

IT咨询顾问的关键抓手-DeepSeek+企业架构-快速的熟悉和洞察一个新的行业

本来过年前准备出去旅游的,Deepseek来了一波疯狂炸场,把全世界的目光都吸引了过来,这波泼天的流量也是没谁了。年后没多久,因为一些特定的原因,官网的Deepseek基本都变成了这个状态。
手上刚好有几张算力还算可以的显卡经过一系列折腾终于完成了完整版Deepseek-r1 671B满血版生产级的部署,本来就来详细讲一下。本人水平有限,部署过程中对各种设备、模型、网络等内容的理解有限,还望各位高手指正。
生产级满血版的Deepseek-r1,我们应该直奔他的原版仓库。
huggingface的Deepseek-r1仓库地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
魔塔社区(modelscope)的Deepseek-r1仓库地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1

因为网络的问题,我们可以通过魔塔社区去下载可能会比较快,毕竟这个模型还是很大的。这里可能需要澄清一下,网络上各种文章说Deepseek-r1的文件大小有600G、700G还有1T以上可能都不是非常准确。实际在linux下载后的完整版是642G。

还需要注意的是,可能大家看到的更多的是ollama官网的671b写的是404G,如下图。
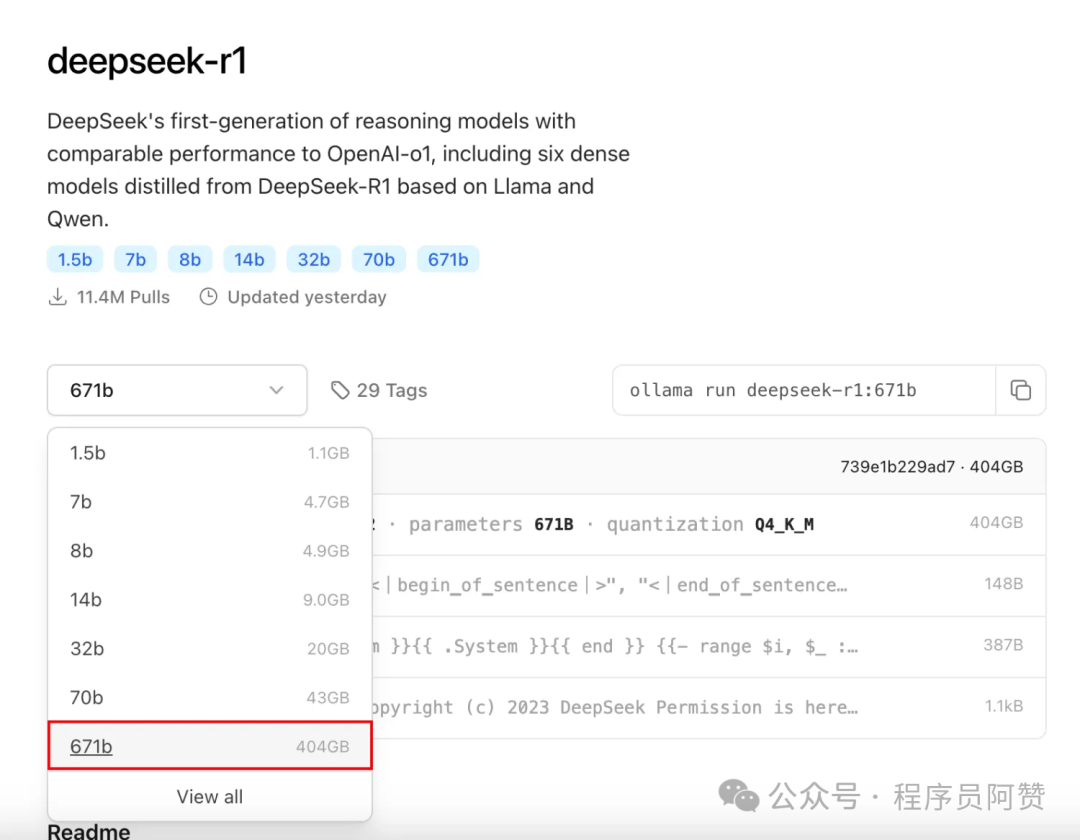
这个并非不准确,而是ollama提供的是一个4bit的量化版本,并非真正的满血非量化版本。
在这里我们准备2台8 * NVIDIA H100 80GB HBM3的服务器,并且显卡之间用Nvlink进行连接。当然如果有H200可能效果会更好,但是毕竟那玩意还是太稀有了。按照英伟达官网安装好显卡驱动、cuda、以及nvidia-fabricmanager,这里列出我使用的版本。
显卡驱动版本:

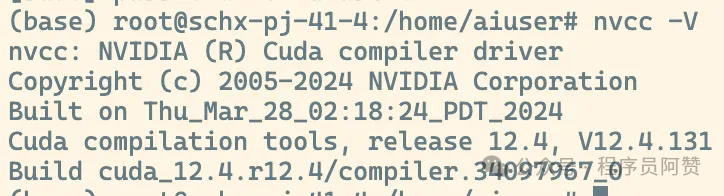
cuda版本:
nvidia-fabricmanager:

这里值得注意的是,上述三个软件版本一定要相互匹配,不然是运行不起来的。
模型、硬件都准备好了,接下来就是软件了。在这里我选择了vllm作为推理引擎,地址:https://github.com/vllm-project/vllm

它与ollama类似,但是具有更高性能的特点,社区也比较活跃,有关他的详细介绍也可以看看其他的文章。为了简化部署和统一环境,我们只需要下载vLLM的docker镜像即可。在两台服务器上分别执行命令。
如果网络不太好,在阿里云上也有相应的镜像。
到此我们所有的准备工作就都做完了,接下来就可以进入部署阶段了。

根据vllm的部署文档https://docs.vllm.ai/en/latest/serving/distributed_serving.html,我们首先要找到一个脚本用来做分布式推理。脚本地址:https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh然后在两个不同的节点上分别执行命令。
两个节点均完成启动之后,找到其中一个节点,使用
进入容器,这时候就可以执行vllm的启动命令了。
如果顺利的话,在漫长的等待之后,就可以看到模型所有的safetensors被一个一个的加载起来。
这时我们再去找一个Chatbox、Open WebUI等图形化工具进行一些简单的配置,就可以对话了。
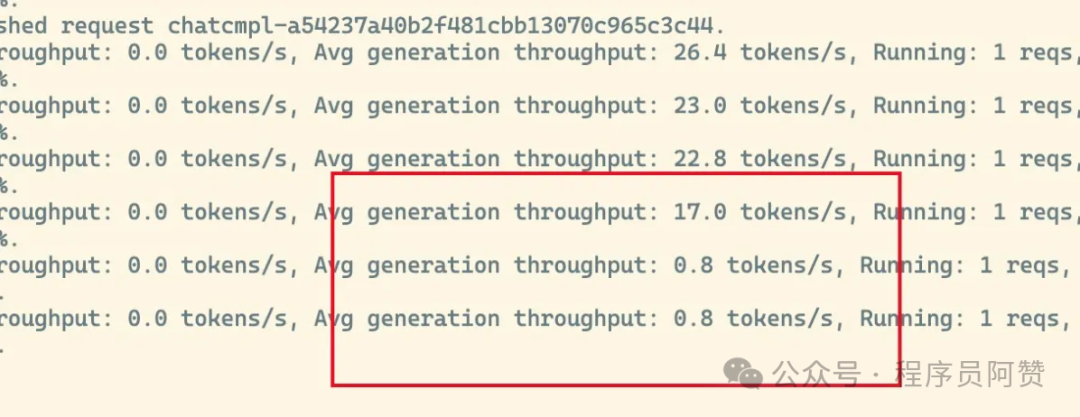
但是总会有但是,部署的过程肯定不会那么顺利,尤其是在多机多卡的推理场景上。用上述脚本只能勉强把模型跑起来,跑起来之后,跟官网上那种流畅的速度比起来简直是千差万别,基本上就是一个字一个字在蹦非常的慢。我们在后台看到token的生成速度,好一点的时候可能有20+tokens/s,稍微问多一点的时候可能会掉到只有不到1tokens/s,非常的惨。
到了这里可能会怀疑为什么这么多H100还是会这么慢?因为实际上这里的瓶颈已经不在于显卡的算力,即使不是16张H100而是16张4090的话,算力也不是阻碍。搞过多机多卡训练的大佬可能就会知道,在这种场景下网络带宽才是真正限制推理速度的最大阻碍。
InfiniBand (以下简称IB网络)是一种专为高性能计算(HPC)和超大规模数据中心设计的网络技术,以亚微秒级超低延迟和超高带宽为核心优势。这里的带宽,不是指家里的千兆网或者机房中的万兆网(10G/s)就那么简单,而是有接近400G/s的超高速显卡互联网络。
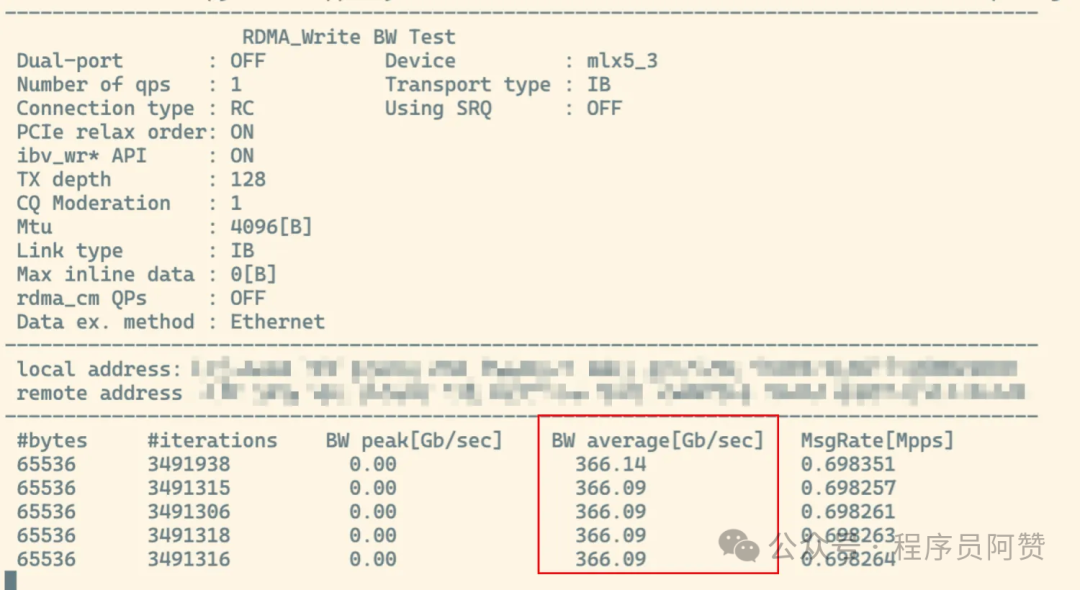
在保证系统上安装且启用了IB网卡的情况下,我们用命令
可以看到IB网口的状态。
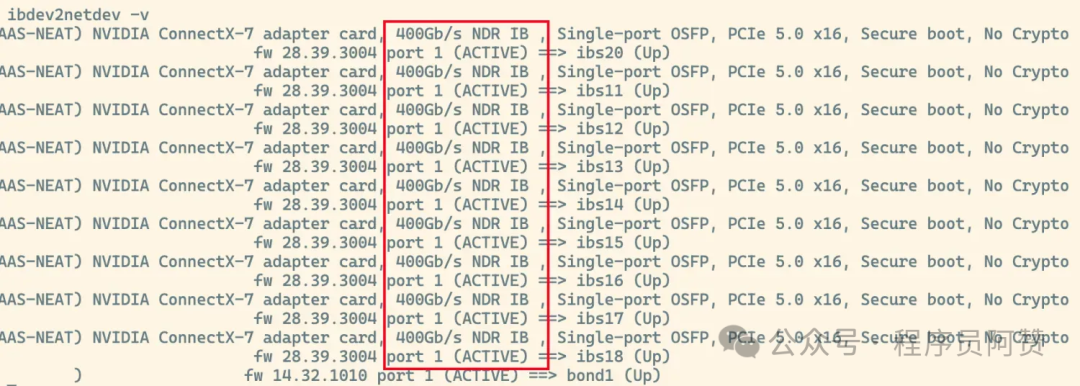
当确认了IB网络是通畅的时候,我们需要对上述的启动脚本进行修改,在两个节点上分别执行以下命令。
新增的环境变量配置,主要用于启用IB网络通信,而非使用以太网进行通信,详细的每一个参数的具体含义,可以在英伟达NCCL的官方网站上找到说明。https://docs.nvidia.com/deeplearning/nccl/archives/nccl_2215/user-guide/docs/env.html
在完成配置之后,重新启动vllm,就可以看到如下的效果了。
部署到这里,我们就得到了一个跟官网不卡的时候速度类似的满血版Deepseek-r1,希望这个文档对你有所帮助。下一步,我会对已经完成部署的模型进行压测,来探索系统的性能极限在哪里,以及如何在生产环境中何如进行进一步的性能优化,期待你的关注。个人水平有限,有误的地方望指正。
RuntimeError; Nccl error; unhandled svstem error (run with NCCL DEBUG INE for deta)
这个报错大概率是nccl配置有问题,单机多卡场景下,请按照如下思路排查。
设置了IB网络,输出还是很慢
在启动脚本前加入NCCL_DEBUG=INFO,并检查是否有如下日志,最关键的就是。
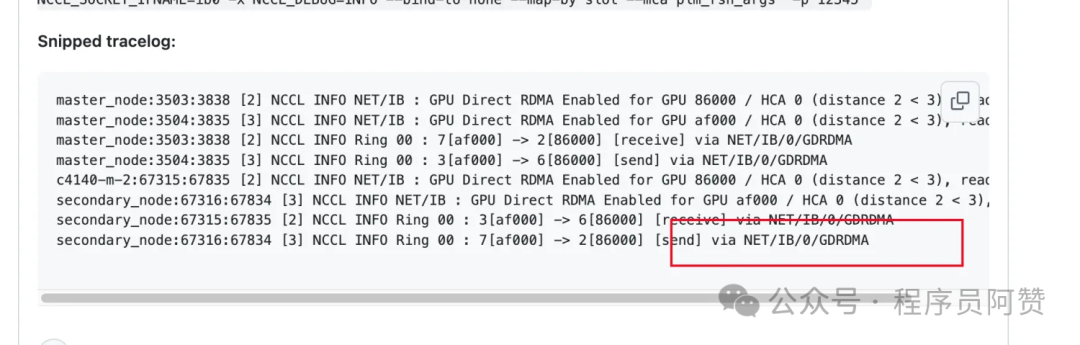
NCCL中的RDMA(远程直接内存访问)通过绕过操作系统内核实现GPU内存直接跨节点通信,减少数据传输延迟和CPU开销;该技术利用网卡的零拷贝能力加速多机多卡间的集体操作(如AllReduce),显著提升分布式训练的通信效率。如果你找到的日志是[send] via NET/SOCKET,则表示网络通信是通过以太网传输的,那么这时字符输出很慢是正常的。如果你找到的日志是[send] via NET/IB/0,则表示网络通信是通过IB网络的,但是没有开启GDRDMA技术,则会有大致5%的性能损耗(网传,未实测)。
排查思路如下:
、
等环境变量的配置进行修改并调试,NCCL的官方网站https://docs.nvidia.com/deeplearning/nccl/archives/nccl_2215/user-guide/docs/env.html,会有给你很大的帮助。

IT咨询顾问的关键抓手-DeepSeek+企业架构-快速的熟悉和洞察一个新的行业

基于Ollama与AnythingLLM的DeepSeek-R1本地RAG应用实践

模型引擎的技术债务?一个Deepseek三种API引发的连锁反应

Windows 上快速部署.NET Core Web 项目

.NET开发者看过来!DeepSeek SDK 集成

LangChain4j实战-Java AI应用开源框架之LangChain4j和Spring AI

后端开发人员Docker快速入门

生产级满血版Deepseek-r1 671B部署后续问题、调优以及压测

【LLM落地应用实战】LLM + TextIn文档解析技术实测