

如何快速实现REST API集成以优化业务流程

您需要了解的一切,以及在 Colab 上运行 OpenAI 语音模式 API 的动手介绍。

OpenAI 最新的开发为我们带来了 实时 API,旨在允许开发者在他们的应用中创建 快速、无缝的语音到语音体验。该 API 旨在简化多模态对话功能的开发,使构建自然的实时语音交互变得更加容易。
在这篇博客中, 我将涵盖有关此新 API 的 主要问题,包括
实时 API 是 OpenAI 提供的公共测试功能,允许付费开发者在他们的应用中集成实时语音交互。它是一个多模态 API,能够将 音频输入转换为语音响应,并使用先进的 GPT-4o 模型来实现这一目的。本质上,它允许进行 低延迟对话,类似于自然的人际交互,类似于 ChatGPT 的高级语音模式中看到的功能。
之前,开发者需要将多个模型拼接在一起以实现 语音识别、文本处理和文本转语音生成。实时 API 将这一切都整合在一次 API 调用中,从而减少延迟,提供更丰富的响应,并更一致地处理口音和重音。
聊天完成 API 也引入了音频输入和输出,但它没有实时 API 的低延迟体验。因此,对于语言学习或语音启用助手等体验,实时 API 是更优选择。
对 Realtime API 的访问目前作为 公开测试版 提供给付费开发者。
虽然说在欧洲的访问受到限制,但我通过我的第5层OpenAI账户能够使用它。
该API使用 WebSocket 连接,确保音频输入和输出的流畅体验。
目前,需要注意以下 限制:
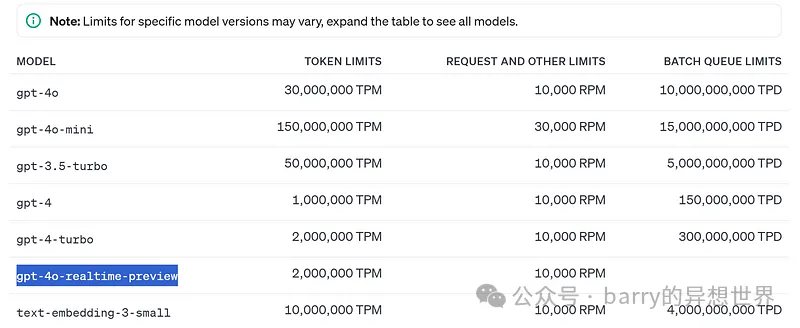
定价结构分为 文本令牌 和 音频令牌:
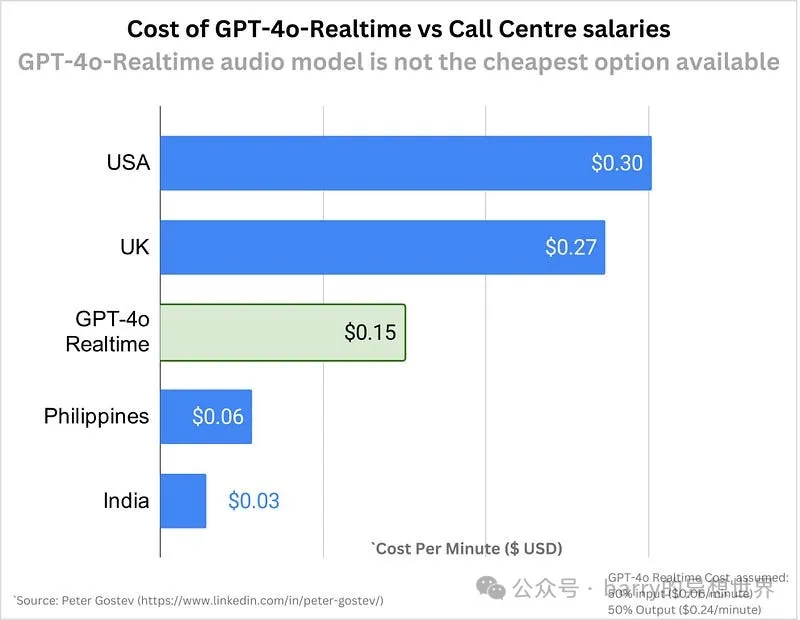
这一定价使得开发者能够负担得起创建强大的 语音到语音 体验,尽管音频功能的成本显著高于基于文本的交互。在扩展具有语音功能的应用时,这一点非常重要。
这仍然比外包给某些国家稍贵,但我们可以期待在接下来的六个月内价格会显著下降。
这是一个基本的 Colab 指南,帮助您开始上传文件、向 Realtime API 发送请求并生成音频响应。
在这个演示中,我们选择上传一系列音频片段,以模拟对话。
完整的 Colab 代码: 链接在这里,只需将您的 “openai” 密钥添加到 Colab 的秘密中并运行该 Colab。
#Setup
!pip install websockets pydub --quiet
import base64
import numpy as np
import soundfile as sf
import json
import websockets
from google.colab import files
from pydub import AudioSegment
from tqdm import tqdm
import io在 Colab 中,您可以使用 google.colab 的 files 模块来上传音频文件。
#Upload audio
def upload_audio():
uploaded = files.upload()
for file_name in uploaded.keys():
return file_name
audio_file = upload_audio()tqdm 显示上传流的进度。#Helper functions
## Function to convert Float32Array to PCM16 format
def float_to_pcm16(float32_array):
return np.clip(float32_array * 32767, -32768, 32767).astype(np.int16).tobytes()
## Function to split audio into base64-encoded PCM16 chunks
def float32_to_base64_chunks(float32_array, chunk_size=32000):
pcm16_data = float_to_pcm16(float32_array)
for i in range(0, len(pcm16_data), chunk_size):
yield base64.b64encode(pcm16_data[i:i+chunk_size]).decode('utf-8')
## WebSocket connection and streaming audio with text prompt
## Main function to call OpenAI Realtime API
async def stream_audio_to_realtime_api(audio_file, text_prompt, openai_key, verbose = False):
data, samplerate = sf.read(audio_file, dtype='float32')
if data.ndim > 1:
data = data[:, 0]
if samplerate != 24000:
raise ValueError(f"Audio must be sampled at 24kHz, but it is {samplerate}Hz")
url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01"
headers = {"Authorization": "Bearer " + openai_key, "OpenAI-Beta": "realtime=v1"}
async with websockets.connect(url, extra_headers=headers) as ws:
await ws.send(json.dumps({
"type": "conversation.item.create",
"item": {"type": "message", "role": "user", "content": [{"type": "input_text", "text": text_prompt}]}
}))
with tqdm(total=(len(float_to_pcm16(data)) + 32000 - 1) // 32000, desc="Sending Audio Chunks") as pbar:
for chunk in float32_to_base64_chunks(data):
await ws.send(json.dumps({"type": "input_audio_buffer.append", "audio": chunk}))
pbar.update(1)
await ws.send(json.dumps({"type": "input_audio_buffer.commit"}))
await ws.send(json.dumps({"type": "response.create"}))
all_events = []
while True:
response = await ws.recv()
event = json.loads(response)
all_events.append(event)
if verbose:
print(event)
if event["type"] == "response.output_item.done" and "item" in event and "content" in event["item"]:
for content in event["item"]["content"]:
if content["type"] == "audio" and "transcript" in content:
transcript = content["transcript"]
break
if event["type"] == "rate_limits.updated":
break
return all_events, transcript
#Add a prompt and call OpenAI Realtime API
text_prompt = "Summarize this audio content"
events, transcript = await stream_audio_to_realtime_api(
audio_file,
text_prompt,
openai_key,
verbose = False
#to display OpenAI's response as they arrive, use verbose = True
) ## Function to decode and concatenate audio chunks into a full audio file
def generate_audio_from_chunks(audio_chunks, output_filename=None):
# Concatenate the base64-encoded audio chunks from the 'delta' field
full_audio_base64 = ''.join(audio_chunks)
# Decode the concatenated base64 string to raw PCM16 audio bytes
audio_bytes = base64.b64decode(full_audio_base64)
# Load the bytes as a pydub AudioSegment (assuming 24kHz, 1 channel, PCM16)
audio_segment = AudioSegment.from_raw(
io.BytesIO(audio_bytes),
sample_width=2,
frame_rate=24000,
channels=1)
# Optionally save the audio to a file
if output_filename:
audio_segment.export(output_filename, format="wav")
print(f"Audio saved to {output_filename}")
return audio_segment#Extract audio chunks from the collected events
audio_output_chunks = [event['delta'] for event in events if event['type'] == 'response.audio.delta']
## Generate the full audio from the collected chunks
generated_audio = generate_audio_from_chunks(audio_output_chunks, output_filename="output_audioo.wav")通过上述步骤,您可以将 OpenAI 的实时 API 集成到 Colab 笔记本中,实现无缝的语音指令。
本指南应为您提供一个坚实的基础,以便您实验实时音频到音频的交互,并构建创新的语音驱动应用程序。
文章转自微信公众号@barry的异想世界






