

API接口安全性设计,项目中该如何保证API接口安全?

AI智能体(AI Agent)深度解析,主要包括Manus、OpenManus、OWL以及Agent发展史。涉及Manus的核心架构解析、工作流程、技术创新等,OpenManus的设计思路、工作流程、技术架构等,以及OWL的核心架构、核心功能、核心工作流等方面。还有Agent的发展史,从裸大模型调用到长短任务智能体的变化。
Manus是一个真正自主的AI代理,能够解决各种复杂且不断变化的任务。其名称来源于拉丁语中”手”的意思,象征着它能够将思想转化为行动的能力。与传统的AI助手不同,Manus不仅能提供建议或回答,还能直接交付完整的任务结果。
作为一个”通用型AI代理”,Manus能够自主执行任务,从简单的查询到复杂的项目,无需用户持续干预。用户只需输入简单的提示,无需AI知识或经验,即可获得高质量的输出。
这种”一步解决任何问题”的设计理念使Manus区别于传统的AI工作流程,更易于普通用户使用。
Manus 之前做的是 AI 浏览器,后跟 Arc 团队转型做 Dia 遇到了类似的问题,但比他们做的更多更快,于是转去做了现在的 Manus。之前的 Browse Use、Computer Use 的人机协同体验不佳, AI 在跟用户抢夺控制权,当你下达任务之后,只能在一旁欣赏 AI 的表演,如果误触,流程就可能被打断。AI 需要使用浏览器,但 Manus 团队认为应该给 AI 一个自己云端的浏览器,最后把结果反馈给用户就行。
Less Structure, More Intelliengence. 这是业内大家讨论比较多的一个非共识,对于这个问题的热烈讨论从扣子Coze 等平台支持通过 workflow 构建 AI 应用就一直存在。比如 Flood Sung 就在 Kimi 发布 k1.5 时表态,“现在的各种 Agentic Workflow 就是各种带 Structure 的东西,它一定会限制模型能力,没有长期价值,早晚会被模型本身能力取代掉。Manus 就是这样的设计,没有任何搭建的 workflow,所有的能力都是模型自然演化出来的,而不是用 workflow 去教会的。
Manus 设计的第一个核心是给大模型配了一个电脑,让它一步步规划去做 observation 和 action;第二个核心是给它配了系统权限,好比给新来的同事开通了一些公司账户权限,Manus 接入了大量的私有 API,能够处理许多结构化的权威数据;第三个核心是给它 Training,给它培训,就好比跟新来的同事也有磨合的过程,Manus 也会根据你的使用习惯不断的去学习你的要求。
为什么 Manus 说自己是“全球首款真正意义上的通用 AI Agent?”那之前的 Operator、Deep Research、MetaGPT、AutoGPT、Eko 等等不算吗?以及为啥有人说 Manus 是套壳到了极致?在我们的理解里,其实之前的一些 Agent 开源框架也能实现 Manus 类似的效果,但 Manus 做了一些不错的工程优化,率先的产品化了出来。这里 cue 一下另一个华人团队 Flowith,他们半年前做的 Oracle 模式,基本都能实现目前 Manus Demo 演示出的效果。
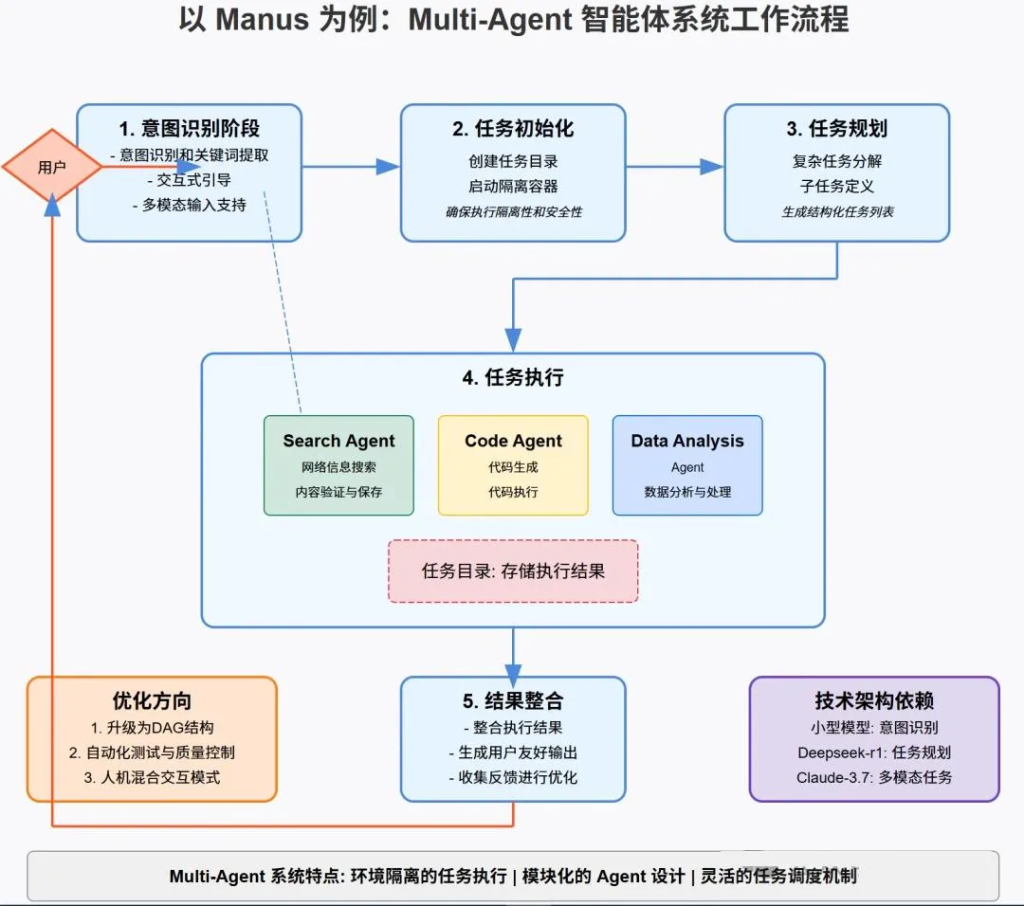
Manus 的架构设计体现 Multi-Agent 系统的典型特征,其核心由三大模块构成:
规划模块是Manus的”大脑”,负责理解用户意图,将复杂任务分解为可执行的步骤,并制定执行计划。这一模块使Manus能够处理抽象的任务描述,并将其转化为具体的行动步骤。
作为系统的决策中枢,规划模块实现:
记忆模块使Manus能够存储和利用历史信息,提高任务执行的连贯性和个性化程度。该模块管理三类关键信息:
构建长期记忆体系:
class MemorySystem:
def __init__(self):
self.user_profile = UserVector() # 用户偏好向量
self.history_db = ChromaDB() # 交互历史数据库
self.cache = LRUCache() # 短期记忆缓存工具使用模块是Manus的”手”,负责实际执行各种操作。该模块能够调用和使用多种工具来完成任务,包括:
这种多工具集成能力使Manus能够处理各种复杂任务,从信息收集到内容创建,再到数据分析。
Multi-Agent 系统(MAS)由多个交互的智能体组成,每个智能体都是能够感知、学习环境模型、做出决策并执行行动的自主实体。这些智能体可以是软件程序、机器人、无人机、传感器、人类,或它们的组合。
在典型的 Multi-Agent 架构中,各个智能体具有专业化的能力和目标。例如,一个系统可能包含专注于内容摘要、翻译、内容生成等不同任务的智能体。它们通过信息共享和任务分工的方式协同工作,实现更复杂、更高效的问题解决能力。
Manus采用多代理架构(Multiple Agent Architecture),在独立的虚拟环境中运行。其运转逻辑可以概括为以下流程:

// todo.md
- [ ] 调研日本热门旅游城市
- [ ] 收集交通信息
- [ ] 制定行程安排
- [ ] 预算规划任务初始化与环境准备:为确保任务执行的隔离性和安全性,系统创建独立的执行环境:
# 创建任务目录结构
mkdir -p {task_id}/
docker run -d --name task_{task_id} task_image执行计划制定:为每个子任务制定执行计划,包括所需的工具和资源。历史交互记录在这一阶段提供参考,帮助优化执行计划。
自主执行:工具使用模块在虚拟环境中自主执行各个子任务,包括搜索信息、检索数据、编写代码、生成文档和数据分析与可视化等。执行过程中的中间结果被记忆模块保存,用于后续步骤。
系统采用多个专业化 Agent 协同工作,各司其职:
每个 Agent 的执行结果都会保存到任务目录,确保可追溯性:
class SearchAgent:
def execute(self, task):
# 调用搜索 API
results = search_api.query(task.keywords)
# 模拟浏览器行为
browser = HeadlessBrowser()
for result in results:
content = browser.visit(result.url)
if self.validate_content(content):
self.save_result(content)Search Agent: 负责网络信息搜索,获取最新、最相关的数据,采用混合搜索策略(关键词+语义)
Code Agent: 处理代码生成和执行,实现自动化操作,支持Python/JS/SQL等语言
Data Analysis Agent: 进行数据分析,提取有价值的洞见,Pandas/Matplotlib集成
动态质量检测:
def quality_check(result):
if result.confidence < 0.7:
trigger_self_correction()
return generate_validation_report()结果整合:将各个子任务的结果整合为最终输出,确保内容的连贯性和完整性。
智能整合所有 Agent 的执行结果,消除冗余和矛盾
生成用户友好的多模态输出,确保内容的可理解性和实用性
结果交付:向用户提供完整的任务结果,可能是报告、分析、代码、图表或其他形式的输出。
用户反馈与学习:用户对结果提供反馈,这些反馈被记忆模块记录,用于改进未来的任务执行。强化模型微调,不断提升系统性能。
1. manus核心优势在Controller层
在agent flow能力(observe,plan和tool decide的大模型环节),大概率这些是使用自己调优训练的大模型的,并且基础模型大概率是qwen
2. manus的核心壁垒是数据
3. manus的AgentFlow有没有可能使用了其他黑科技
4. manus不用MCP协议的原因
Manus具有多项技术特点,使其在AI代理领域脱颖而出:
1. 自主规划能力
Manus能够独立思考和规划,确保任务的执行,这是其与之前工具的主要区别。在GAIA基准测试(General AI Assistant Benchmark)中,Manus取得了最新的SOTA(State-of-the-Art)成绩,这一测试旨在评估通用AI助手在现实世界中解决问题的能力。在复杂任务中实现94%的自动完成率。
2. 上下文理解
Manus能够从模糊或抽象的描述中准确识别用户需求。例如,用户只需描述视频内容,Manus就能在平台上定位相应的视频链接。这种高效的匹配能力确保了更流畅的用户体验。支持10轮以上的长对话维护。
3. 多代理协作
Manus采用多代理架构,类似于Anthropic的Computer Use功能,在独立的虚拟机中运行。这种架构使不同功能模块能够协同工作,处理复杂任务。
4. 工具集成
Manus能够自动调用各种工具,如搜索、数据分析和代码生成,显著提高效率。这种集成能力使其能够处理各种复杂任务,从信息收集到内容创建,再到数据分析。支持自定义工具插件开发。
5. 安全隔离
基于gVisor的沙箱环境,确保任务执行的安全性和稳定性。
6. 其他技术优势
系统的强大能力得益于多层次的模型协作:
| 场景类型 | 典型案例 | 输出形式 |
| 旅行规划 | 日本深度游定制 | 交互式地图 + 预算表 |
| 金融分析 | 特斯拉股票多维分析 | 动态仪表盘 + 风险评估 |
| 教育支持 | 动量定理教学方案 | 互动式课件 + 实验模拟 |
| 商业决策 | 保险产品对比分析 | 可视化对比矩阵 + 建议书 |
| 市场研究 | 亚马逊市场情绪分析 | 季度趋势报告 + 预测模型 |
优点:
缺点:
继deepseek之后,武汉一个开发monica的团队又开发了manus,号称是全球第一个通用的agent!各路自媒体企图复刻下一个deepseek,疯狂报道!
然而manus发布后不久,metaGPT团队5个工程师号称耗时3小时就搞定了一个demo版本的manus,取名openManus,才几天时间就收获了34.4K的start,又火出圈了!现在研究一下openManus的核心原理!
所以agent诞生了!不管是deep search、deep research、manus等,核心思路都是一样的:plan->action->review->action->review…… 如此循环下去,直到触发结束的条件!大概的流程如下:

具体到openManus,核心的流程是这样的:用户输入prompt后,有专门的agent调用LLM针对prompt做任务拆分,把复杂的问题拆解成一个个细分的、逻辑连贯的小问题,然后对于这些小问题,挨个调用tool box的工具执行,最后返回结果给用户!

这类通用agent最核心的竞争力就两点了:
4个文件夹,分别是agent、flow、prompt、tool,只看名字就知道这个模块的功能了

整个程序入口肯定是各种agent啦!各大agent之间的关系如下:

(1)agent核心的功能之一不就是plan么,openManus的prompt是这么干的:promt中就直接说明了是expert plan agent,需要生成可执行的plan!
PLANNING_SYSTEM_PROMPT = """
You are an expert Planning Agent tasked with solving problems efficiently through structured plans.
Your job is:
1. Analyze requests to understand the task scope
2. Create a clear, actionable plan that makes meaningful progress with the `planning` tool
3. Execute steps using available tools as needed
4. Track progress and adapt plans when necessary
5. Use `finish` to conclude immediately when the task is complete
Available tools will vary by task but may include:
- `planning`: Create, update, and track plans (commands: create, update, mark_step, etc.)
- `finish`: End the task when complete
Break tasks into logical steps with clear outcomes. Avoid excessive detail or sub-steps.
Think about dependencies and verification methods.
Know when to conclude - don't continue thinking once objectives are met.
"""
NEXT_STEP_PROMPT = """
Based on the current state, what's your next action?
Choose the most efficient path forward:
1. Is the plan sufficient, or does it need refinement?
2. Can you execute the next step immediately?
3. Is the task complete? If so, use `finish` right away.
Be concise in your reasoning, then select the appropriate tool or action.
"""prompt有了,接着就是让LLM对prompt生成plan了,在agent/planning.py文件中:
async def create_initial_plan(self, request: str) -> None:
"""Create an initial plan based on the request."""
logger.info(f"Creating initial plan with ID: {self.active_plan_id}")
messages = [
Message.user_message(
f"Analyze the request and create a plan with ID {self.active_plan_id}: {request}"
)
]
self.memory.add_messages(messages)
response = await self.llm.ask_tool(
messages=messages,
system_msgs=[Message.system_message(self.system_prompt)],
tools=self.available_tools.to_params(),
tool_choice=ToolChoice.AUTO,
)
assistant_msg = Message.from_tool_calls(
content=response.content, tool_calls=response.tool_calls
)
self.memory.add_message(assistant_msg)
plan_created = False
for tool_call in response.tool_calls:
if tool_call.function.name == "planning":
result = await self.execute_tool(tool_call)
logger.info(
f"Executed tool {tool_call.function.name} with result: {result}"
)
# Add tool response to memory
tool_msg = Message.tool_message(
content=result,
tool_call_id=tool_call.id,
name=tool_call.function.name,
)
self.memory.add_message(tool_msg)
plan_created = True
break
if not plan_created:
logger.warning("No plan created from initial request")
tool_msg = Message.assistant_message(
"Error: Parameter `plan_id` is required for command: create"
)
self.memory.add_message(tool_msg)plan生成后,就是think和act的循环啦!同理,这部分实现代码在agent/toolcall.py中,如下:think的功能是让LLM选择干活的工具,act负责调用具体的工具执行
async def think(self) -> bool:
"""Process current state and decide next actions using tools"""
if self.next_step_prompt:
user_msg = Message.user_message(self.next_step_prompt)
self.messages += [user_msg]
# Get response with tool options:让LLM选择使用哪种工具干活
response = await self.llm.ask_tool(
messages=self.messages,
system_msgs=[Message.system_message(self.system_prompt)]
if self.system_prompt
else None,
tools=self.available_tools.to_params(),
tool_choice=self.tool_choices,
)
self.tool_calls = response.tool_calls
# Log response info
logger.info(f"✨ {self.name}'s thoughts: {response.content}")
logger.info(
f" ️ {self.name} selected {len(response.tool_calls) if response.tool_calls else 0} tools to use"
)
if response.tool_calls:
logger.info(
f" Tools being prepared: {[call.function.name for call in response.tool_calls]}"
)
try:
# Handle different tool_choices modes
if self.tool_choices == ToolChoice.NONE:
if response.tool_calls:
logger.warning(
f" Hmm, {self.name} tried to use tools when they weren't available!"
)
if response.content:
self.memory.add_message(Message.assistant_message(response.content))
return True
return False
# Create and add assistant message
assistant_msg = (
Message.from_tool_calls(
content=response.content, tool_calls=self.tool_calls
)
if self.tool_calls
else Message.assistant_message(response.content)
)
self.memory.add_message(assistant_msg)
if self.tool_choices == ToolChoice.REQUIRED and not self.tool_calls:
return True # Will be handled in act()
# For 'auto' mode, continue with content if no commands but content exists
if self.tool_choices == ToolChoice.AUTO and not self.tool_calls:
return bool(response.content)
return bool(self.tool_calls)
except Exception as e:
logger.error(f" Oops! The {self.name}'s thinking process hit a snag: {e}")
self.memory.add_message(
Message.assistant_message(
f"Error encountered while processing: {str(e)}"
)
)
return False
async def act(self) -> str:
"""Execute tool calls and handle their results"""
if not self.tool_calls:
if self.tool_choices == ToolChoice.REQUIRED:
raise ValueError(TOOL_CALL_REQUIRED)
# Return last message content if no tool calls
return self.messages[-1].content or "No content or commands to execute"
results = []
for command in self.tool_calls:
result = await self.execute_tool(command)#调用具体的工具干活
if self.max_observe:
result = result[: self.max_observe]
logger.info(
f" Tool '{command.function.name}' completed its mission! Result: {result}"
)
# Add tool response to memory
tool_msg = Message.tool_message(
content=result, tool_call_id=command.id, name=command.function.name
)
self.memory.add_message(tool_msg)
results.append(result)
return "\n\n".join(results)think和act是循环执行的,直到满足停止条件,这部分功能在agent/base.py实现的:
async def run(self, request: Optional[str] = None) -> str:
"""Execute the agent's main loop asynchronously.
Args:
request: Optional initial user request to process.
Returns:
A string summarizing the execution results.
Raises:
RuntimeError: If the agent is not in IDLE state at start.
"""
if self.state != AgentState.IDLE:
raise RuntimeError(f"Cannot run agent from state: {self.state}")
if request:
self.update_memory("user", request)
results: List[str] = []
async with self.state_context(AgentState.RUNNING):
while ( # 循环停止的条件:达到最大步数,或agent的状态已经是完成的了
self.current_step < self.max_steps and self.state != AgentState.FINISHED
):
self.current_step += 1
logger.info(f"Executing step {self.current_step}/{self.max_steps}")
step_result = await self.step()
# Check for stuck state
if self.is_stuck():
self.handle_stuck_state()
results.append(f"Step {self.current_step}: {step_result}")
if self.current_step >= self.max_steps:
self.current_step = 0
self.state = AgentState.IDLE
results.append(f"Terminated: Reached max steps ({self.max_steps})")
return "\n".join(results) if results else "No steps executed"既然是while循环迭代,那每次迭代又有啥不一样的了?举个例子:查找AI最新的新闻,并保存到文件中。第一次think,调用LLM的时候输入用户的prompt和相应的人设、能使用的tool,让LLM自己选择一个合适的tool,并输出到response中!这里的LLM选择了google search去查找新闻,并提供了google search的query!

第二次think,给LLM输入的prompt带上了第一轮的prompt和response,类似多轮对话,把多个context收集到一起作为这次的最新的prompt,让LLM继续输出结果,也就是第三次的action是啥!

第三次think:同样包含前面两次的promt!但这次LLM反馈已经不需要调用任何工具了,所以这个query至此已经完全结束!

整个流程简单!另外,用户也可以添加自己的tool,只要符合MCP协议就行!
从外部来看,Manus(以及复刻的 OpenManus)本质上是一个多智能体系统(Multi-Agent System)。不同于单一大模型那种一次性”大而全”的回答方式,多智能体系统通过”规划—执行—反馈”的循环,逐步解决复杂的真实世界问题。在 OpenManus 的设计中,最核心的思路可以概括为以下几点:

OpenManus 的核心设计是构建一个非常精简的 Agent 框架,强调模块化和可扩展性。它通过可插拔的工具(Tools)和提示词(Prompt)的组合来定义 Agent 的功能和行为,降低了开发和定制 Agent 的门槛。
通过对 Prompt 和 Tools 的自由组合,就能快速”拼装”出新的 Agent,赋予其处理不同类型任务的能力。
OpenManus 基于 ReAct(Reason + Act)模式,并以工具为核心驱动 Agent 的行动。Prompt 引导 Agent 的推理和逻辑,而 Tools 则赋予 Agent 行动能力。ToolCall Agent 的引入,进一步提升了工具使用的效率和规范性。
OpenManus 延续了 Manus 的多智能体规划优势,将 PlanningTool 用于对用户需求进行高层规划。这种”先规划,后执行”的思路在复杂、长链任务上效果更佳。PlanningTool 将复杂的用户需求分解为线性的子任务计划,这种规划能力是处理现实世界复杂问题的关键。过去的研究表明,在相同模型能力下,如果缺乏系统的分解和规划,许多真实问题的成功率会大打折扣;而加入规划后,成功率会有显著提升。
当一个任务拆解出若干子任务后,系统会根据子任务类型,动态将其分配给预先定义或适配的 Agent(有各自的工具集和能力倾向)。这种”临时分配 + 工具协作”的机制,可以最大化利用多模型、多工具的组合优势,提高应对不同问题场景的灵活度。Agent 预先装备了不同的工具集以应对不同类型的任务,提高了系统的灵活性和效率。
OpenMan
us 的运行流程可以清晰概括为”规划→分配→执行”,具体步骤如下:

用户在前端或命令行中输入复杂的需求,例如”写一段代码完成某种功能,并自动部署到服务器上”。
系统先调用 PlanningTool,对需求进行分析与分解,形成一个线性结构的计划或任务序列。比如,会将需求拆解为:
这些子任务被记录在一个 plan 或类似结构中。
如果任务中涉及大规模数据分析或机器学习流程,可能会调用一个具备 Data Interpreter 能力的 Agent;
若任务需要复杂的代码修复或文件管理,则会调用另一个能够使用 ComputerUse 工具的 Agent;
系统按照顺序从计划中依次取出子任务;
根据任务关键字或意图判定,分配给最合适的 Agent。目前 Agent 分配主要基于正则匹配,未来考虑使用 LLM 实现更智能的任务分配。
每个 Agent 都会采用 ReAct 循环(Reason + Act)与 Tools 进行交互,以完成自己所负责的子任务。
当某个子任务执行完毕后,系统会将执行结果、关键上下文信息进行必要的”总结与压缩”(以避免不断增加的冗长 Memory),然后存入当前的”Plan 内存”或全局可访问的共享内存。
如果任务完成顺利,进入下一子任务;
若出现执行失败或结果异常,系统可进行自动调试或重新规划,视设计实现程度而定。
当所有子任务执行完毕,系统对整体结果进行汇总并返回给用户,或完成如网页部署、自动执行脚本等操作。
在这个过程中,多 Agent + 工具的结构会在复杂需求上展现明显的优势,尤其当需要长链思考、结合搜索或外部工具时,能够更好地完成通用大模型难以一次性解决的工作。

项目依赖相对简单,主要包括一些用于数据验证(pydantic)、AI 服务调用(openai)、浏览器控制(playwright、browsergym、browser-use)和一些基础工具库:
这样的结构设计使得 OpenManus 在提供强大功能的同时保持了极高的可维护性和可扩展性。
OpenManus 的架构由四个主要模块构成:
Agent 模块采用清晰的继承层次,自底向上逐步增强功能:
示例代码(Manus 实现):
class Manus(ToolCallAgent):
"""
A versatile general-purpose agent that uses planning to solve various tasks.
"""
name: str = "Manus"
description: str = "A versatile agent that can solve various tasks using multiple tools"
system_prompt: str = SYSTEM_PROMPT
next_step_prompt: str = NEXT_STEP_PROMPT
# Add general-purpose tools to the tool collection
available_tools: ToolCollection = Field(
default_factory=lambda: ToolCollection(
PythonExecute(), GoogleSearch(), BrowserUseTool(), FileSaver(), Terminate()
)
)工具模块是 OpenManus 的行动能力基础,各类工具均继承自 BaseTool:
其中,planning.py 实现了 Manus 著名的计划功能,用 Markdown 格式管理任务计划并跟踪执行进度。
Prompt 模块包含了各种 Agent 使用的指令模板,例如 Planning 的系统提示:
PLANNING_SYSTEM_PROMPT = """
You are an expert Planning Agent tasked with solving complex problems by creating and managing structured plans.
Your job is:
1. Analyze requests to understand the task scope
2. Create clear, actionable plans with the `planning` tool
3. Execute steps using available tools as needed
4. Track progress and adapt plans dynamically
5. Use `finish` to conclude when the task is complete
Available tools will vary by task but may include:
- `planning`: Create, update, and track plans (commands: create, update, mark_step, etc.)
- `finish`: End the task when complete
Break tasks into logical, sequential steps. Think about dependencies and verification methods.
"""而 Manus 的系统提示则更加简洁:
SYSTEM_PROMPT = "You are OpenManus, an all-capable AI assistant, aimed at solving any task presented by the user.
You have various tools at your disposal that you can call upon to efficiently complete complex requests.
Whether it's programming, information retrieval, file processing, or web browsing, you can handle it all."Flow 模块负责任务的高层编排和执行流程管理:
PlanningFlow 的执行流程:
每步执行前,系统会生成上下文丰富的提示:
step_prompt = f"""
CURRENT PLAN STATUS:
{plan_status}
YOUR CURRENT TASK:
You are now working on step {self.current_step_index}: "{step_text}"
Please execute this step using the appropriate tools. When you're done, provide a summary of what you accomplished.
"""BaseFlow:抽象基类,定义了 Agent 管理和执行接口
PlanningFlow:实现基于规划的执行策略
创建初始计划(_create_initial_plan)
按计划步骤调用适当的 Agent
跟踪计划执行状态并动态调整
值得注意的是,在当前版本中,虽然 PlanningFlow 具备多智能体调度的能力,但实际上只有单一的 Manus 智能体在执行任务。未来版本可引入更多专业化的 Agent 以充分发挥多智能体协作的优势。
与前文描述一致,OpenManus 实现了简单但有效的记忆管理和 Agent 分配机制:
在AI领域,开源项目正逐渐成为推动技术发展的重要力量。OWL Agent,一个由CAMEL-AI团队推出的开源AI智能体项目,不仅完全复刻了Manus的核心功能,还在灵活性和开源生态上实现了超越。深入了解OWL Agent如何帮助你零成本打造全能的开源AI打工人。
OWL 的多智能体协作机制通过分层架构和模块化设计实现高效协作。它的核心组件包括 BaseAgent、ChatAgent、RolePlaying、Workforce 以及 Task 相关 Agent 等,这些组件各司其职,共同完成任务分解、角色分配和任务执行等功能。

OWL 的多智能体协作机制主要基于以下几个核心组件:
这种设计使 OWL 能够高效处理复杂任务,动态调整任务角色分配,提升多智能体间的协作效率,同时具备自适应学习和优化能力,满足多样化的应用需求。
OWL将Manus的核心工作流拆解为以下六步:
为了实现Agent的远程操作,OWL配备了强大的Ubuntu Toolkit,支持以下功能:
与Manus类似,OWL也具备记忆功能,能够实时存储新知识,并在任务中召回过往经验。这使得OWL在处理类似任务时更加高效。
在Manus爆火之前,CAMEL-AI已经开发了CRAB——一套强大的跨平台操作系统通用智能体。CRAB不仅能操控Ubuntu容器,还能直接控制手机和电脑中的任何应用。未来,CRAB技术将融入OWL,实现跨平台、多设备、全场景的远程操作。
在AI领域,开源的力量是无穷的。OWL项目不仅在0天内复刻了Manus的核心功能,还通过开源模式吸引了全球开发者的参与。它不仅性能卓越,还具备高度的灵活性和扩展性。
| 维度 | OWL | 开放手册 |
| 执行环境 | Docker 容器 + 原生系统穿透 | 本地沙箱环境 |
| 任务复杂度 | 支持多设备联动任务 | 单设备线性任务 |
| 记忆系统 | 增量式知识图谱(支持版本回溯) | 临时记忆池(任务级隔离) |
| 资源消耗 | 单任务平均 8 万 tokens | 单任务峰值 24 万 tokens |
| 扩展性 | 插件市场 + 自定义工具链 | 固定模块组合 |
OWL Agent作为一个开源AI智能体项目,不仅在性能上达到了行业领先水平,还在成本和灵活性上具有显著优势。它为开发者和用户提供了一个零成本、高性能的AI工具,能够满足多种应用场景的需求。



【金融场景:搜索+知识库rag】
大致可以理解成多个Agent进程/线程会并行工作,相互之间通过某些机制进行沟通(例如消息队列)
典型案例:metagpt的多角色协同(产品、后端、前端、测试),斯坦福小镇
不出现并行工作的,不是Multi-agent;coze上所谓的“Multi-agent”就是典型的错误概念,因为它只是不同的agent之间串行流转。
通常需要较长的步骤或者较多的时间才能完成,需要进行agentflow编排。
Copilot 类。
Agentic 类。

【autogpt】自动 GPT





