 Materialize 中,您可以从整个组织获取数据并将其转换为实时视图,这些视图可以进行查询和组合,并具有很强的一致性,以支持您的业务逻辑。 |
 |
Materialize的云端运营数据存储服务的核心优势是什么?
|
停止使运营数据库超载 通过从关键任务系统中卸载要求高、查询密集型的工作 负载来满足您的可用性和性能 SLA。 |
消除读取副本并将查询性能提高 100 倍 捕获数据库更新并创建不断更新的视图。使用一小部分 硬件即可获得更快的读取性能。 |
|
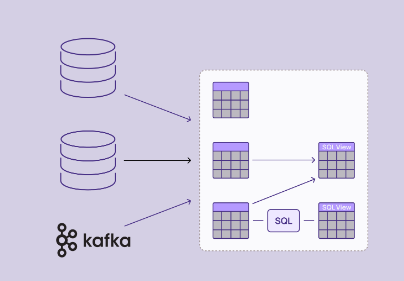
使用 SQL 实时连接数据 打破数据孤岛。使用 SQL 跨数据库和其他来源连接数据, 以创建高度一致且始终最新的快速移动数据视图。 |
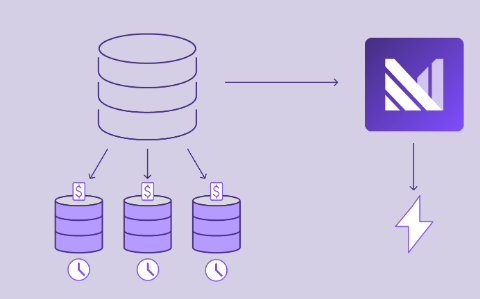
减少数据仓库支出 避免将实时查询密集型工作负载发送到数据仓库, 而导致成本飙升。将这些查询移至 Materialize, 以极低的成本保持其最新状态。 |
在哪些场景会用到Materialize的云端运营数据存储服务?
1. 实时流程优化:跨数据源获取全新、一致的业务视图,以便快速、自信地对变化做出反应。
2. 欺诈检测:在恶意活动发生时立即标记并减轻其影响,从而提高盈利能力和客户满意度。

3. 异常检测:实时从多个来源流式传输数据,并使用 SQL 识别偏离正常行为的模式。

4. 自动化和警报:通过对新鲜、可信的数据发出实时警报和自动操作来消除延迟并加快行动。

5. 动态客户体验:当客户仍在与您的品牌互动时,使用实时客户信号来优化客户的体验。

6. 生成式人工智能:为检索增强生成 (RAG) 模型和 LLM 驱动的代理提供最新的上下文。

Materialize 是一种云操作数据存储,它以数据仓库的便捷性提供流式传输速度。借助 Materialize,组织可以使用 SQL 来转换、交付和处理快速变化的数据。
此快速入门将帮助您在几分钟内启动并运行,且没有任何依赖关系,因此您可以亲身体验操作数据存储的超能力:
-
交互性:从索引的仓库关系和派生结果中获取即时响应。
-
新鲜度:观察结果随着您输入的变化而立即发生变化。
-
一致性:结果始终正确;绝不会暂时出错。
先决条件
一个 Materialize 账户。如果您没有账户,可以。
步骤 0. 登录 Materialize
导航到并登录。默认情况下,您应该进入 SQL Shell。如果您已经登录,则可以在左侧菜单中访问 SQL Shell。
步骤 1. 采集流数据
作为拍卖行经营者,您希望在欺诈行为发生时立即发现,以便立即采取行动。最近,您一直在与作斗争——这些用户购买物品只是为了快速转售以牟利。
-
让我们首先启动内置的,这样您就有了一些可以使用的数据。
CREATE SOURCE auction_house
FROM LOAD GENERATOR AUCTION
(TICK INTERVAL '1s', AS OF 100000)
FOR ALL TABLES; -
使用以下命令来了解正在生成的数据:
SHOW SOURCES;name | type
------------------------+-----------------
accounts | subsource
auction_house | load-generator
auction_house_progress | progress
auctions | subsource
bids | subsource
organizations | subsource
users | subsource现在,您将重点关注
auctions和数据集。在您完成快速入门的过程中,bids数据将不断生成。 -
在继续下一步之前,请先了解一下您将要处理的数据:
SELECT * FROM auctions LIMIT 1;id | seller | item | end_time
----+--------+--------------------+----------------------------
1 | 1824 | Best Pizza in Town | 2023-09-10 21:24:54.838+00SELECT * FROM bids LIMIT 1;id | buyer | auction_id | amount | bid_time
----+-------+------------+--------+----------------------------
10 | 3844 | 1 | 59 | 2023-09-10 21:25:00.465+00
第 2 步:使用索引提高速度
运营工作需要在数据可用时立即进行交互访问。要识别潜在的拍卖翻转者,您需要跟踪每场已完成拍卖的获胜出价。
-
创建一个
auctions,将来自和的数据连接起来,以获取 每次拍卖的bids最高出价。amount``end_timeCREATE VIEW winning_bids AS
SELECT DISTINCT ON (auctions.id) bids.*, auctions.item, auctions.seller
FROM auctions, bids
-- Where all bids occurred during the auction
WHERE auctions.id = bids.auction_id
AND bids.bid_time < auctions.end_time
-- Where all auctions have completed
AND mz_now() >= auctions.end_time
ORDER BY auctions.id,
bids.amount DESC,
bids.bid_time,
bids.buyer;与其他 SQL 数据库一样,Materialize 中的视图只是嵌入
SELECT语句的别名;仅在调用视图时才会计算结果。 -
您可以直接查询视图,但目前这还不够令人印象深刻!查询视图会重新运行嵌入的语句,这在数据量增长时会产生一些成本。
SELECT * FROM winning_bids
WHERE item = 'Best Pizza in Town'
ORDER BY bid_time DESC;哎呀!在 Materialize 中,您可以使用来保持结果逐步更新并可立即访问。
-
接下来,尝试
winning_bids使用可以帮助优化点查找和连接等操作的列在视图上创建多个索引。CREATE INDEX wins_by_item ON winning_bids (item);
CREATE INDEX wins_by_bidder ON winning_bids (buyer);
CREATE INDEX wins_by_seller ON winning_bids (seller);这些索引将把结果保存
winning_bids在内存中,并像缓存一样工作——只是您不需要连接一个,也不必担心结果变得陈旧。 -
如果您现在尝试在点击其中一个索引(例如,使用点查找)时读取数据
winning_bids,事情应该会变得更加交互。SELECT * FROM winning_bids WHERE item = 'Best Pizza in Town' ORDER BY bid_time DESC;但要发现并应对欺诈行为,您不能依赖人工检查,对吗?您需要密切关注这些欺诈者。幸运的是,您在上一步中创建的索引也使连接更具交互性(就像在其他数据库中一样)!
-
创建一个视图,检测用户何时作为竞标者赢得拍卖,然后被识别为以更高价格出售某件物品的卖家。
CREATE VIEW fraud_activity AS
SELECT w2.seller,
w2.item AS seller_item,
w2.amount AS seller_amount,
w1.item buyer_item,
w1.amount buyer_amount
FROM winning_bids w1,
winning_bids w2
-- Identified as a buyer and seller for any two auctions
WHERE w1.buyer = w2.seller
-- For the same item
AND w1.item = w2.item
-- Tries to sell at a higher price
AND w2.amount > w1.amount;啊哈!现在,您可以根据此视图的结果实时捕捉任何拍卖翻转者。
SELECT * FROM fraud_activity LIMIT 100;
步骤3.查看结果变化!
运营工作需要根据最新数据进行处理。一旦您的数据发生变化,Materialize 就会做出反应。让我们 通过手动将某些帐户标记为欺诈并实时观察结果变化来验证这一点是否真的发生了!
-
创建一个,让您可以手动标记欺诈性账户。
CREATE TABLE fraud_accounts (id bigint); -
在新的浏览器窗口中,与此窗口并排,导航到,然后弹出另一个 SQL Shell。
-
为了查看结果随时间的变化,让我们
SUBSCRIBE进行一个查询,返回总体而言排名前 5 位的拍卖获胜者。SUBSCRIBE TO (
SELECT buyer, count(*)
FROM winning_bids
WHERE buyer NOT IN (SELECT id FROM fraud_accounts)
GROUP BY buyer
ORDER BY 2 DESC LIMIT 5
);您可以密切关注结果,但目前结果可能不会有太大变化。您将在下一步中修复此问题!
-
从运行的窗口中维护的列表中选择一个买家
SUBSCRIBE,并将其添加到fraud_accounts表中以将其标记为欺诈。INSERT INTO fraud_accounts VALUES (<id>);这会导致被标记的买家立即退出前 5 名!如果您点击“显示差异”,您会注意到被选中的买家被踢出,而下一个非欺诈性买家会自动进入前 5 名。
完成后,取消
SUBSCRIBE使用停止流,并关闭辅助浏览器窗口。
步骤 4. 提供正确结果
消除欺诈后,您现在可以将注意力转移到不同的操作用例:损益警报。
运营工作需要基于正确且一致的数据。在警告用户他们的支出远远超过他们的收入之前,您需要确保您的结果值得信赖——毕竟,我们谈论的是真金白银!
-
创建一个视图来跟踪每个拍卖行用户的销售和购买情况。
CREATE VIEW funds_movement AS
SELECT id, SUM(credits) as credits, SUM(debits) as debits
FROM (
SELECT seller as id, amount as credits, 0 as debits
FROM winning_bids
UNION ALL
SELECT buyer as id, 0 as credits, amount as debits
FROM winning_bids
)
GROUP BY id;如果你从这个角度看,你会得到很多结果,而且这些结果会随着新数据的产生而变化。这首先
SELECT使得很难判断用户资金是否真的累积起来。 -
为了进行仔细检查,您可以编写一个诊断查询,以便更容易发现结果是否正确且一致。例如,总贷方金额和总借方金额应始终相加。
SELECT SUM(credits), SUM(debits) FROM funds_movement;您也可以
SUBSCRIBE进行此查询,并观察拍卖结束时金额的变化。SUBSCRIBE TO (
SELECT SUM(credits), SUM(debits) FROM funds_movement
);这永远不会错,不是吗?
步骤 5. 清理
一旦您完成了拍卖行源的探索,请记住清理您的环境:
DROP SOURCE auction_house CASCADE;
DROP TABLE fraud_accounts;
下一步是什么?
要开始从外部系统(如 Kafka、MySQL 或 PostgreSQL)提取您自己的数据,请检查文档,然后在中导航至数据>源>新源 以创建您的第一个源。
价值观
-
让客户满意
-
我们以客户的成功来衡量自己的成功,并在客户实现雄心勃勃的目标时庆祝。这意味着关注客户最具挑战性的问题的根源,并以让他们既惊讶又高兴的方式解决这些问题。
-
-
掌控结果
-
积极地与团队一起为项目的成功负责。积极识别可能阻碍进展的潜在问题。当出现问题时,提出并实施解决方案,而不是等待。准备好参与并与他人妥协以推动成功,但如果需要解决问题,也要愿意承担经过计算的风险。循环往复,确保出现正确的结果。话虽如此,如果每个结果都是成功的,这可能是我们考虑不够周全的迹象。当赌注没有回报时,反思原因,这样你和你的团队才能继续进步。
-
-
赢得并提供信任
-
全球领先的企业使用我们的云产品为其关键业务流程提供支持,这种关系需要完全信任,相信我们将提供正确性、可用性和安全性。我们知道,我们必须在客户关系的各个方面赢得这种信任。从入职到生产,再到新用例等等,我们需要为客户提供保护、主动性和透明度。我们还必须将信任作为对同事的默认立场,创造一种支持性文化,让人们拥有掌控结果所需的权力和自主权,包括在事情没有按计划进行时通过学习来改进的机会。”
-
-
寻找数据,采取行动
-
Materialize 采用基于证据的方法来经营我们的业务,但我们也避免“分析瘫痪”。我们观察并质疑正在发生的事情,提出深入的问题,测试、分析数据并根据我们的结论采取行动。我们承认自己没有正确的数据来做出决策,并寻求利用我们确实拥有的数据找到最佳的基于证据的解决方案,以便深思熟虑地向前迈进。随着我们收到更多数据,我们会改进我们的答案和行动,以掌握结果。
-
-
坦诚相待
-
发展历程
2013
Naiad:一种及时数据流系统论文发表
Materialize 联合创始人 Frank McSherry 和他的同事在微软研究院工作期间在一篇论文中首次分享了他们关于 Timely Dataflow 的工作。
2015
Rust 中的及时数据流
弗兰克 (Frank) 开始用 Rust 编写及时数据流的开源项目,Rust 是 Materialize 的基础构建块。
2019 年 1 月
公司成立
Materialize 由 Arjun Narayan 和 Frank McSherry 创立。
2019 年 2 月
A 轮
Lightspeed 850 万美元 A 轮融资,仍处于隐身阶段
2020 年 2 月
首次公开发布
Materialize 首次公开发布,作为可用源的单一二进制文件,以 Rust 构建。
2020 年 11 月
B 轮
Materialize 从 Kleiner Perkins 获得 3200 万美元 B 轮融资
2021 年 9 月
C 轮
Materialize 从 Redpoint 获得 6000 万美元 C 轮融资
2022 年 10 月
云平台
Materialize 将单个二进制文件解绑到云原生分布式系统中,以解锁下一阶段的规模。
联合创始人和高管

领导团队

最佳支持

Materialize 是一种云操作数据存储,它以数据仓库的便捷性提供流式传输速度。借助 Materialize,组织可以使用 SQL 来转换、交付和处理快速变化的数据。
此快速入门将帮助您在几分钟内启动并运行,且没有任何依赖关系,因此您可以亲身体验操作数据存储的超能力:
-
交互性:从索引的仓库关系和派生结果中获取即时响应。
-
新鲜度:观察结果随着您输入的变化而立即发生变化。
-
一致性:结果始终正确;绝不会暂时出错。
先决条件
一个 Materialize 账户。如果您没有账户,可以。
步骤 0. 登录 Materialize
导航到并登录。默认情况下,您应该进入 SQL Shell。如果您已经登录,则可以在左侧菜单中访问 SQL Shell。
步骤 1. 采集流数据
作为拍卖行经营者,您希望在欺诈行为发生时立即发现,以便立即采取行动。最近,您一直在与作斗争——这些用户购买物品只是为了快速转售以牟利。
-
让我们首先启动内置的,这样您就有了一些可以使用的数据。
CREATE SOURCE auction_house
FROM LOAD GENERATOR AUCTION
(TICK INTERVAL '1s', AS OF 100000)
FOR ALL TABLES; -
使用以下命令来了解正在生成的数据:
SHOW SOURCES;name | type
------------------------+-----------------
accounts | subsource
auction_house | load-generator
auction_house_progress | progress
auctions | subsource
bids | subsource
organizations | subsource
users | subsource现在,您将重点关注
auctions和数据集。在您完成快速入门的过程中,bids数据将不断生成。 -
在继续下一步之前,请先了解一下您将要处理的数据:
SELECT * FROM auctions LIMIT 1;id | seller | item | end_time
----+--------+--------------------+----------------------------
1 | 1824 | Best Pizza in Town | 2023-09-10 21:24:54.838+00SELECT * FROM bids LIMIT 1;id | buyer | auction_id | amount | bid_time
----+-------+------------+--------+----------------------------
10 | 3844 | 1 | 59 | 2023-09-10 21:25:00.465+00
第 2 步:使用索引提高速度
运营工作需要在数据可用时立即进行交互访问。要识别潜在的拍卖翻转者,您需要跟踪每场已完成拍卖的获胜出价。
-
创建一个
auctions,将来自和的数据连接起来,以获取 每次拍卖的bids最高出价。amount``end_timeCREATE VIEW winning_bids AS
SELECT DISTINCT ON (auctions.id) bids.*, auctions.item, auctions.seller
FROM auctions, bids
-- Where all bids occurred during the auction
WHERE auctions.id = bids.auction_id
AND bids.bid_time < auctions.end_time
-- Where all auctions have completed
AND mz_now() >= auctions.end_time
ORDER BY auctions.id,
bids.amount DESC,
bids.bid_time,
bids.buyer;与其他 SQL 数据库一样,Materialize 中的视图只是嵌入
SELECT语句的别名;仅在调用视图时才会计算结果。 -
您可以直接查询视图,但目前这还不够令人印象深刻!查询视图会重新运行嵌入的语句,这在数据量增长时会产生一些成本。
SELECT * FROM winning_bids
WHERE item = 'Best Pizza in Town'
ORDER BY bid_time DESC;哎呀!在 Materialize 中,您可以使用来保持结果逐步更新并可立即访问。
-
接下来,尝试
winning_bids使用可以帮助优化点查找和连接等操作的列在视图上创建多个索引。CREATE INDEX wins_by_item ON winning_bids (item);
CREATE INDEX wins_by_bidder ON winning_bids (buyer);
CREATE INDEX wins_by_seller ON winning_bids (seller);这些索引将把结果保存
winning_bids在内存中,并像缓存一样工作——只是您不需要连接一个,也不必担心结果变得陈旧。 -
如果您现在尝试在点击其中一个索引(例如,使用点查找)时读取数据
winning_bids,事情应该会变得更加交互。SELECT * FROM winning_bids WHERE item = 'Best Pizza in Town' ORDER BY bid_time DESC;但要发现并应对欺诈行为,您不能依赖人工检查,对吗?您需要密切关注这些欺诈者。幸运的是,您在上一步中创建的索引也使连接更具交互性(就像在其他数据库中一样)!
-
创建一个视图,检测用户何时作为竞标者赢得拍卖,然后被识别为以更高价格出售某件物品的卖家。
CREATE VIEW fraud_activity AS
SELECT w2.seller,
w2.item AS seller_item,
w2.amount AS seller_amount,
w1.item buyer_item,
w1.amount buyer_amount
FROM winning_bids w1,
winning_bids w2
-- Identified as a buyer and seller for any two auctions
WHERE w1.buyer = w2.seller
-- For the same item
AND w1.item = w2.item
-- Tries to sell at a higher price
AND w2.amount > w1.amount;啊哈!现在,您可以根据此视图的结果实时捕捉任何拍卖翻转者。
SELECT * FROM fraud_activity LIMIT 100;
步骤3.查看结果变化!
运营工作需要根据最新数据进行处理。一旦您的数据发生变化,Materialize 就会做出反应。让我们 通过手动将某些帐户标记为欺诈并实时观察结果变化来验证这一点是否真的发生了!
-
创建一个,让您可以手动标记欺诈性账户。
CREATE TABLE fraud_accounts (id bigint); -
在新的浏览器窗口中,与此窗口并排,导航到,然后弹出另一个 SQL Shell。
-
为了查看结果随时间的变化,让我们
SUBSCRIBE进行一个查询,返回总体而言排名前 5 位的拍卖获胜者。SUBSCRIBE TO (
SELECT buyer, count(*)
FROM winning_bids
WHERE buyer NOT IN (SELECT id FROM fraud_accounts)
GROUP BY buyer
ORDER BY 2 DESC LIMIT 5
);您可以密切关注结果,但目前结果可能不会有太大变化。您将在下一步中修复此问题!
-
从运行的窗口中维护的列表中选择一个买家
SUBSCRIBE,并将其添加到fraud_accounts表中以将其标记为欺诈。INSERT INTO fraud_accounts VALUES (<id>);这会导致被标记的买家立即退出前 5 名!如果您点击“显示差异”,您会注意到被选中的买家被踢出,而下一个非欺诈性买家会自动进入前 5 名。
完成后,取消
SUBSCRIBE使用停止流,并关闭辅助浏览器窗口。
步骤 4. 提供正确结果
消除欺诈后,您现在可以将注意力转移到不同的操作用例:损益警报。
运营工作需要基于正确且一致的数据。在警告用户他们的支出远远超过他们的收入之前,您需要确保您的结果值得信赖——毕竟,我们谈论的是真金白银!
-
创建一个视图来跟踪每个拍卖行用户的销售和购买情况。
CREATE VIEW funds_movement AS
SELECT id, SUM(credits) as credits, SUM(debits) as debits
FROM (
SELECT seller as id, amount as credits, 0 as debits
FROM winning_bids
UNION ALL
SELECT buyer as id, 0 as credits, amount as debits
FROM winning_bids
)
GROUP BY id;如果你从这个角度看,你会得到很多结果,而且这些结果会随着新数据的产生而变化。这首先
SELECT使得很难判断用户资金是否真的累积起来。 -
为了进行仔细检查,您可以编写一个诊断查询,以便更容易发现结果是否正确且一致。例如,总贷方金额和总借方金额应始终相加。
SELECT SUM(credits), SUM(debits) FROM funds_movement;您也可以
SUBSCRIBE进行此查询,并观察拍卖结束时金额的变化。SUBSCRIBE TO (
SELECT SUM(credits), SUM(debits) FROM funds_movement
);这永远不会错,不是吗?
步骤 5. 清理
一旦您完成了拍卖行源的探索,请记住清理您的环境:
DROP SOURCE auction_house CASCADE;
DROP TABLE fraud_accounts;
下一步是什么?
要开始从外部系统(如 Kafka、MySQL 或 PostgreSQL)提取您自己的数据,请检查文档,然后在中导航至数据>源>新源 以创建您的第一个源。
价值观
-
让客户满意
-
我们以客户的成功来衡量自己的成功,并在客户实现雄心勃勃的目标时庆祝。这意味着关注客户最具挑战性的问题的根源,并以让他们既惊讶又高兴的方式解决这些问题。
-
-
掌控结果
-
积极地与团队一起为项目的成功负责。积极识别可能阻碍进展的潜在问题。当出现问题时,提出并实施解决方案,而不是等待。准备好参与并与他人妥协以推动成功,但如果需要解决问题,也要愿意承担经过计算的风险。循环往复,确保出现正确的结果。话虽如此,如果每个结果都是成功的,这可能是我们考虑不够周全的迹象。当赌注没有回报时,反思原因,这样你和你的团队才能继续进步。
-
-
赢得并提供信任
-
全球领先的企业使用我们的云产品为其关键业务流程提供支持,这种关系需要完全信任,相信我们将提供正确性、可用性和安全性。我们知道,我们必须在客户关系的各个方面赢得这种信任。从入职到生产,再到新用例等等,我们需要为客户提供保护、主动性和透明度。我们还必须将信任作为对同事的默认立场,创造一种支持性文化,让人们拥有掌控结果所需的权力和自主权,包括在事情没有按计划进行时通过学习来改进的机会。”
-
-
寻找数据,采取行动
-
Materialize 采用基于证据的方法来经营我们的业务,但我们也避免“分析瘫痪”。我们观察并质疑正在发生的事情,提出深入的问题,测试、分析数据并根据我们的结论采取行动。我们承认自己没有正确的数据来做出决策,并寻求利用我们确实拥有的数据找到最佳的基于证据的解决方案,以便深思熟虑地向前迈进。随着我们收到更多数据,我们会改进我们的答案和行动,以掌握结果。
-
-
坦诚相待
-
发展历程
2013
Naiad:一种及时数据流系统论文发表
Materialize 联合创始人 Frank McSherry 和他的同事在微软研究院工作期间在一篇论文中首次分享了他们关于 Timely Dataflow 的工作。
2015
Rust 中的及时数据流
弗兰克 (Frank) 开始用 Rust 编写及时数据流的开源项目,Rust 是 Materialize 的基础构建块。
2019 年 1 月
公司成立
Materialize 由 Arjun Narayan 和 Frank McSherry 创立。
2019 年 2 月
A 轮
Lightspeed 850 万美元 A 轮融资,仍处于隐身阶段
2020 年 2 月
首次公开发布
Materialize 首次公开发布,作为可用源的单一二进制文件,以 Rust 构建。
2020 年 11 月
B 轮
Materialize 从 Kleiner Perkins 获得 3200 万美元 B 轮融资
2021 年 9 月
C 轮
Materialize 从 Redpoint 获得 6000 万美元 C 轮融资
2022 年 10 月
云平台
Materialize 将单个二进制文件解绑到云原生分布式系统中,以解锁下一阶段的规模。
联合创始人和高管
领导团队
最佳支持

