

DeepSeek+dify知识库,查询数据库的两种方式(api+直连)


https://arxiv.org/abs/2402.13116 这篇论文是干嘛的?这篇论文是关于“知识蒸馏”(Knowledge Distillation,简称 KD)在大型语言模型(Large Language Models,简称 LLMs)中的应用。
简单来说,知识蒸馏就像是让一个“聪明的大老师”(比如 GPT-4)教一个“普通的小学生”(比如开源模型 LLaMA),把大模型的聪明才智传给小模型,让小模型也能变聪明,而且更省资源、更容易用。
论文的作者们想给大家讲清楚三件事:
他们还特别提到了一种“数据增强”(Data Augmentation,简称 DA)的技术,说它在知识蒸馏里特别重要,能让小模型学得更好。
论文结构很清晰,分成了算法、技能和应用三个大块(这叫“三大支柱”),后面我会详细讲。
想象一下,GPT-4 这样的“大模型”超级聪明,能写文章、回答问题、甚至帮你解决问题,但它有个问题:太大了,太贵了,不是每个人都能用得上。就像一台超级豪华跑车,性能强但耗油多、一般人开不起。
而开源模型(比如 LLaMA、Mistral)呢,虽然免费、灵活,但本事没那么大,就像一辆普通小轿车。知识蒸馏的目标就是:
论文里还提到,这种技术还能让开源模型自己教自己变得更强(自改进),或者把大模型压缩得更高效。
知识蒸馏最早是用来把复杂的神经网络“压缩”成简单的小网络。比如原来一个大模型有几亿个参数,跑起来很费电脑,蒸馏后弄成一个小模型,参数少多了,但还能干差不多的事。
到了大型语言模型时代,知识蒸馏变得更高级了。现在不光是压缩模型,还要把大模型的“知识”和“能力”传给小模型。比如,GPT-4 能写诗、推理、聊天,知识蒸馏就想让小模型也学会这些本事。
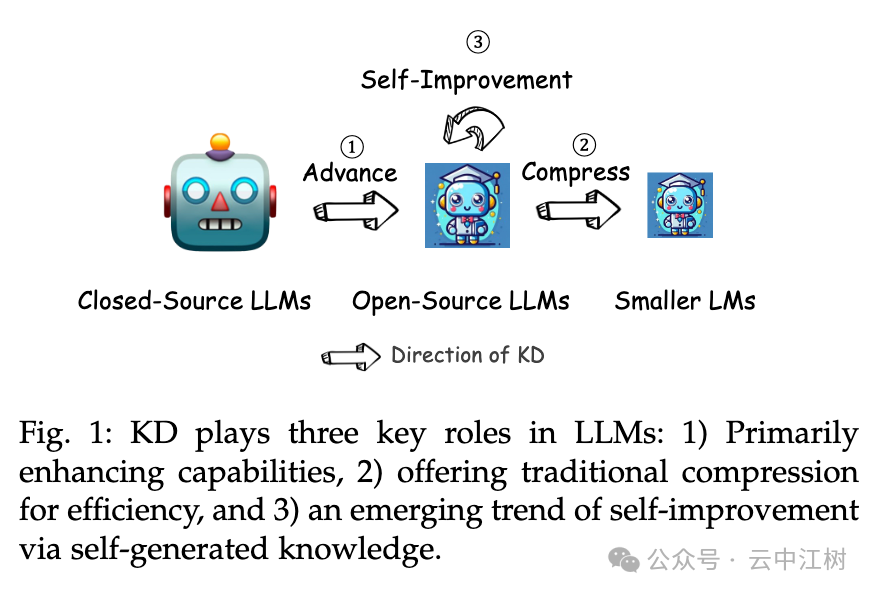
论文里提到,知识蒸馏有三个主要作用(见图 1 位置:Fig. 1: KD plays three key roles in LLMs):
数据增强听起来很高大上,其实就是“造数据”。
比如,你给 GPT-4 一点点“种子知识”(比如几个问题和答案),它就能生成成千上万类似的问答对。这些数据不是随便乱造,而是针对特定技能(比如数学推理)或领域(比如医学)量身定做的。有了这些数据,小模型就能拿来练习,学到大模型的本事。
这就像给小学生准备了一堆精选练习题,比随便找点题做效果好多了。
论文给了个通用流程,告诉你怎么把大模型的知识传给小模型(见图 4 位置:Fig. 4: An illustration of a general pipeline to distill knowledge):
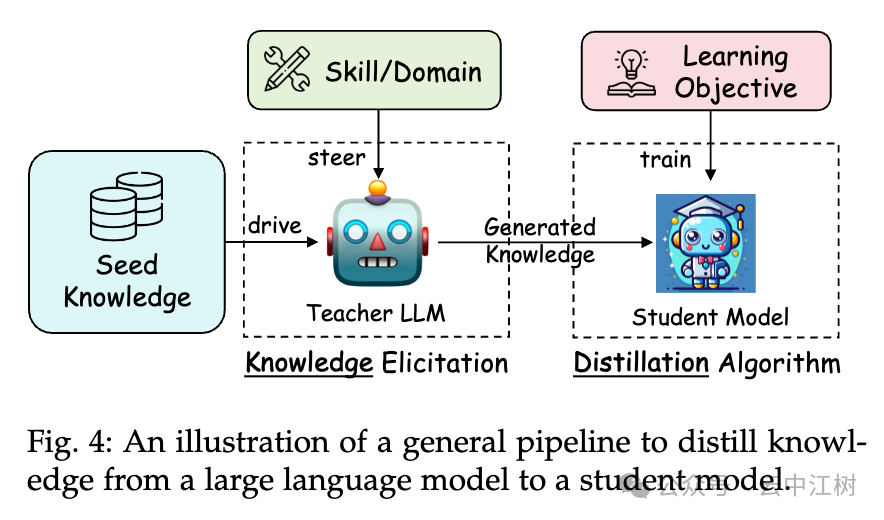
这个流程简单来说就是:
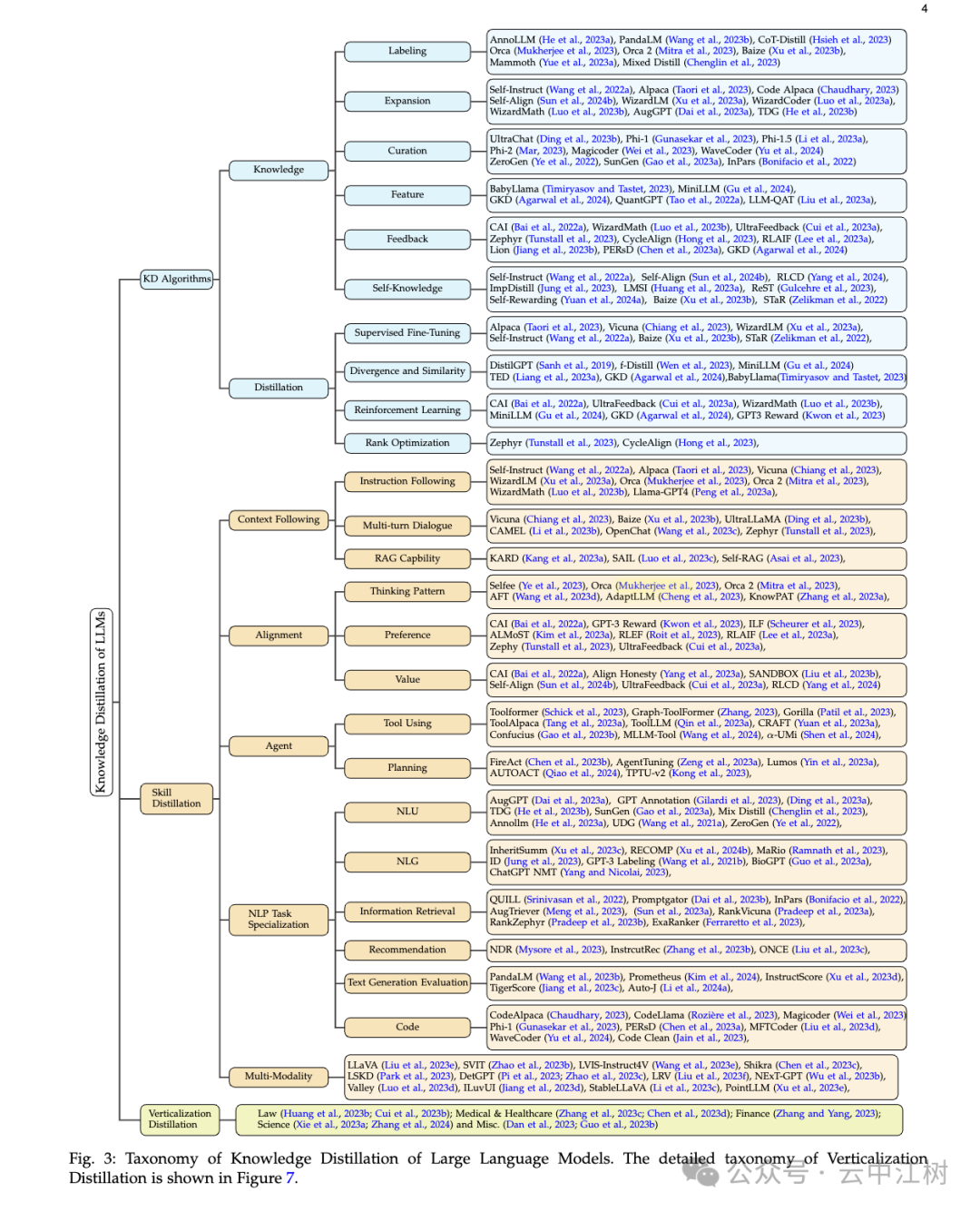
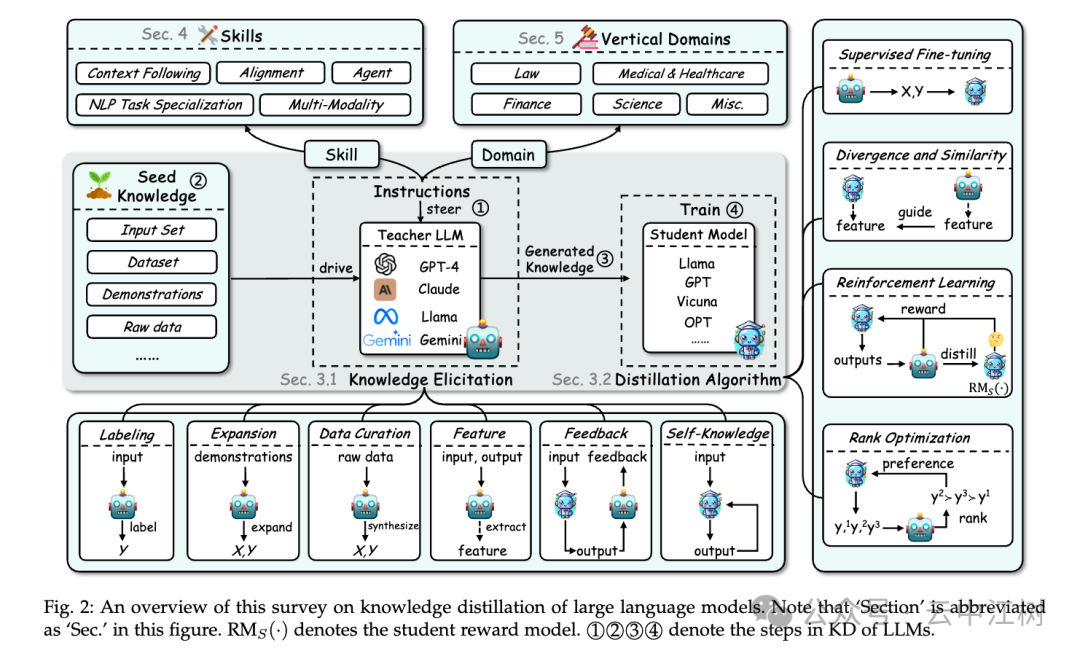
论文把知识蒸馏分成三大块(见图 3 位置:Fig. 3: Taxonomy of Knowledge Distillation of Large Language Models):
这是讲怎么“教”。论文分了两步:
知识怎么挖出来(Knowledge):
怎么教小模型(Distillation):
这是讲教小模型“学会什么”。论文列了好多技能:
这是讲小模型“用在哪”。论文举了几个例子:
这篇论文就像一份“AI 教学指南”。
它告诉你怎么用大模型(比如 GPT-4)当老师,把知识传给小模型(比如 LLaMA),让小模型变得聪明、好用还能省资源。核心是三大块:
数据增强是个秘密武器,能造出好教材,让小模型学得更好。论文还给了很多例子和方法(具体看图 2 位置:Fig. 2: An overview of this survey)。
如果你感兴趣,可以去他们的 GitHub(https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs)找更多资料。







