

如何使用Requests-OAuthlib实现OAuth认证

MLflow 是 Databricks(spark) 推出的面对端到端机器学习的生命周期管理工具,它有如下四方面的功能:
MLflow 独立于第三方机器学习库,可以跟任何机器学习库、任何语言结合使用,因为 MLflow 的所有功能都是通过 REST API 和 CLI 的方式调用的,为了调用更方便,还提供了针对 Python、R、和 Java 语言的 SDK。

安装:
pip install mlflowimport os
from mlflow import log_metric, log_param, log_artifact
if __name__ == "__main__":
# 1. 跟踪实验参数
log_param("param1", 5)
# 2. 跟踪实验指标;mlflow 会记录所有针对实验指标的更新过程,
log_metric("foo", 1)
log_metric("foo", 2)
log_metric("foo", 3)
# 3. 上传实验文件
with open("output.txt", 'w') as f:
f.write("hello world")
log_artifact("output.txt")把上面的文件保存成 main.py,执行:
python main.py在当前目录下会生成一个 mlflow 文件夹,类似这样子:
mlruns/
└── 0
├── 8ecf174e6ab3434d82b0c28463110dc9
│ ├── artifacts
│ │ └── output.txt
│ ├── meta.yaml
│ ├── metrics
│ │ └── foo
│ ├── params
│ │ └── param1
│ └── tags
│ ├── mlflow.source.git.commit
│ ├── mlflow.source.name
│ ├── mlflow.source.type
│ └── mlflow.user
└── meta.yaml
6 directories, 9 files实验结果记录到本地之后可以通过 MLflow 内置的 web server 更直观的查看实验详情:
mlflow ui
点进去查看重要的参数、指标和相关文件详情:

其中实验指标以折线图等可视化方式展现,更加方便获得数据全局观
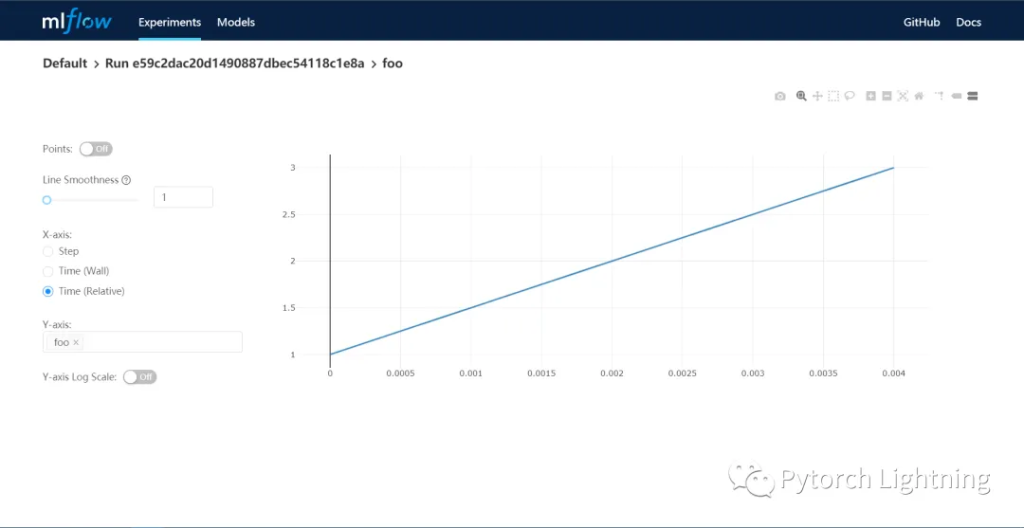
以上就是 MLflow 的第一个功能,实验跟踪。
使用 MLflow Project ,你可以把实验相关的代码、依赖打包成一个可复用、可复现的包,用于其他实验数据或者线上环境。
打包完成后,你可以非常方便的通过 mlflow run 指令在其他地方重新运行该实验,更棒的是还可以直接以 github 的项目 url 为参数运行实验,是不是很酷!
mlflow run your_mlflow_experiment_package -P alpha=0.5mlflow run https://github.com/mlflow/mlflow-example.git -P alpha=5如果你机器上没有部署 conda,或者不希望使用 conda,加上这个参数:
mlflow run https://github.com/mlflow/mlflow-example.git -P alpha=5 --no-condagithub 上的这个例子展示了 MLflow 如何通过 MLproject 文件的方式管理相关依赖和文件的,如果运行该实验的过程中你没有在本地配置 MLflow 的实时实验最终服务也没关系,相关数据会写入到当前目录的 mlruns 目录下,你可以随时通过 mlrun ui 来查看该目录下的实验相关数据。
如果你仔细研究下 mlruns 里面 MLflow 生成的文件就会发现,MLflow 为每次实验都生成一个唯一的 ID,并且通过 MLmodel 描述文件来记录默认要生成的模型相关信息,然后以 scikit-learn 类型保存相关模型,所以你本地是一定要配置好 sklearn 包的。
搞清楚这一点后,就可以用如下的方式来运行一个指定的 MLflow 生成的模型了:
mlflow models serve -m runs:/<your_experiment_id>/model之后就可以通过 curl 或者 postman 之类的接口文件来查看接口是否按照预期推理运行了。
除了 model 文件,其他的比如你觉得需要保存的 txt、img 文件,都可以通过 log_artifact 接口保存、管理起来。
关于 MLflow registry 请自行查阅 docs。
上面提到过,除了实验过程和结果记录在当前目录的 mlruns 目录下,还可以这样通过简单的两行代码实时记录到跟踪服务器上:
import mlflow
mlflow.set_tracking_uri("http://your-experiment-tracking-server")
mlflow.set_experiment("your-experiment-name")比如这样,分别指定需要保存的 metadata 和 artifact 的存储位置,metadata 位置可以指定文件、数据库 URI(sqlalchemy 方式);artifact 支持类似 amazon s3、Azure/Google 等各家的 oss 服务,可以通过配置 minio 等方式统一支持。甚至 FTP/SFTP/NFS/HDFS 也都是支持的。
mlflow server \
--backend-store-uri /your/data/storage/path \
--default-artifact-root s3://my-mlflow-bucket/ \
--host 0.0.0.0MLflow 是一个开源的机器学习生命周期管理工具,主要用于简化机器学习工作流程。它提供实验跟踪功能,记录模型训练过程中的参数、指标和输出,便于对比和复现实验结果。同时支持项目管理,可打包代码和依赖,方便在不同环境中运行。此外,MLflow 还具备模型管理功能,能够注册、版本控制和部署模型,支持多种机器学习框架,帮助数据科学家和工程师高效地开发、测试和部署机器学习模型,提升工作效率和模型管理的规范性。




