PyGraphQL-API,GraphQL查询的完美方案!
文章目录
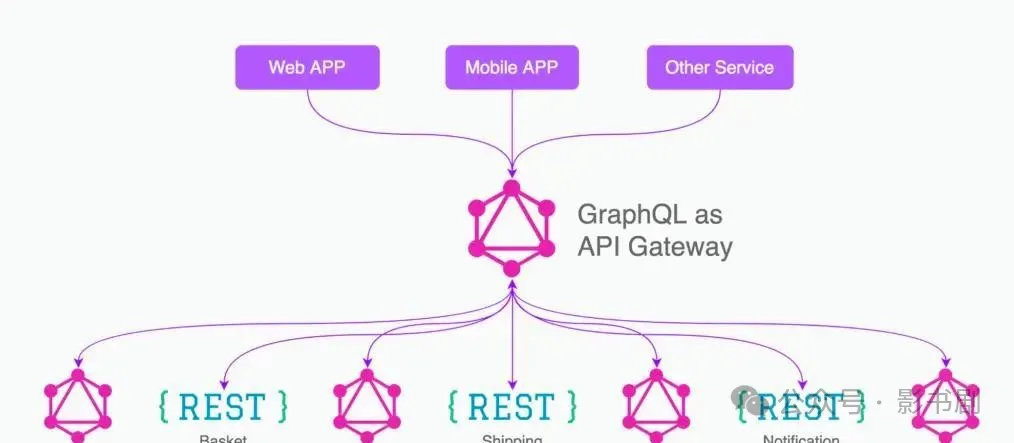
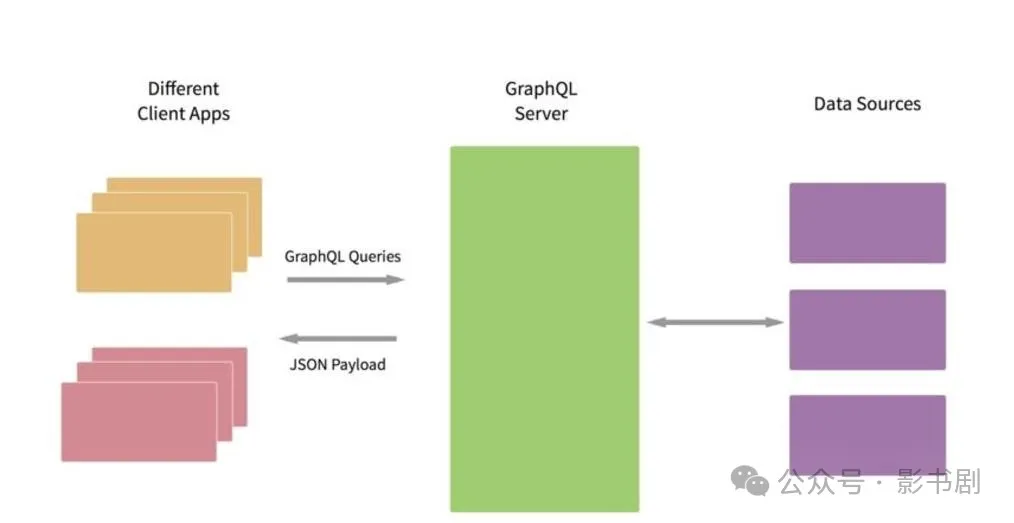
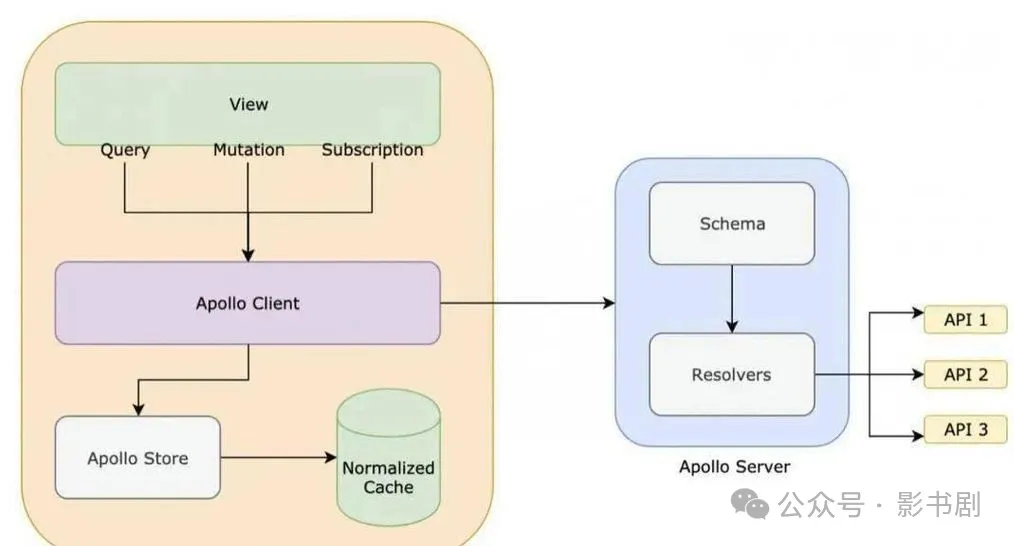
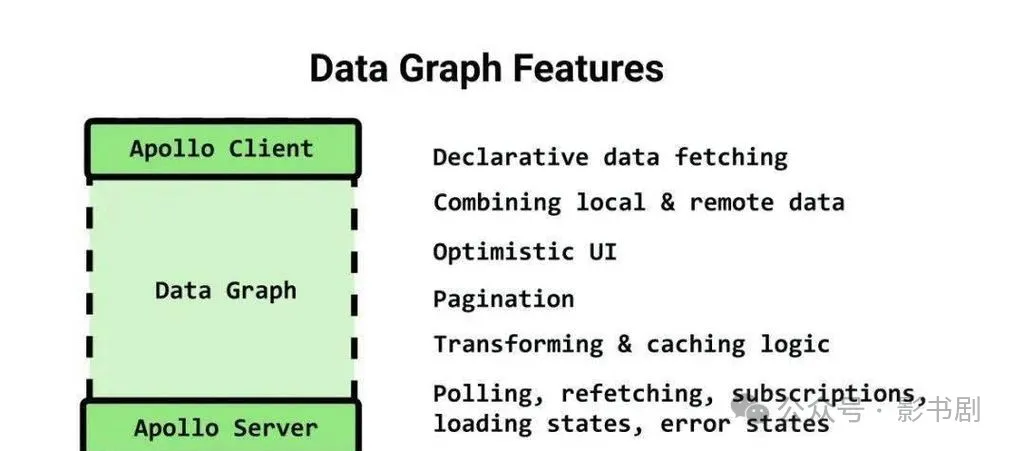
1.什么是GraphQL?
GraphQL是Facebook开发的一种API查询语言,它允许客户端明确指定需要的数据格式。
与传统的RESTAPI相比,它能让我们在一次请求中精确获取所需的数据,避免了过度获取(over-fetching)和数据获取不足(under-fetching)的问题。
2.搭建PythonGraphQL环境
首先我们需要安装必要的包。我们将使用graphene作为Python的GraphQL框架:
“`python pipinstallgraphene
3.定义Schema和类型
让我们通过一个简单的图书管理系统来学习GraphQL。首先定义数据类型:
python
复制
importgraphene
classBook(graphene.ObjectType): title=graphene.String() author=graphene.String() published_year=graphene.Int()
classAuthor(graphene.ObjectType): name=graphene.String() books=graphene.List(Book)
4.创建查询
接下来,我们来定义查询类:
python
复制
classQuery(graphene.ObjectType): book=graphene.Field(Book,title=graphene.String()) all_books=graphene.List(Book)
defresolve_book(self,info,title):
这里模拟数据库查询
returnBook( title=title, author=“向前”, published_year=2024 )
defresolve_all_books(self,info):
返回图书列表
return[ Book(title=“Python进阶”,author=“向前”,published_year=2024), Book(title=“GraphQL实战”,author=“向前”,published_year=2024) ]
schema=graphene.Schema(query=Query)
5.执行查询
现在让我们来执行一些查询:
python
复制
查询单本书
query=”’ query{ book(title:“Python进阶”){ title author publishedYear } } ”’
result=schema.execute(query) print(result.data)
小贴士:GraphQL的查询语句看起来很像JSON,但它有自己特殊的语法规则。字段名使用驼峰式命名规则(camelCase)。
6.添加变更(Mutation)
除了查询,我们还可以通过mutation来修改数据:
python
复制
classCreateBook(graphene.Mutation): classArguments: title=graphene.String() author=graphene.String() published_year=graphene.Int()
book=graphene.Field(Book)
defmutate(self,info,title,author,published_year): book=Book(title=title,author=author,published_year=published_year)
这里应该添加保存到数据库的代码
returnCreateBook(book=book)
classMutation(graphene.ObjectType): create_book=CreateBook.Field()
schema=graphene.Schema(query=Query,mutation=Mutation)
使用mutation添加新书:
python
复制
mutation=”’ mutation{ createBook(title:“GraphQL入门”,author:“向前”,publishedYear:2024){ book{ title author publishedYear } } } ”’
result=schema.execute(mutation) print(result.data)
7.实用技巧
1.错误处理:GraphQL会返回详细的错误信息,包括具体的字段和原因。
2.查询优化:可以使用only()和select_related()来优化数据库查询。
3.字段别名:可以给字段取别名,避免命名冲突:
python
复制
query=”’ query{ pythonBook:book(title:“Python进阶”){ title } graphqlBook:book(title:“GraphQL实战”){ title } } ”’
注意事项:
在生产环境中,记得添加适当的身份验证和权限控制 对查询的深度和复杂度进行限制,避免恶意查询 *合理使用数据加载器(DataLoader)来避免N+1查询问题
8.练习题
1.尝试给Book类型添加一个price字段,并修改相关的查询和变更操作 2.实现一个删除图书的mutation 3.添加一个按作者名查询所有图书的查询
小伙伴们,今天的Python学习之旅就到这里啦!
GraphQL确实是一个强大的API查询工具,它能让我们的数据获取更加精确和高效。
记得动手实践哦,有问题随时在评论区问向前。
祝大家学习愉快,Python学习节节高!
复制markdown
复制
PyGraphQL-API进阶:深入GraphQL的高级特性!
大家好,我是向前!上一篇文章我们学习了GraphQL的基础知识,今天让我们继续深入探索GraphQL在Python中的一些高级特性和实用技巧!
9.接口和联合类型
在GraphQL中,接口(Interface)和联合类型(Union)是两个非常实用的高级特性。
接口实现
“`python importgraphene
classHasAuthor(graphene.Interface): author=graphene.String() publish_date=graphene.String()
classArticle(graphene.ObjectType): classMeta: interfaces=(HasAuthor,)
title=graphene.String() content=graphene.String()
classBook(graphene.ObjectType): classMeta: interfaces=(HasAuthor,)
title=graphene.String() isbn=graphene.String()
联合类型
python
复制
classSearchResult(graphene.Union): classMeta: types=(Article,Book)
classQuery(graphene.ObjectType): search=graphene.List(SearchResult,keyword=graphene.String())
defresolve_search(self,info,keyword):
模拟搜索结果
results=[ Article( title=“GraphQL教程”, content=“GraphQL入门指南”, author=“向前”, publish_date=“2024-01-01” ), Book( title=“Python实战”, isbn=“123-456-789”, author=“向前”, publish_date=“2024-02-01” ) ] returnresults
10.数据加载优化
为了解决N+1查询问题,我们可以使用Promise和DataLoader:
python
复制
frompromiseimportPromise frompromise.dataloaderimportDataLoader
classBookLoader(DataLoader): defbatch_load_fn(self,keys):
模拟批量查询数据库
books=[ {“id”:k,“title”:f“Book{k}”,“author”:“向前”} forkinkeys ] returnPromise.resolve(books)
book_loader=BookLoader()
classQuery(graphene.ObjectType): books=graphene.List( Book, ids=graphene.List(graphene.ID) )
defresolve_books(self,info,ids): returnbook_loader.load_many(ids)
11.自定义标量类型
有时候我们需要自定义数据类型,比如日期或JSON:
python
复制
importjson fromgraphene.typesimportScalar fromdatetimeimportdatetime
classJSONScalar(Scalar): @staticmethod defserialize(dt): returnjson.dumps(dt)
@staticmethod defparse_literal(node): returnjson.loads(node.value)
@staticmethod defparse_value(value): returnjson.loads(value)
classDateTimeScalar(Scalar): @staticmethod defserialize(dt): returndt.isoformat()
@staticmethod defparse_value(value): returndatetime.fromisoformat(value)
classBook(graphene.ObjectType): metadata=JSONScalar() published_at=DateTimeScalar()
12.订阅功能
GraphQL还支持实时订阅功能,这在需要实时更新的场景非常有用:
python
复制
importasyncio fromgrapheneimportObjectType,Field,String
classSubscription(ObjectType): count=Field(String)
asyncdefresolve_count(root,info):
模拟实时数据流
foriinrange(5): yieldf“Count:{i}” awaitasyncio.sleep(1)
schema=graphene.Schema( query=Query, mutation=Mutation, subscription=Subscription )
13.中间件实现
中间件可以帮助我们处理认证、日志等通用逻辑:
python
复制
classAuthMiddleware: defresolve(self,next,root,info,args): ifnotinfo.context.get(‘is_authenticated’): raiseException(‘Authenticationrequired’) returnnext(root,info,args)
classLoggingMiddleware: defresolve(self,next,root,info,args): start=time.time() result=next(root,info,args) duration=time.time()-start print(f“Field{info.field_name}took{duration}storesolve”) returnresult
schema=graphene.Schema( query=Query, mutation=Mutation, middleware=[AuthMiddleware(),LoggingMiddleware()] )
14.性能优化小贴士
1.查询复杂度控制:
python
复制
fromgraphene.validationimportvalidate_max_depth
defvalidate_query(query_string): returnvalidate_max_depth(query_string,max_depth=5)
2.批量数据获取:
python
复制
classQuery(graphene.ObjectType): books=graphene.List( Book, first=graphene.Int(), offset=graphene.Int() )
defresolve_books(self,info,first=None,offset=None): books=get_books()#获取所有图书 ifoffsetisnotNone: books=books[offset:] iffirstisnotNone: books=books[:first] returnbooks
15.实用练习题
1.实现一个支持图书评论的系统,使用接口定义共同的用户行为 2.添加一个实时订阅功能,当有新书上架时通知订阅者 3.实现一个通用的缓存中间件,缓存查询结果
小贴士:
在使用DataLoader时,注意将loader实例存储在上下文中,避免创建多个实例 订阅功能需要使用支持异步的服务器,如FastAPI或Starlette *自定义标量类型时要考虑输入验证和错误处理
小伙伴们,今天的Python学习之旅就到这里啦!
我们学习了GraphQL的一些高级特性,相信这些知识会让你的API开发更上一层楼。
记得动手实践哦,有问题随时在评论区问向前。
祝大家学习愉快,Python学习节节高!
文章转自微信公众号@影书剧