

使用DeepSeek和Claude绘制出高质量的SVG 图片

在生成式模型与信息检索技术飞速发展的当下,如何将两者有效结合,以提升问答系统的准确性和实用性,成为了技术探索的前沿焦点。为了探寻最优解,我深入研究并实践了18种不同的 RAG(Retrieval-Augmented Generation)技术,从基础方法到复杂的多模型融合,不一而足。经过一系列严谨的实验,数据揭示了一个令人瞩目的结果:Adaptive RAG 凭借其动态调整策略和卓越的检索效果,在众多技术中脱颖而出,以0.86的高分成为本次实验的佼佼者。

接下来,我将深入剖析每种 RAG 技术的核心理念、实现细节以及各自的优缺点,旨在帮助大家更全面地理解这些前沿方法。



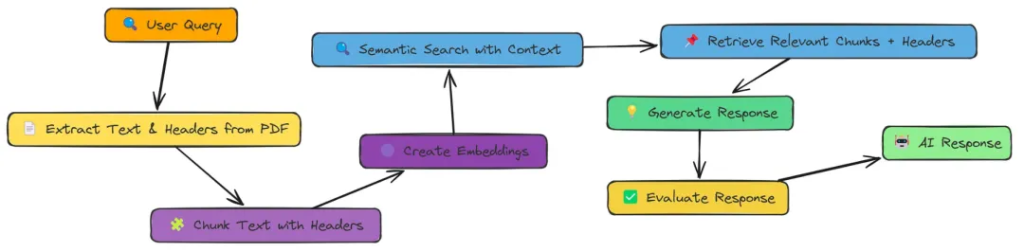
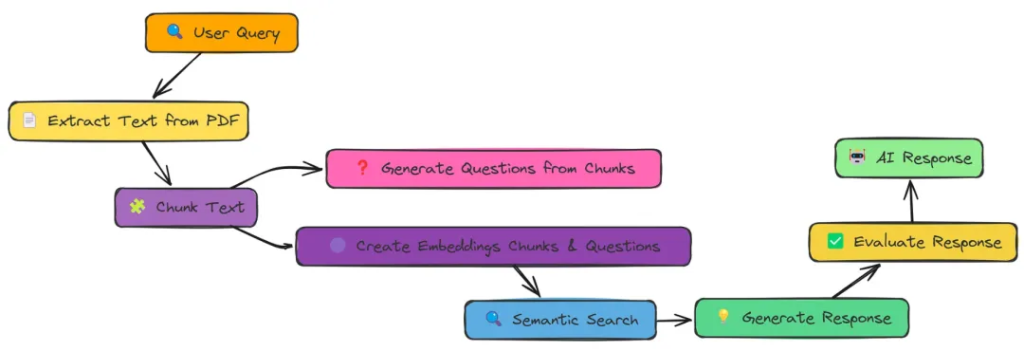




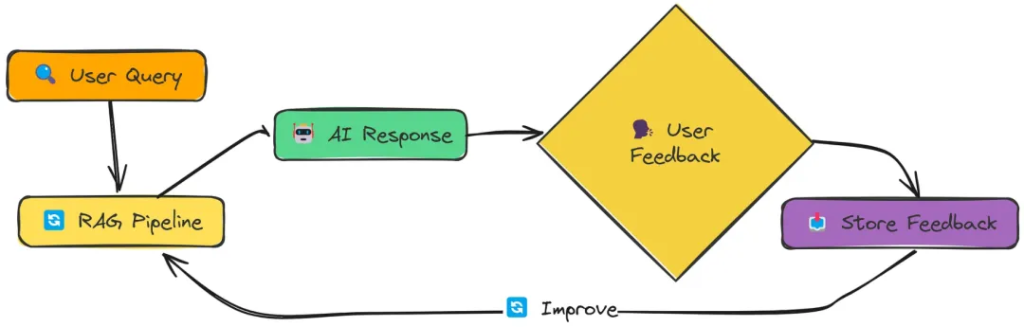




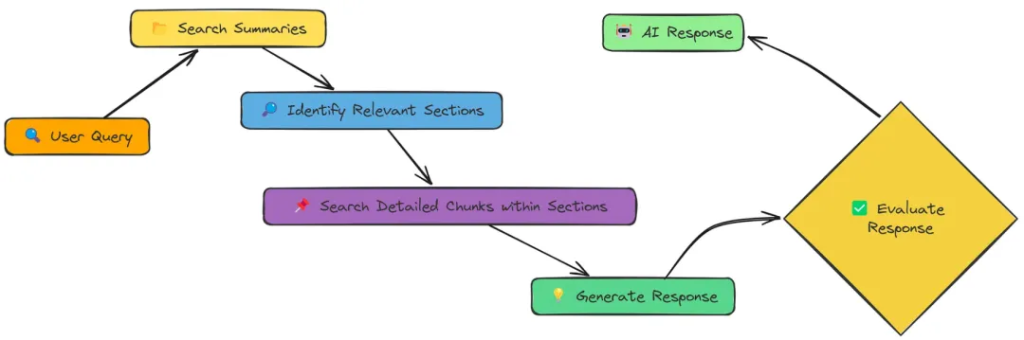




在实验过程中,我全面测试了上述18种 RAG 技术。每种技术在检索精度、响应效率以及实现难度上各有优势,但实验数据明确指出,Adaptive RAG 凭借其灵活的策略调整和出色的自适应能力,以0.86的高分在综合性能上拔得头筹,成为最优选择。
通过此次实验,我不仅深入掌握了每种 RAG 技术的核心原理和实际应用场景,还为在不同项目中挑选合适的技术方案积累了丰富经验。展望未来,随着生成模型和检索技术的持续发展,RAG 方法将不断演进,为问答系统带来更高的智能化和效率提升。
文章转载自:经过18次尝试后,我发现了最佳 RAG 技术







