

IT咨询顾问的关键抓手-DeepSeek+企业架构-快速的熟悉和洞察一个新的行业

上一篇文章真·生产级满血版Deepseek-r1 671B部署实例我们在2台 8 * H100 80G上成功的完成了部署并使用了几天,在真实的生产环境上运行了几天,也遇到了一些问题,随之对相应的问题进行了一些调整和优化,本文就来详细说一说。
首先声明,应该不是引擎有问题,应该是我菜还没找对办法,这个引擎是相当强大的!VLLM在2025年1月27日公布了V1版本,具体的详细内容可以看https://blog.vllm.ai/2025/01/27/v1-alpha-release.html主要就是为了解决过去V0版本的性能问题和大量技术债务,但是遗憾的是,在当前这个时间点官方貌似并没有在V1引擎上支持Deepseek。
所以在上一篇文章中,我也只能无奈选择退回到V0引擎的版本。听闻有些技术能力强的大厂哥哥们已经搞定了这个问题,这个确实佩服,点赞👍!起初在部署起来的时候是非常让人兴奋的,简单看了一下VLLM后台的日志,每秒的生成速度在21-30之间波动,人肉平均一下就是25tokens/s左右(没有详细测,人肉估计),人肉检测首个token返回时间大概在1.8s-1.9s左右,已经达到了跟官网网页上的速度类似的速度。但是随着开放使用之后,问题就来了,在处理长上下文的时候(4k以上),出现了一种偶发性的降速,并且这个请求直到处理完之前,都会一直保持1 tokens/s以下。
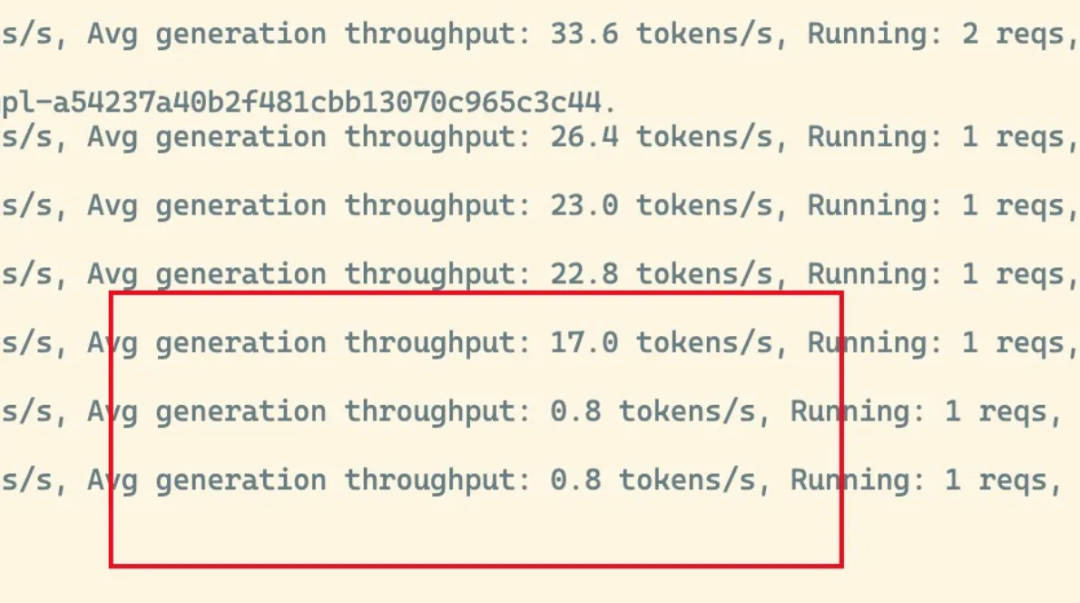
在中可以看到所有GPU的利用率会直接冲到100%,直到这个超卡的请求全部生成完,才会恢复正常。实体感受就像一个人前一秒在口若悬河的疯狂吹牛,下一秒他突然就卡壳了。如果单纯只是这一个请求卡住了,那么影响的是这一个人的使用,倒还勉强能接受。可惜的是接下来进来的每一个请求都会非常慢,有一种一个坏学生把全班的好学生都教坏了的既视感😂。如果长prompt无法使用,那么就注定在RAG这个企业内部最常用的AI场景出现了死局。
鉴于上述问题,希望有感兴趣的大佬也可以来指导我一下,感激不尽,我这边也会和开源社区继续研究推理引擎,把这个问题解决掉。马斯克说,很多即使很优秀的工程师都会在已有的路径上持续去优化一个也许不该存在问题,这就是路径依赖。通往罗马的路不止只有一条,解决问题的办法也可以是让问题本身不存在。VLLM就是我的路径依赖,因为太熟悉也太好用,所以一开始就直接选择了他抱着这样的想法我们再来回头重新审视问题重新找到Deepseek的官方仓库:https://github.com/deepseek-ai/DeepSeek-V3可以看到除了第一个以外,Deepseek推荐的第一个是一个叫作SGLang的推理引擎。

查看这个引擎的文档清晰的写到:SGLang从一开始就在与Deepseek团队深度合作,完成了Deepseek V3的适配工作,并且给出的详细的部署步骤。大佬之间的已经达成深度合作了,那还有啥好说的呢?直接开测!
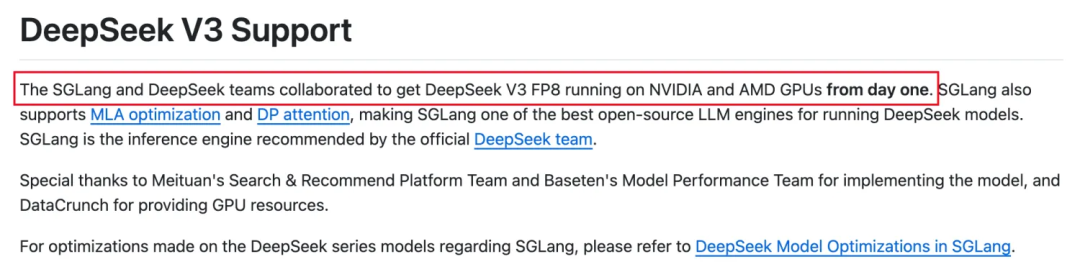
部署文档可见:https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
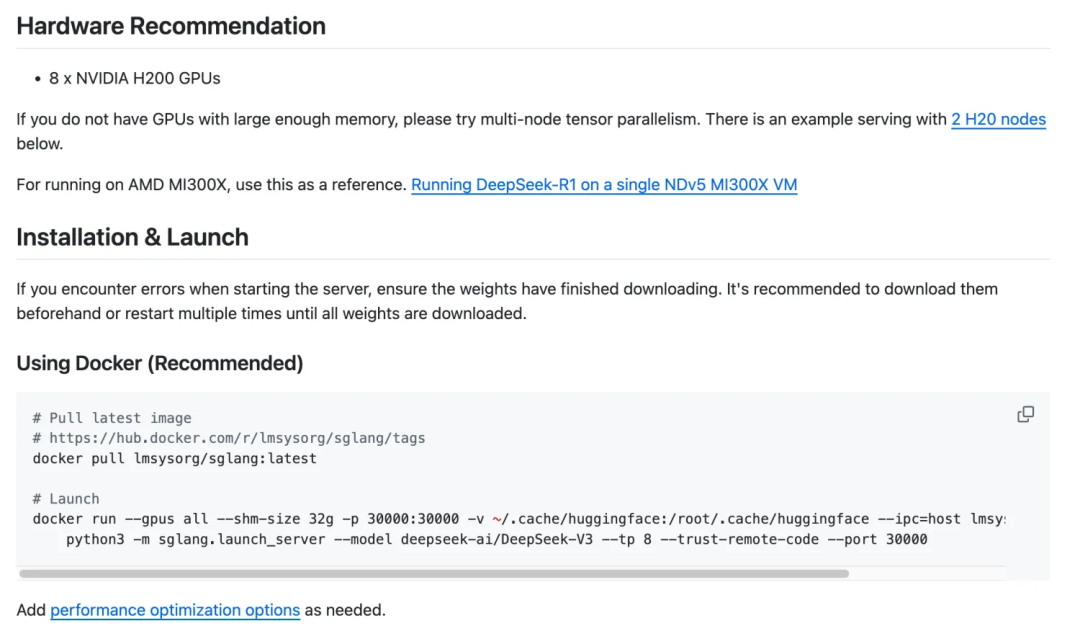
有了这个,我们只需要重新调整一下部署脚本,把相应的Deepseek V3换成Deepseek R1即可(tokennizer是一样的,所以可以通用)在两个节点上分别执行下面的命令,过一会就看得到
神奇的事情就自然而然的发生了,引擎一次性启动成功并且经过测试,token的生成速度达到了31+tokens/s,较原方案大幅提升了20%+
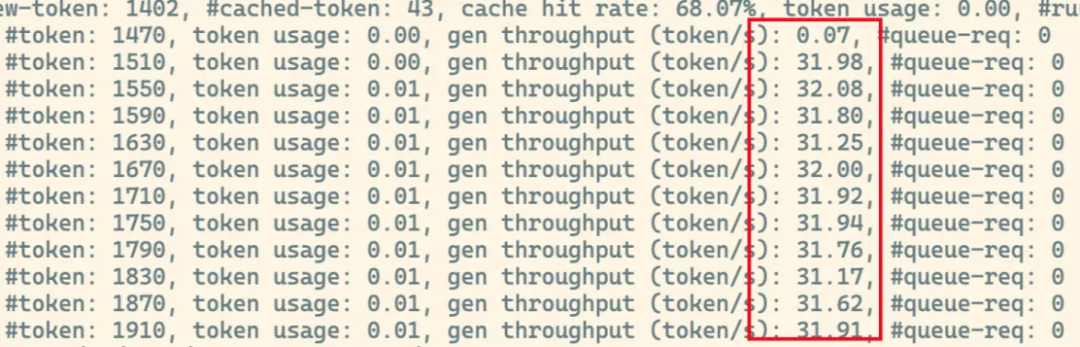
经过一天多的使用,也没有再次出现过降速和卡顿的问题。
一个大模型系统,从直观感受来目测系统响应速度有两个点
单个请求TTFT首先简单用one-api去测试一下系统的反应,首次未命中缓存时,大概在1.9s左右,后续命中缓存的情况下,降低到只有0.43秒。

针对TTFT的测试:随机生成16/256/1024/2048/4096/8192/16384/32768/65536个随机token来当做输入prompt,模拟在不同长度输入的场景下,用户能接收到的第一个字符的平均等待时间,时间越短,用户见到第一个token速度越快。
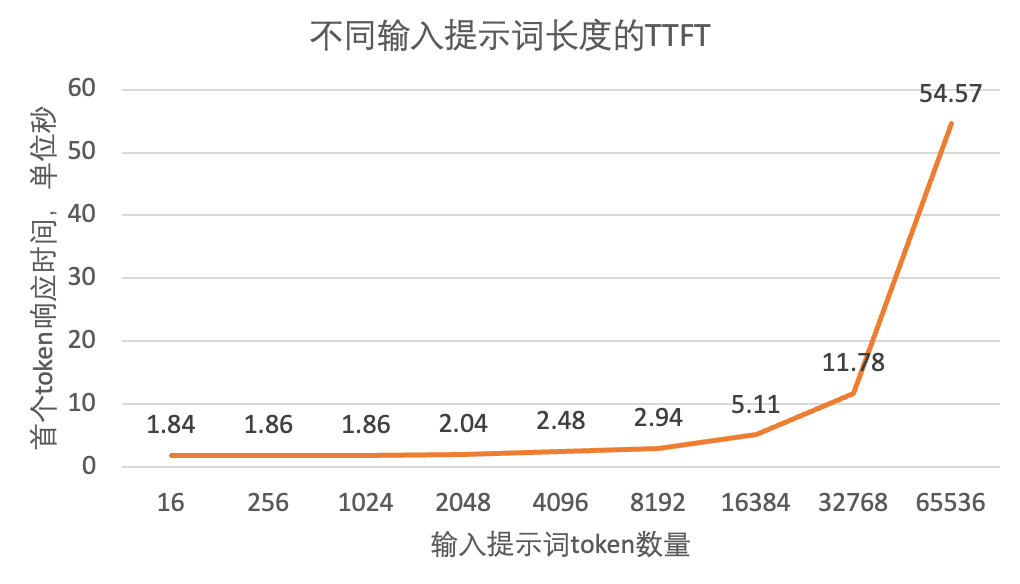
这里可以看到一个非常有趣的现象,在长度为8192个token之前的TTFT增长曲线是比较平缓的,到8192之后陡然上升,而且呈现一个很有意思的趋势16384是8192的2倍,5.11接近2.94的2倍;32769是8192的4倍,11.78接近2.94的4倍;貌似是一个线性的增长关系,这个8192就是一个比较有趣的数字。这时候回头再看系统在启动过程中打印的日志中包含了这样一个数字,那么大概率这里就跟这个chunked_prefill_size有关。
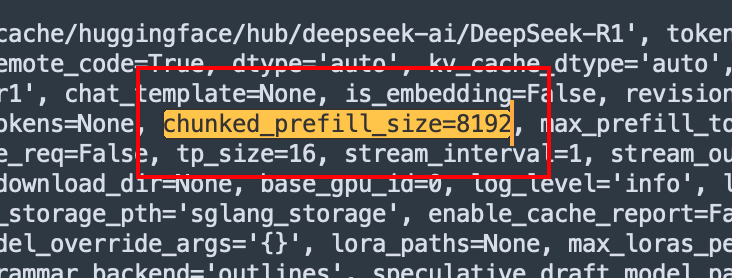
8 * H100了,直接拉大来提升速度就会是一个不错的优化选择,具体的优化细节我们有机会再来讨论。

Output Thoughput token/s上文已经提到过,单个请求的输出速度基本保持在了31-32token/s之间,肉眼可见的快速。
并发TTFT这次我们使用1024个随机输入token,对模型的进行10/20/30/40/50/100并发进行测试,来看分别在不同并发量的情况下,token最大的生成速度和TTFT。
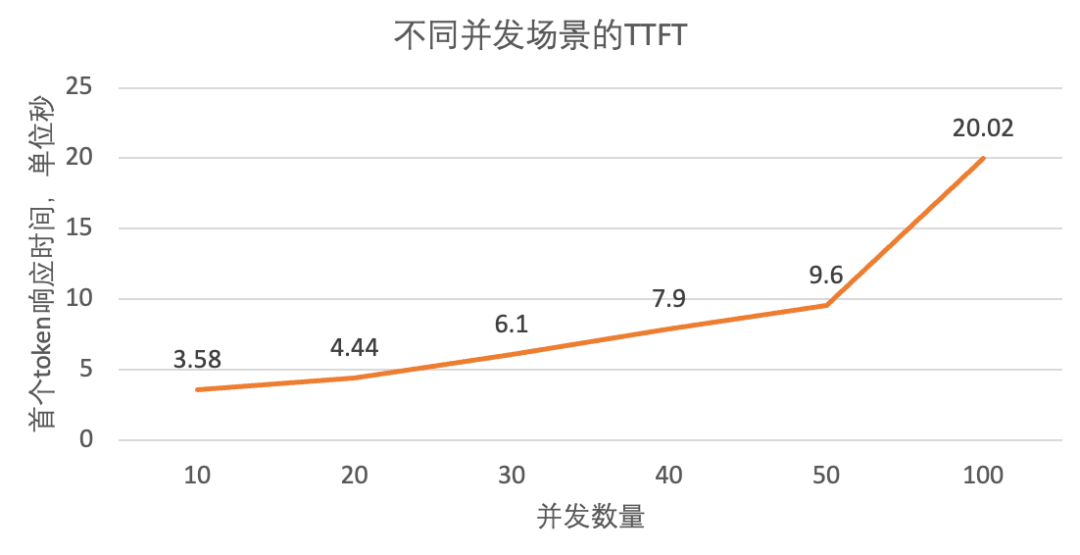
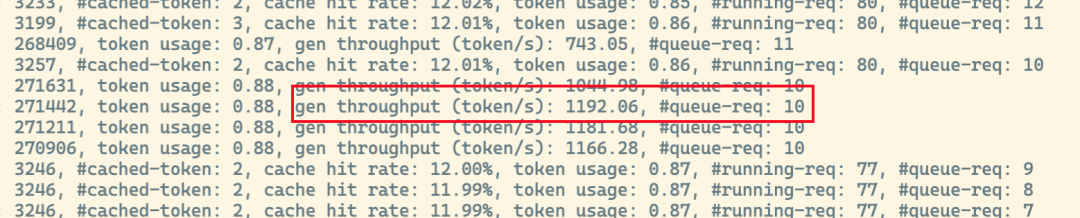
可以看到当并发请求上到超过50并发时,系统的等待时间已经超过10秒了,这时候给人的感觉已经是很慢了,再往上拉高并发数量也基本失去了意义。Output Thoughput token/s这块基本上就是纯属娱乐一下了系统的最大吞吐量,当以1024个随机token输入,500并发时出现将近1192.06token/s(当然这个数据只是估算出来的,并没有太多实际的价值)。
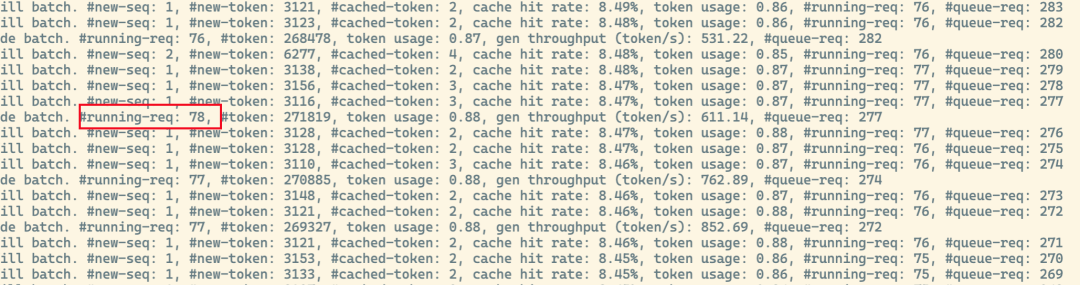
在我们使用默认参数的情况下,能看到日志中最大可以处理的请求数量为78。
这个参数在默认的时候是没有设置的,Deepseek给出的推荐值如下图所示。

在完成Deepseek-r1的部署之后,我们发现的VLLM中可能存在的潜在问题目前无法解决,随后替换成了SGLang来暂时让系统达到可用状态。接下来对整个系统进行了一系列的测试,在测试过程中发现了很多有意思的参数设置,比如
个人能力有限,本次测试的效果可能不能代表最真实的生产环境,肯定有很多大佬的优化效果更好,望指正或许/没准/Perhaps,下次我们拿村里的大学生组合,华为昇腾再来折腾折腾??
大家都在看的硬核博主技术分享真·生产级满血版Deepseek-r1 671B部署实例







