
什么是大语言模型?
大型语言模型(LLM)是一类拥有数千亿甚至更多参数的语言处理系统,它们通过分析海量文本数据来学习语言的模式。这些模型,比如GPT-3、PaLM、Galactica和LaMA,都是基于Transformer架构构建的,该架构通过多层的多头注意力机制来处理信息。尽管LLM在架构上与小型语言模型相似,都采用Transformer和语言建模作为预训练目标,但LLM在模型规模、训练数据量和计算资源上都有显著的扩展。
这些大型模型能够更深入地理解自然语言,并能够根据上下文生成高质量的文本内容。它们的性能提升在很大程度上可以通过规模定律来解释,即随着模型规模的大幅增加,性能也会相应提高。然而,规模定律也表明,有些能力,比如上下文学习,是难以预测的,只有在模型达到一定的规模后才能显现出来。
一、NLP到大型语言模型的进阶历程
回顾自然语言处理(NLP)领域的发展,可以将其划分为五个主要阶段:规则驱动、统计机器学习、深度学习、预训练和大型语言模型。以机器翻译为例,结合这些阶段的特点、技术演变和数据使用的变化。
- 规则驱动阶段(1956年至1992年):在这一时期,机器翻译系统主要依赖于人工编写的规则。研究人员从数据中提取知识,形成规则,然后编程让机器执行这些规则来完成特定的翻译任务。
- 统计机器学习阶段(1993年至2012年):这一阶段的特点是机器翻译系统开始由语言模型和翻译模型组成,与现代的GPT-3.5技术有相似之处。这一时期的主要变化是从人工提取知识转变为机器自动从数据中学习。关键技术包括支持向量机(SVM)、隐马尔可夫模型(HMM)、最大熵模型(MaxEnt)、条件随机场(CRF)和语言模型(LM),当时人工标注的数据量大约在百万级别。
- 深度学习阶段(2013年至2018年):在这一时期,模型的发展从离散的匹配转变为连续的嵌入(embedding)匹配,模型规模变得更大。这一阶段的典型技术包括编码器-解码器架构、长短时记忆网络(LSTM)和注意力机制(Attention),标注数据量提升至千万级别。
- 预训练阶段(2018年至2022年):这一阶段的最大变化是引入了自监督学习,这是张俊林认为NLP领域最杰出的贡献之一。它将可利用的数据从标注数据扩展到了非标注数据。系统分为预训练和微调两个阶段,预训练数据量扩大了3到5倍。这一阶段的典型技术包括编码器-解码器架构、Transformer和注意力机制。
二、大语言模型与AI大模型
大语言模型是AI大模型的一个类别,属于语言大模型(NLP)范畴。
AI大模型可以大致分为三类:
- 语言大模型(NLP),例如:ChatGPT 系列(OpenAI)、Bard(Google)、文心一言(百度);开源大模型中有Meta 开源的 LLaMA、ChatGLM – 6B、Yi-34B-Chat等。
- 视觉大模型(CV),例如:VIT 系列(Google)、文心UFO、华为盘古 CV、INTERN(商汤)等。
- 多模态大模型,例如:谷歌Gemini、DALL-E(OpenAI)、Midjourney等。
三、大语言模型的发展
2018年,随着谷歌 BERT(Bidirectional Encoder Representations from Transformers)的发布,预训练模型迎来了一个里程碑。BERT通过预先训练大规模语料库,使得模型能够理解更为复杂的语境和语义关系。这一技术创新使得大语言模型在各种自然语言处理任务中表现出色,为自动问答、机器翻译等应用打开了新的可能性。
2022年11月30日,GPT-3的发布标志着AI领域的重大突破,它包含1750亿个参数,是GPT-2的100倍之多,比之前最大的同类NLP模型要多10倍。GPT-3的训练数据集十分庞大,包括英语维基百科、数字化书籍和各种网页链接,几乎所有有文字记录的信息都被编码进了GPT-3模型中。这种深度和复杂性使得GPT-3能够高质量地完成诸多任务,包括但不限于答题、翻译、写文章,甚至是数学计算和编写代码。
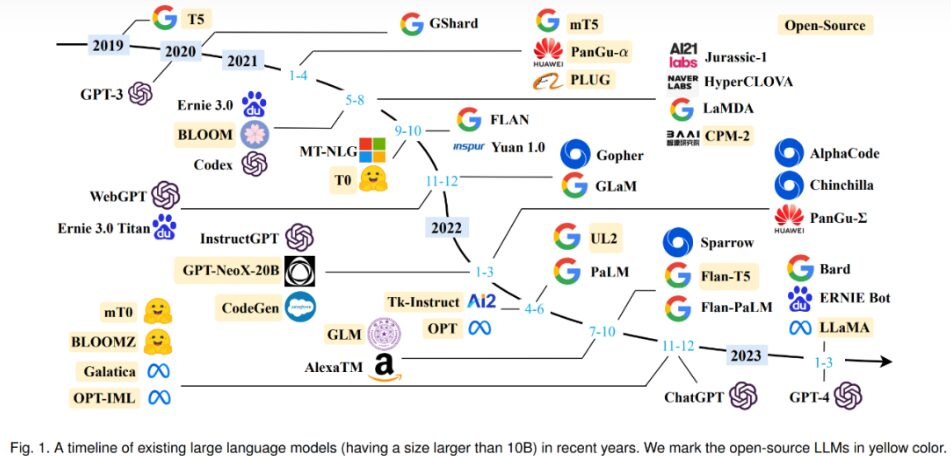
当以ChatGpt为代表的语言模型开始广受认可时,许多性能强大的LLM只能通过 大语言模型API接口(如OpenAI API)访问,仅有特定的人或实验室具备研究和开发此类模型的能力,由此促进了开源大语言模型的发展。
2023年2月24日,Meta推出了LLaMA模型。LLaMA是最早发布的开源且高质量的预训练LLM之一。但 LLaMA 并非单一模型,而是包含多个LLM 的套件,其模型规模从 70 亿到 650 亿个参数不等。这些模型在性能和推理效率之间作了不同的权衡。尽管 LLaMA 不能商用(仅限于研究),但作为一个具有重要影响力的提案,它从多个方面推动了开源LLM的研究。
 ## 四、大语言模型核心问题:偏差和局限性
## 四、大语言模型核心问题:偏差和局限性
大语言模型偏差和局限性是自然语言处理(NLP)领域正在进行的研究。虽然大语言模型在生成类人文本方面表现出了卓越的能力,但他们很容易继承和放大训练数据中存在的偏见。这可能表现为对不同人口统计数据的不公平待遇,例如基于种族、性别、语言和文化群体的统计数据。此外,这些模型通常面临事实准确性的限制。研究和缓解这些偏见和限制对于人工智能在不同社会和专业领域的道德发展和应用至关重要。
五、大语言模型国内外开源项目模型清单
以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例,常见底座模型细节概览:
| 底座 | 包含模型 | 模型参数大小 | 训练token数 | 训练最大长度 | 是否可商用 |
|---|---|---|---|---|---|
| ChatGLM | ChatGLM/2/3 Base&Chat | 6B | 1T/1.4 | 2K/32K | 可商用 |
| LLaMA | LLaMA/2/3 Base&Chat | 7B/8B/13B/33B/70B | 1T/2T | 2k/4k | 部分可商用 |
| Baichuan | Baichuan/2 Base&Chat | 7B/13B | 1.2T/1.4T | 4k | 可商用 |
| Qwen | Qwen/1.5 Base&Chat | 7B/14B/72B/110B | 2.2T/3T | 8k/32k | 可商用 |
| BLOOM | BLOOM | 1B/7B/176B-MT | 1.5T | 2k | 可商用 |
| Aquila | Aquila/2 Base/Chat | 7B/34B | – | 2k | 可商用 |
| InternLM | InternLM/2 Base/Chat/Code | 7B/20B | – | 200k | 可商用 |
| Mixtral | Base&Chat | 8x7B | – | 32k | 可商用 |
| Yi | Base&Chat | 6B/9B/34B | 3T | 200k | 可商用 |
| DeepSeek | Base&Chat | 1.3B/7B/33B/67B | – | 4k | 可商用 |