Perplexity的 pplx-api详细介绍
文章目录
pplx-api 是 Perplexity AI 推出的高性能开源大语言模型(LLM)接口,支持 Mistral 7B、Llama2 13B、Code Llama 34B、Llama2 70B 等先进模型。它提供极简的使用体验,开发者无需深入了解 C++/CUDA 或拥有 GPU,即可通过 REST API 快速接入。其推理系统经过优化,延迟极低,比 Replicate 低 2.9 倍,比 Anyscale 低 3.1 倍。pplx-api 基于 AWS 的 A100 GPU 和 NVIDIA 的 TensorRT-LLM 构建,具备强大的可扩展性。目前处于公开测试阶段,Perplexity Pro 订阅用户可免费使用。
Perplexity的 pplx-api 提供:
- 易于使用:开发人员可以使用现成的最先进的开源模型,并通过熟悉的 REST API 在几分钟内开始使用。
- 极快的推理:我们精心设计的推理系统非常高效,延迟比 Replicate 低2.9 倍,延迟比 Anyscale 低3.1 倍。
- 经过实战检验的基础设施:pplx-api 被证明是可靠的,在我们的Perplexity 答案引擎和我们的实验室游乐场中提供生产级流量服务。
- 开源 LLM 的一站式服务:我们的团队致力于在新开源模型发布时及时添加它们。例如,我们在发布后的几个小时内就添加了 Llama 和 Mistral 模型,而无需预发布访问权限。
pplx-api 的优点
易于使用
LLM 部署和推理需要进行大量的基础设施建设,才能使模型服务既高效又经济高效。开发人员可以开箱即用我们的 API,无需深入了解 C++/CUDA 或访问 GPU,同时仍能享受最先进的性能。我们的 LLM 推理还抽象了管理您自己的硬件的复杂性和必要性,进一步提高了您的易用性。
极快的推理
Perplexity 的 LLM API 经过精心设计和优化,可实现快速推理。为了实现这一点,我们围绕 NVIDIA 的TensortRT-LLM构建了专有的 LLM 推理基础设施,该基础设施由 AWS 提供的 A100 GPU 提供。在pplx-api 基础设施概述部分了解更多信息。因此,pplx-api 是市面上最快的 Llama 和 Mistral API 之一。
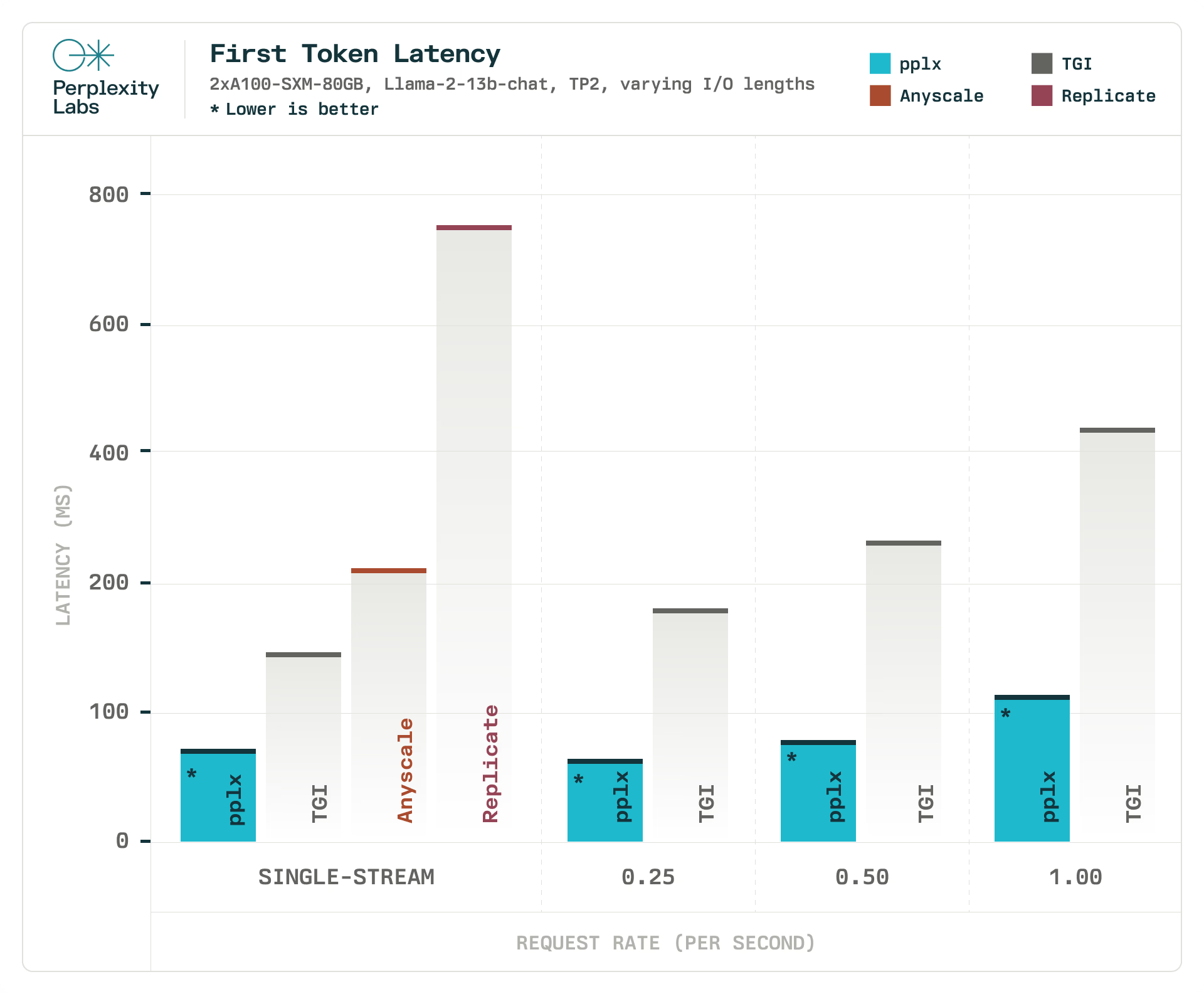
为了与现有解决方案进行基准测试,我们将 pplx-api 的延迟与其他 LLM 推理库进行了比较。在我们的实验中,与文本生成推理 (TGI) 相比, pplx-api 实现了高达2.92 倍的整体延迟,以及高达4.35 倍的初始响应延迟。在这个实验中,我们使用在两个 GPU 上分片的 Llama-2-13B-chat 模型,比较了 TGI 和 Perplexity 在 2 个 A100 GPU 上对单流和服务器场景的推理。对于单流场景,服务器会一个接一个地处理请求。在服务器场景中,客户端根据泊松分布发送请求,请求速率各不相同,以模拟变化的负载。对于请求速率,我们执行一个小的扫描,最高可达 1 个请求/秒,这是 TGI 维持的最大吞吐量。我们使用具有各种输入和输出令牌长度的真实数据来模拟生产行为。请求平均约有 700 个输入令牌和 550 个输出令牌。
使用相同的输入并发送单个请求流,我们还测量了同一模型的 Replicate 和 Anyscale API 的平均延迟,以收集与其他现有 API 的性能基准。
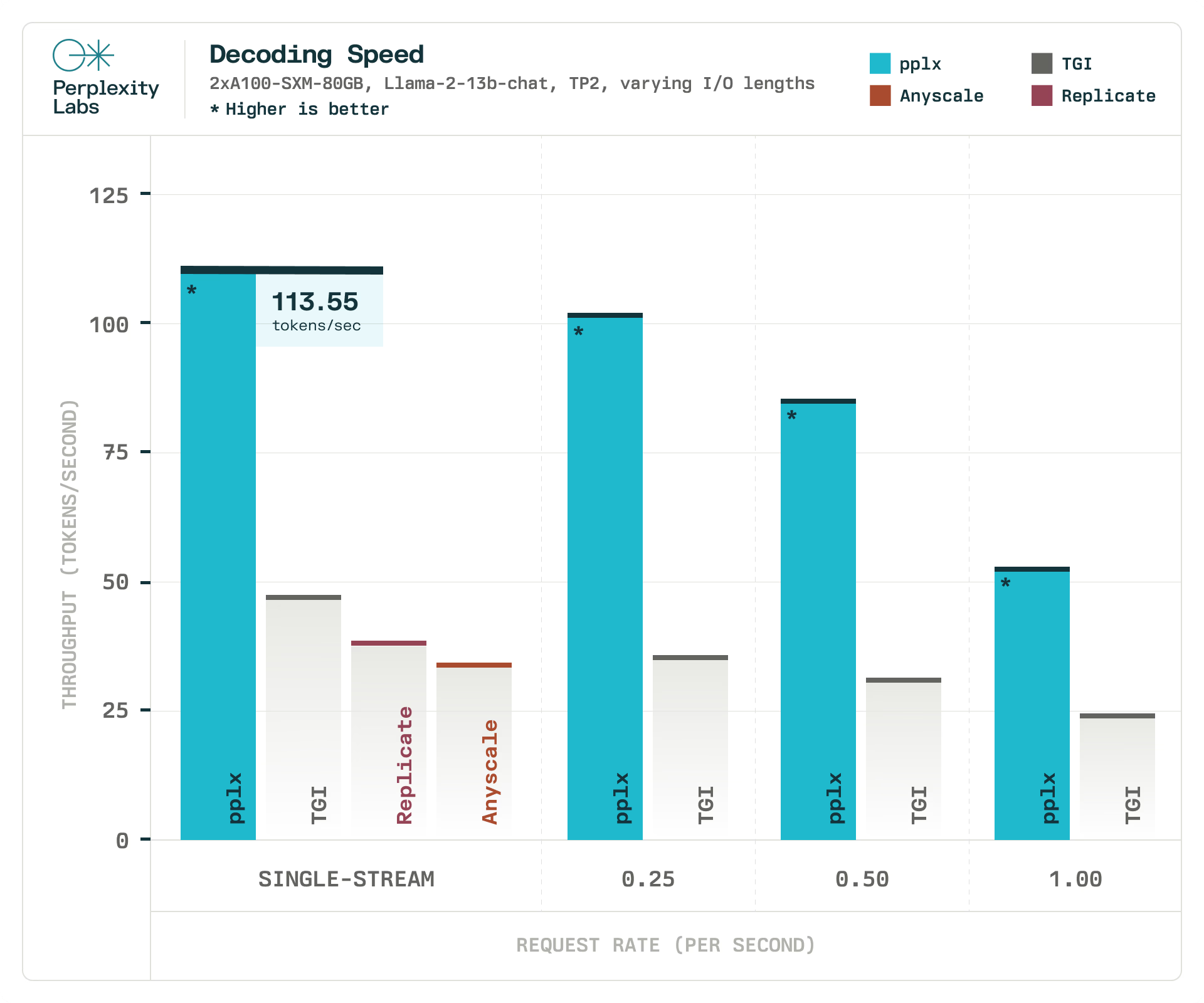
使用相同的实验设置,我们将 pplx-api 的最大吞吐量与 TGI 进行了比较,将解码速度作为延迟约束。在我们的实验中,pplx-api 处理令牌的速度比 TGI 快1.90 倍到 6.75 倍,而 TGI 完全无法满足我们更严格的延迟约束(每秒60和80 个 令牌)。我们在与评估 pplx-api 相同的硬件和负载条件下评估 TGI。由于我们无法控制它们的硬件和负载因素,因此无法将此指标与 Replicate 和 Anyscale 进行比较。
作为参考,人类的平均阅读速度为 5 个令牌/秒,这意味着 pplx-api能够以比人类阅读速度更快的速度提供服务。
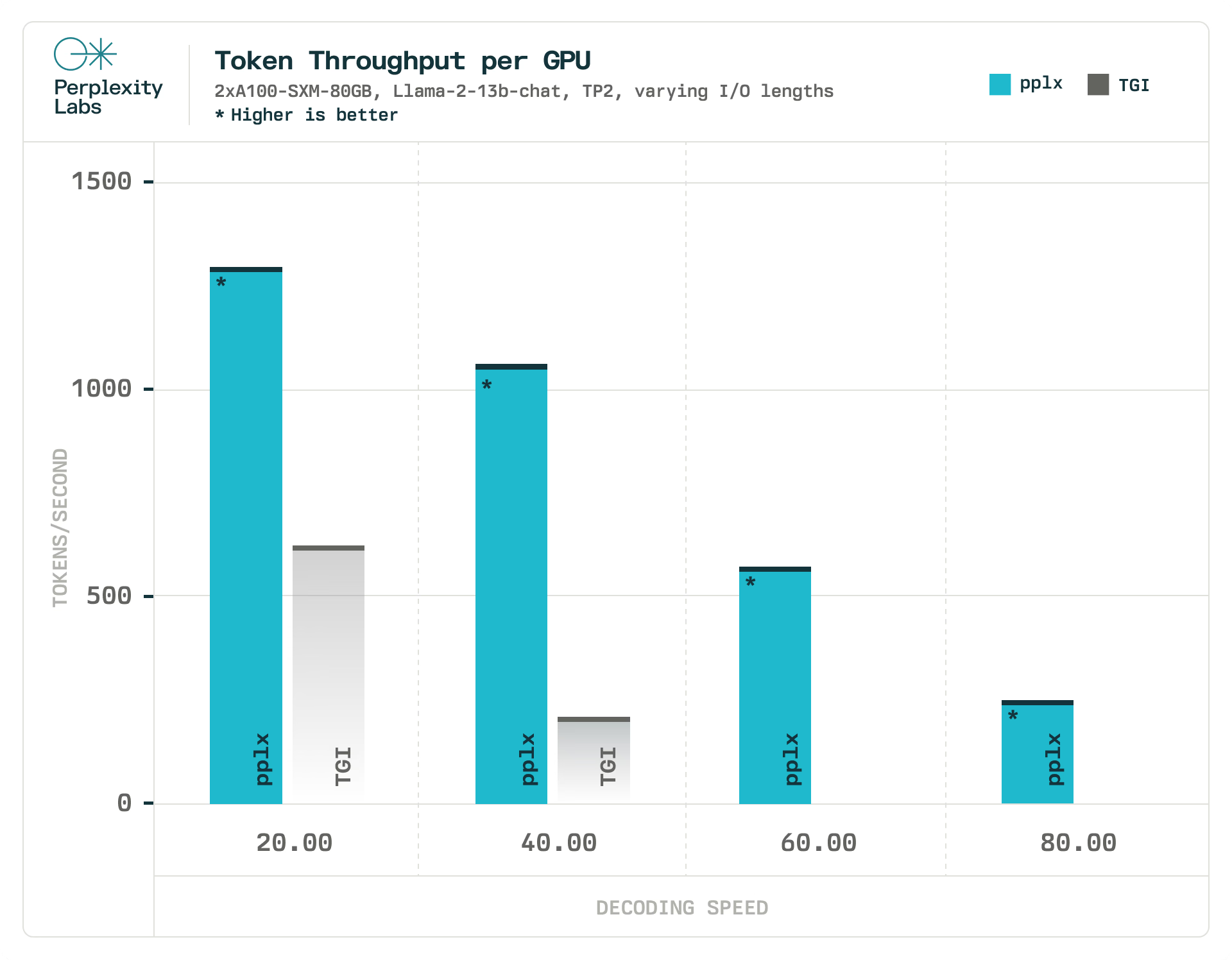
pplx-api 基础设施概述
要实现这些延迟数字需要最先进的软件和硬件的结合。
由 NVIDIA A100 GPU 提供支持的AWS p4d 实例为扩展具有一流时钟速度的 GPU 奠定了最具成本效益和最可靠的选择基础。
为了让软件充分利用此硬件,我们运行 NVIDIA 的 TensorRT-LLM,这是一个加速和优化 LLM 推理的开源库。TensorRT-LLM 封装了 TensorRT 的深度学习编译器,并包含为 FlashAttention 和掩蔽多头注意力 (MHA) 的尖端实现而制作的最新优化内核,用于 LLM 模型执行的上下文和生成阶段。
从这里开始,AWS 的主干及其与 Kubernetes 的强大集成使我们能够弹性扩展到数百个 GPU 以上,并最大限度地减少停机时间和网络开销。
用例:生产中的 API
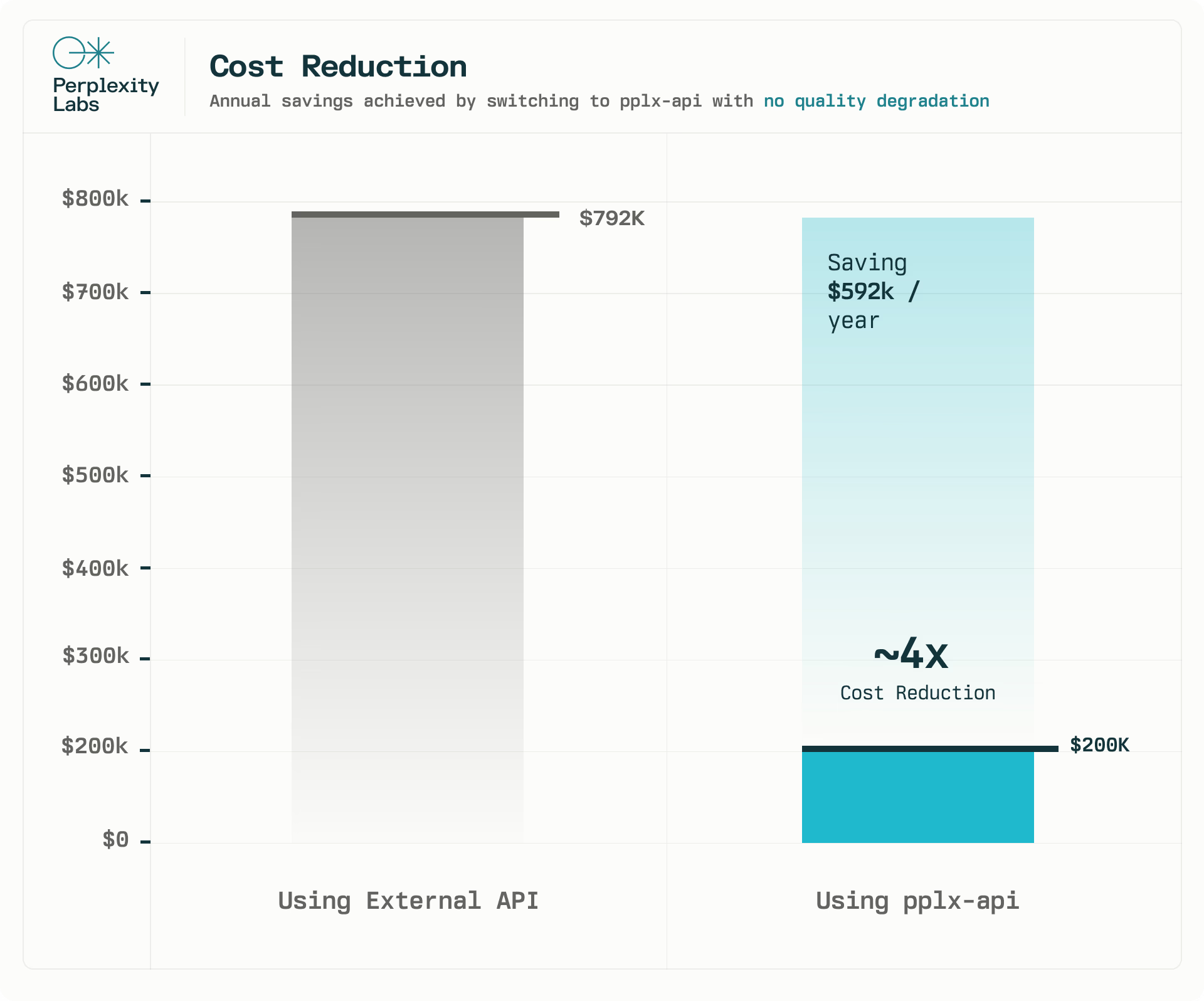
pplx-api 困惑:降低成本和提高可靠性
我们的 API 已经为 Perplexity 的核心产品功能之一提供支持。只需将一个功能从外部 API 切换到 pplx-api,每年即可节省 62 万美元,成本大约降低了4 倍。我们运行了 A/B 测试并监控了基础设施指标,以确保质量不会下降。在 2 周的时间里,我们在 A/B 测试中没有观察到统计学上的显著差异。此外,pplx-api 可以承受每天超过一百万个请求的负载,每天总共处理近 10 亿个令牌。
这次初步探索的结果非常令人鼓舞,我们期待 pplx-api 能随着时间的推移为我们的更多产品功能提供支持。
Perplexity Labs 中的 pplx-api:开源推理生态系统
我们还使用 pplx-api 为Perplexity Labs提供支持,这是我们的模型游乐场,为各种开源模型提供服务。
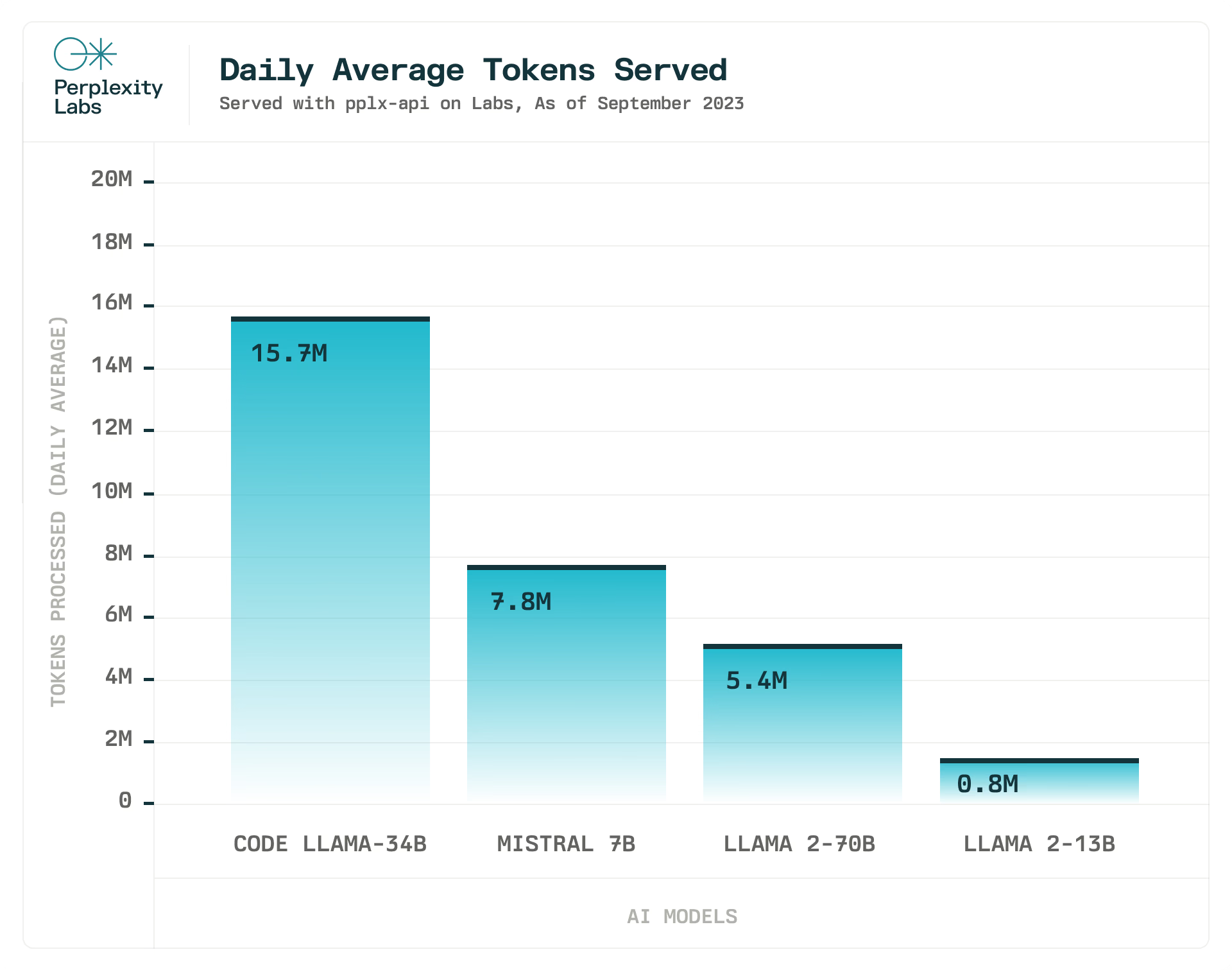
Perplexity团队致力于提供最新的先进开源 LLM。我们在 Mistral 7B、Code Llama 34b 和所有 Llama 2 模型发布后几个小时内就将它们集成在一起,并计划在推出更多功能更强大的开源 LLM 时这样做。
开始使用 Perplexity 的 AI API
您可以使用 HTTPS 请求访问 pplx-api REST API。pplx-api 身份验证涉及以下步骤:
- 通过Perplexity 账户设置页面生成 API 密钥。API 密钥是一个长期有效的访问令牌,可以一直使用,直到手动刷新或删除为止。
Authorization在每个 pplx-api 请求的标头中将 API 密钥作为承载令牌发送。
以下示例中,PERPLEXITY_API_KEY是使用上述指令生成的与密钥绑定的环境变量。CURL 用于提交聊天完成请求。
curl -X POST \
--url https://api.perplexity.ai/chat/completions \
--header 'accept: application/json' \
--header 'content-type: application/json' \
--header "Authorization: Bearer ${PERPLEXITY_API_KEY}" \
--data '{
"model": "mistral-7b-instruct",
"stream": false,
"max_tokens": 1024,
"frequency_penalty": 1,
"temperature": 0.0,
"messages": [
{
"role": "system",
"content": "Be precise and concise in your responses."
},
{
"role": "user",
"content": "How many stars are there in our galaxy?"
}
]
}'得到以下响应,content-type: application/json
{
"id": "3fbf9a47-ac23-446d-8c6b-d911e190a898",
"model": "mistral-7b-instruct",
"object": "chat.completion",
"created": 1765322,
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": " The Milky Way galaxy contains an estimated 200-400 billion stars.."
},
"delta": {
"role": "assistant",
"content": " The Milky Way galaxy contains an estimated 200-400 billion stars.."
}
}
],
"usage": {
"prompt_tokens": 40,
"completion_tokens": 22,
"total_tokens": 62
}
}以下是 Python 调用的示例:
from openai import OpenAI
YOUR_API_KEY = "INSERT API KEY HERE"
messages = [
{
"role": "system",
"content": (
"You are an artificial intelligence assistant and you need to "
"engage in a helpful, detailed, polite conversation with a user."
),
},
{
"role": "user",
"content": (
"Count to 100, with a comma between each number and no newlines. "
"E.g., 1, 2, 3, ..."
),
},
]
client = OpenAI(api_key=YOUR_API_KEY, base_url="https://api.perplexity.ai")
# demo chat completion without streaming
response = client.chat.completions.create(
model="mistral-7b-instruct",
messages=messages,
)
print(response)
# demo chat completion with streaming
response_stream = client.chat.completions.create(
model="mistral-7b-instruct",
messages=messages,
stream=True,
)
for response in response_stream:
print(response)总结
Perplexity目前支持Mistral 7B、Llama 13B、Code Llama 34B、Llama 70B,并且 API 方便地与 OpenAI 客户端兼容,以便于轻松与现有应用程序集成。
最新文章
- 小红书AI文章风格转换:违禁词替换与内容优化技巧指南
- REST API 设计:过滤、排序和分页
- 认证与授权API对比:OAuth vs JWT
- 如何获取 Coze开放平台 API 密钥(分步指南)
- 首次构建 API 时的 10 个错误状态代码以及如何修复它们
- 当中医遇上AI:贝业斯如何革新中医诊断
- 如何使用OAuth作用域为您的API添加细粒度权限
- LLM API:2025年的应用场景、工具与最佳实践 – Orq.ai
- API密钥——什么是API Key 密钥?
- 华为 UCM 推理技术加持:2025 工业设备秒级监控高并发 API 零门槛实战
- 使用JSON注入攻击API
- 思维链提示工程实战:如何通过API构建复杂推理的AI提示词系统