

Azure OpenAI API快速入门教程

去年,我们推出了 Kandinsky 2.0 ,这是第一个基于扩散的多语言文本图像生成模型,可以从俄语文本生成图像。随后又推出了新版本 Kandinsky 2.1 和 Kandinsky 2.2 ,它们的质量和功能与 2.0 版本有显著不同,是我们团队在实现更高质量生成方面的重要里程碑。
但无限不是极限 ,总有成长的空间。与图像或文本生成相关的科学论文和工程解决方案的数量正在增加,新的生成问题陈述正在出现——现在包括视频、3D 对象和(甚至)4D 生成。生成学习领域在信息领域占据着越来越多的空间。最近,我们的团队推出了基于基本图像到文本生成模型生成动画视频的 Deforum-Kandinsky 方法,以及基于 Kandinsky Inpainting 模型创建放大/缩小视频的方法。与此发布同步,我们还推出了俄罗斯第一个端到端基于文本的视频生成模型 Kandinsky Video 。
尽管如此,从文本生成图像的任务仍然对研究人员构成严峻挑战。这一任务每年都变得越来越困难,因为如今的图像需要达到前所未有的逼真程度,以满足最挑剔、最机智的用户的需求。
因此,在我们发布第一个传播模型一年后,我们推出了基于文本的图像生成模型的新版本——Kandinsky 3.0! 这是我们团队长期工作的成果,与 Kandinsky 2.1 和 2.2 版本的开发同时进行。我们在架构选择上进行了大量实验,并在数据方面做了很多工作,以提高文本理解和生成质量,并使架构本身更简单、更简洁。我们还使我们的模型更加“本土化”:它更好地驾驭了俄罗斯文化领域。
在本文中,我们将简要描述新架构的关键点、其训练过程、处理数据的策略,当然,还将根据代际示例展示我们模型的能力。
Kandinsky 3.0 是一个用于基于文本的图像生成的扩散模型(与 Kandinsky 2.X 中的所有模型一样)。训练这种模型的目的是学习重建在前向扩散过程中有噪声的真实图像。在训练 Kandinsky 3.0 时,我们放弃了以前版本中使用的两阶段生成概念。让我提醒您两阶段生成的工作原理:
在 Kandinsky 3.0 中,图像生成直接通过编码的文本标记完成。这种方法简化了训练,因为现在只需要训练模型的一部分(即解码器)。这种方法还大大提高了文本理解能力,因为现在我们可以使用在大量高质量文本数据上训练的强大语言模型,而不是 CLIP 文本编码器,后者是在与自然语言截然不同的原始文本上训练的。
除了更新文本编码方法外,我们还对负责去除图片噪声的 U-Net 架构进行了大规模研究。主要的难题是哪种类型的层将包含大部分网络参数:Transformer 层还是卷积层。在对大量数据进行训练时,Transformer 在图像上的表现更好,但几乎所有扩散模型的 U-Net 架构都是以卷积为主的。为了解决这个难题,我们分析了不同的架构,并为自己指出了以下模型:
CoAtNet 是一种结合了卷积和注意力模块的架构。其主要思想是,在初始阶段,图像应通过局部卷积进行处理,而其已压缩的表示则通过提供图像元素全局交互的转换层进行处理。
MaxViT 是一种几乎完全基于变压器块的架构,但通过降低自注意力的二次复杂度来适应处理图像。
使用分类模型的想法受到这样一个事实的启发:许多好的架构解决方案都取自在 ImageNet 基准上表现出色的模型。然而,我们的实验表明,质量迁移的效果并不明确。在分类任务上表现最好的 MaxVit 架构在将其转换为 U-Net 后,在生成任务上的表现并不理想。在研究了上述所有架构后,我们决定将 ResNet-50 块作为基本的 U-Net 块,并借用 BigGan 的论文中的想法,为其添加了另一个具有 3×3 核心的卷积层。
最终,康定斯基3.0建筑由三个主要部分组成:
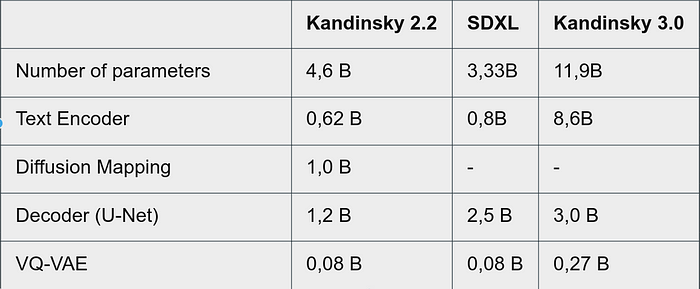
训练使用了从互联网上收集的许多文本-图片对。这些数据经过了众多筛选:图像美观度、图像与文本匹配、重复、分辨率和长宽比。与 Kandinsky 2.2 相比,我们扩展了所使用的数据集,用新数据丰富了数据集,添加了俄语实体,并添加了使用最先进的多模态模型生成描述的图像。
训练过程分为几个阶段,这使得我们可以使用更多的训练数据,以及生成不同大小的图像。
为了比较模型,我们收集了 21 个类别的 2100 个提示,并比较了不同的 Kandinsky 3.0 权重以选出最佳的提示。为此,我们进行了三次并排运行,使用了 28 个标记。然后,当选择了 Kandinsky 3.0 模型的最佳版本时,与 Kandinsky 2.2 模型进行了并排比较。12 个人参与了这项研究,总共投票 24,800 次。为此,他们开发了一个机器人,可以显示 2,100 对图像中的一对。每个人根据两个标准选择最佳图像:
对所有类别的视觉质量和文本理解进行了总体比较,并对每个类别进行了单独比较:
以下是与康定斯基 3.0 相比的流行模型代示例:
我们的团队为 Fusion Brain 网站开发了修复/外绘模型,借助该模型,您可以编辑图像:更改图像内必要的对象和整个区域( 修复方法 ),或通过外绘方法将其扩展到巨大的全景图,添加新的细节。修复任务比标准生成复杂得多,因为必须学习不仅从文本生成模型,还要使用图像上下文来生成模型。
为了训练模型的修复部分,我们使用了 GLIDE 方法,该方法之前已在 Kandinsky 系列模型以及稳定扩散系列模型中实现:U-Net 的输入层经过修改,以便输入可以额外接受图像潜在和蒙版。因此,U-Net 最多接受 9 个通道作为输入:4 个用于原始潜在,4 个用于图像潜在,一个额外的通道用于蒙版。从修改的角度来看,进一步的训练与标准扩散模型的训练并无不同
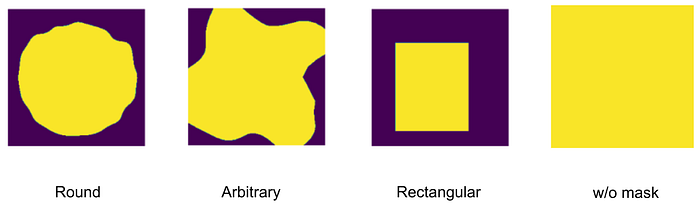
该任务的一个重要特征是如何生成蒙版以及训练时使用哪些文本。用户可以使用画笔绘制蒙版,也可以通过外绘绘制新图像。为了考虑用户的工作方式,我们在训练期间创建了模仿其行为的特殊蒙版:任意形状的画笔绘制蒙版、对象蒙版和图像填充
因此,该模型可以很好地应对图像替换和图像增强(参见示例)












随着 Kandinsky 3.0 的推出,我们还更新了 Deforum,这是一项允许我们通过图像到图像的方法生成动画视频的技术。
将框架适配到新模型的主要困难在于扩散过程中噪声添加方式的不同:Kandinsky 2.2 按照线性时间表添加噪声(上图),而 Kandinsky 3.0 按照余弦时间表添加噪声(下图)。这个特性需要大量的实验才能适应。
我们推出了新的基于文本的图像生成架构——Kandinsky 3.0。与之前的模型相比,我们对文本和俄罗斯文化的理解有了显著提高,我们一定会继续朝这个方向努力。在科学方面,我们的计划包括创建另一个新一代模型,它将在人工智能领域崭露头角。
人工智能和生成学习领域为进一步发展开辟了广阔的空间,谁知道呢,也许在不久的将来,像我们的康定斯基这样的模型会形成一个新的现实——与现在的现实没有太大区别。这些变化对人类的影响很难判断,而且有陷入许多可疑猜测的风险。作为研究人员,我们要警惕过于悲观和乐观的预测。但我们可以肯定的是,这种发展无论如何都会非常有趣,需要改变我们对周围许多事物的看法。我们全人类还没有意识到生成学习的全部力量。请继续关注,以免错过世界将如何改变,包括通过我们的努力!
文章转载自:Kandinsky 3.0 — a new model for generating images from text







