

什么是GPT-4?完整指南

Fast RCNN,就是一种很经典的目标检测算法,它是在传统RCNN的基础上进行优化的,让目标检测变得更高效、更实用。要是你之前了解过RCNN,或者听说过目标检测这块的技术发展,那你肯定知道RCNN在当时有多震撼。它可以说是开启了深度学习在计算机视觉的新篇章,但RCNN也有它的短板,比如计算效率不高,处理大量候选区域时速度就成了大问题。正因如此,Fast RCNN就应运而生了,带来了很大的性能和速度提升。要弄懂Fast RCNN的创新点,咱们得先回顾一下RCNN是怎么工作的。RCNN它是这么个流程:先用选择性搜索算法找出好多候选区域,然后把这些区域放到预训练好的卷积神经网络里提取特征,接着用SVM分类器分类,再用回归模型优化一下边界框。但这方法有个毛病,就是每个候选区域都得单独跑一遍CNN来提取特征,不管图像里有多少候选区域,卷积层的特征都得重新算一遍,这就造成了很大的计算浪费。

Fast RCNN的厉害之处就在于它巧妙地避免了这种重复计算。跟传统RCNN不一样的是,Fast RCNN是先对整张图像做一次卷积运算,提取出共享的特征图,然后在这个特征图上用ROI池化层来提取每个候选区域的特征。这样一来,不仅计算时间大大缩短了,训练和测试的效率也提高了不少。在Fast RCNN里,每个候选区域经过ROI池化层后都会变成一个固定长度的特征向量,然后再送到全连接层进行分类和边界框回归。

Fast RCNN的ROI池化是它的一个核心组件,它将来自不同大小区域的特征映射转化为固定大小的特征图,以便进行后续分类和边界框回归。
class ROIPool(nn.Module):
def __init__(self, output_size=(7, 7)):
super(ROIPool, self).__init__()
self.output_size = output_size
def forward(self, feature_map, rois):
# rois 是一个形状为 (N, 4) 的 tensor,表示区域提议的边界框 (x1, y1, x2, y2)
batch_size = feature_map.size(0)
pooled_features = []
for i in range(batch_size):
# 对每个区域提议进行池化
for roi in rois:
x1, y1, x2, y2 = roi
roi_feature = feature_map[i, :, y1:y2, x1:x2]
pooled = F.adaptive_max_pool2d(roi_feature, self.output_size)
pooled_features.append(pooled)
# 将池化后的特征连接在一起
pooled_features = torch.cat(pooled_features, dim=0)
return pooled_features可以说,Fast RCNN的关键创新就是“共享特征提取”,这招儿彻底解决了RCNN中重复计算的问题。而且,Fast RCNN还用了一个更高效的损失函数,把分类损失和回归损失融合在一起,通过单独的网络结构来训练,这让整个训练过程更加高效了。Fast RCNN这种又快又准的目标检测方法,在实际应用中确实能大显身手。
我们可以使用预训练的 ResNet 或 VGG16 网络来提取卷积特征。在 Fast RCNN 中,我们仅使用卷积层部分,不需要全连接层。
class FastRCNNFeatureExtractor(nn.Module):
def __init__(self):
super(FastRCNNFeatureExtractor, self).__init__()
# 选择预训练的 ResNet50 模型
self.resnet = models.resnet50(pretrained=True)
# 去掉 ResNet 的全连接层,只保留卷积层
self.features = nn.Sequential(*list(self.resnet.children())[:-2])
def forward(self, x):
return self.features(x)总体的Fast RCNN实现如下:
class FastRCNN(nn.Module):
def __init__(self, num_classes, output_size=(7, 7)):
super(FastRCNN, self).__init__()
# 特征提取部分
self.feature_extractor = FastRCNNFeatureExtractor()
# ROI池化
self.roi_pool = ROIPool(output_size)
# 分类和边界框回归
self.fc_class = nn.Linear(2048 * output_size[0] * output_size[1], num_classes)
self.fc_bbox = nn.Linear(2048 * output_size[0] * output_size[1], 4)
def forward(self, x, rois):
# 提取图像特征
features = self.feature_extractor(x)
# 通过 ROI池化得到固定尺寸的特征
pooled_features = self.roi_pool(features, rois)
# 将特征展平并通过全连接层
pooled_features = pooled_features.view(pooled_features.size(0), -1)
# 分类任务
class_logits = self.fc_class(pooled_features)
# 边界框回归任务
bbox_pred = self.fc_bbox(pooled_features)
return class_logits, bbox_pred在训练 Fast RCNN 时,我们需要准备一个损失函数来训练模型。我们可以使用交叉熵损失(用于分类)和回归损失(用于边界框回归)。
# 定义交叉熵损失和边界框回归损失
def fast_rcnn_loss(class_logits, bbox_pred, labels, bbox_targets):
# 分类损失:交叉熵损失
class_loss = F.cross_entropy(class_logits, labels)
# 边界框回归损失:平滑L1损失
bbox_loss = F.smooth_l1_loss(bbox_pred, bbox_targets)
return class_loss + bbox_loss完整的训练流程:
def train(model, dataloader, optimizer, num_epochs=10):
model.train()
for epoch in range(num_epochs):
for images, rois, labels, bbox_targets in dataloader:
# 将输入转换为 torch.Tensor
images = Variable(images).cuda()
rois = Variable(rois).cuda()
labels = Variable(labels).cuda()
bbox_targets = Variable(bbox_targets).cuda()
# 前向传播
class_logits, bbox_pred = model(images, rois)
# 计算损失
loss = fast_rcnn_loss(class_logits, bbox_pred, labels, bbox_targets)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch}/{num_epochs}], Loss: {loss.item()}")
def test(model, dataloader):
model.eval()
with torch.no_grad():
for images, rois, labels, bbox_targets in dataloader:
# 测试时的前向传播
images = Variable(images).cuda()
rois = Variable(rois).cuda()
class_logits, bbox_pred = model(images, rois)
# 获取最大概率类作为预测结果
_, predicted_classes = torch.max(class_logits, 1)
# 在这里可以进一步进行评估和计算准确率、IoU等数据加载(伪代码):
from torch.utils.data import DataLoader, Dataset
class CustomDataset(Dataset):
def __init__(self, image_paths, rois, labels, bbox_targets):
self.image_paths = image_paths
self.rois = rois
self.labels = labels
self.bbox_targets = bbox_targets
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image = cv2.imread(self.image_paths[idx]) # 读取图片
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = image.transpose(2, 0, 1) # 调整为 CxHxW 格式
image = torch.tensor(image, dtype=torch.float32)
rois = self.rois[idx] # 区域提议
labels = self.labels[idx] # 目标类别标签
bbox_targets = self.bbox_targets[idx] # 边界框回归目标
return image, rois, labels, bbox_targets测试模型:
# 初始化模型和优化器
model = FastRCNN(num_classes=21) # 假设有21个类(包括背景)
model.cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
# 初始化数据加载器
train_dataset = CustomDataset(image_paths, rois, labels, bbox_targets)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
# 训练模型
train(model, train_loader, optimizer)
# 测试模型
test(model, test_loader)不过嘛,Fast RCNN虽说提高了效率,但候选区域生成这事儿还是个难题。选择性搜索这个过程耗时比较长,尤其是在处理大规模图像数据集的时候。为了进一步提升目标检测的速度和精度,研究者们就继续想办法,这时候Faster RCNN就横空出世了。
Faster RCNN可不是简单地对之前的版本做了点小修小补,而是彻底改变了整个模型的架构,让计算速度和准确性都得到了质的飞跃。你可能听说过RCNN和Fast RCNN,它们都是通过一个个提取图像区域特征来做目标检测的,但有个大问题——效率太低了,尤其是在生成候选区域的时候。想当初,RCNN得靠选择性搜索来生成候选区域,那个过程慢得让人抓狂。Fast RCNN虽然优化了特征共享,但还是得依赖外部的候选区域生成方法,计算上还是不够快。虽然这些模型在目标检测上都表现得不错,但训练和测试的速度还是跟不上实际应用的需求。

那么,Faster RCNN是怎么解决这些问题的呢?关键就在于它引入了一个叫区域提议网络(RPN)的东西。RPN就像是一个能直接从卷积特征图中生成候选区域的深度学习网络。有了它,Faster RCNN就不需要依赖那些复杂的选择性搜索算法了,自己就能高效地生成候选区域,而且这个过程是可以端到端训练的。简单来说,Faster RCNN不仅在计算速度上快了很多,检测的准确性也有所提高。
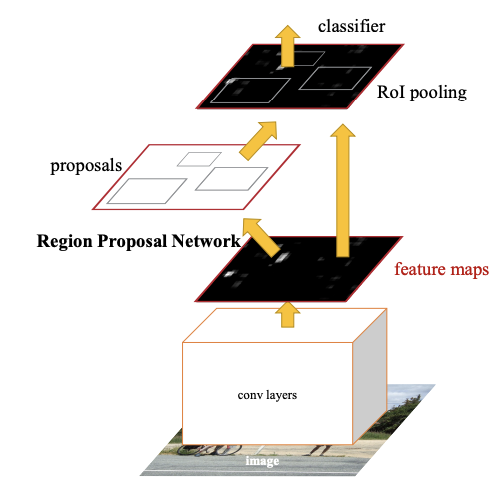
从Fast RCNN到Faster RCNN,这中间的关键变化就是RPN的引入。RPN利用卷积神经网络学习怎么生成高质量的区域提议,并且还能通过回归的方法调整边界框,让候选区域的位置更加准确。这个过程完全融入到了目标检测的网络里,实现了端到端的训练。对开发者来说,这就意味着可以用一个统一的框架来训练,不用来回传输数据和模型,提高了模型的精度和运行效率。
咱们再深入聊聊Faster RCNN的架构和工作原理。
首先,Faster RCNN用的卷积网络(比如ResNet或VGG)负责从输入图像中提取深度特征。这些特征图不仅用来做目标检测,还是生成候选区域的基础。

然后,RPN网络接过这个活儿,通过对这些特征图进行卷积操作,生成一组候选区域。你可以把RPN想象成在图像上滑一个小窗口,这个窗口会为每个位置生成一组框,表示可能存在物体的位置和大小。
为了更准确地生成这些框,RPN还会根据每个框里有没有目标物体来做出判断,并通过边界框回归来进一步调整框的位置。

这里有个关键点,RPN会通过一个简单的二分类网络来判断每个候选区域里有没有目标物体。这么做的好处是,它把区域提议的生成和目标检测任务放在了同一个网络里,这样就不需要像Fast RCNN那样依赖选择性搜索了,同时也让模型能更好地理解目标物体的上下文,生成更准确的区域提议。
RPN的实现参考:
class RPN(nn.Module):
_feat_stride = [16, ]
anchor_scales = [8, 16, 32]
def __init__(self):
super(RPN, self).__init__()
self.features = VGG16(bn=False)
self.conv1 = Conv2d(512, 512, 3, same_padding=True)
self.score_conv = Conv2d(512, len(self.anchor_scales) * 3 * 2, 1, relu=False, same_padding=False)
self.bbox_conv = Conv2d(512, len(self.anchor_scales) * 3 * 4, 1, relu=False, same_padding=False)
# loss
self.cross_entropy = None
self.los_box = None
@property
def loss(self):
return self.cross_entropy + self.loss_box * 10
def forward(self, im_data, im_info, gt_boxes=None, gt_ishard=None, dontcare_areas=None):
im_data = network.np_to_variable(im_data, is_cuda=True)
im_data = im_data.permute(0, 3, 1, 2)
features = self.features(im_data)
rpn_conv1 = self.conv1(features)
# rpn score
rpn_cls_score = self.score_conv(rpn_conv1)
rpn_cls_score_reshape = self.reshape_layer(rpn_cls_score, 2)
rpn_cls_prob = F.softmax(rpn_cls_score_reshape)
rpn_cls_prob_reshape = self.reshape_layer(rpn_cls_prob, len(self.anchor_scales)*3*2)
# rpn boxes
rpn_bbox_pred = self.bbox_conv(rpn_conv1)
# proposal layer
cfg_key = 'TRAIN' if self.training else 'TEST'
rois = self.proposal_layer(rpn_cls_prob_reshape, rpn_bbox_pred, im_info,
cfg_key, self._feat_stride, self.anchor_scales)
# generating training labels and build the rpn loss
if self.training:
assert gt_boxes is not None
rpn_data = self.anchor_target_layer(rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas,
im_info, self._feat_stride, self.anchor_scales)
self.cross_entropy, self.loss_box = self.build_loss(rpn_cls_score_reshape, rpn_bbox_pred, rpn_data)
return features, rois
def build_loss(self, rpn_cls_score_reshape, rpn_bbox_pred, rpn_data):
# classification loss
rpn_cls_score = rpn_cls_score_reshape.permute(0, 2, 3, 1).contiguous().view(-1, 2)
rpn_label = rpn_data[0].view(-1)
rpn_keep = Variable(rpn_label.data.ne(-1).nonzero().squeeze()).cuda()
rpn_cls_score = torch.index_select(rpn_cls_score, 0, rpn_keep)
rpn_label = torch.index_select(rpn_label, 0, rpn_keep)
fg_cnt = torch.sum(rpn_label.data.ne(0))
rpn_cross_entropy = F.cross_entropy(rpn_cls_score, rpn_label)
# box loss
rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = rpn_data[1:]
rpn_bbox_targets = torch.mul(rpn_bbox_targets, rpn_bbox_inside_weights)
rpn_bbox_pred = torch.mul(rpn_bbox_pred, rpn_bbox_inside_weights)
rpn_loss_box = F.smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, size_average=False) / (fg_cnt + 1e-4)
return rpn_cross_entropy, rpn_loss_box
@staticmethod
def reshape_layer(x, d):
input_shape = x.size()
# x = x.permute(0, 3, 1, 2)
# b c w h
x = x.view(
input_shape[0],
int(d),
int(float(input_shape[1] * input_shape[2]) / float(d)),
input_shape[3]
)
# x = x.permute(0, 2, 3, 1)
return x
@staticmethod
def proposal_layer(rpn_cls_prob_reshape, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchor_scales):
rpn_cls_prob_reshape = rpn_cls_prob_reshape.data.cpu().numpy()
rpn_bbox_pred = rpn_bbox_pred.data.cpu().numpy()
x = proposal_layer_py(rpn_cls_prob_reshape, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchor_scales)
x = network.np_to_variable(x, is_cuda=True)
return x.view(-1, 5)
@staticmethod
def anchor_target_layer(rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas, im_info, _feat_stride, anchor_scales):
"""
rpn_cls_score: for pytorch (1, Ax2, H, W) bg/fg scores of previous conv layer
gt_boxes: (G, 5) vstack of [x1, y1, x2, y2, class]
gt_ishard: (G, 1), 1 or 0 indicates difficult or not
dontcare_areas: (D, 4), some areas may contains small objs but no labelling. D may be 0
im_info: a list of [image_height, image_width, scale_ratios]
_feat_stride: the downsampling ratio of feature map to the original input image
anchor_scales: the scales to the basic_anchor (basic anchor is [16, 16])
----------
Returns
----------
rpn_labels : (1, 1, HxA, W), for each anchor, 0 denotes bg, 1 fg, -1 dontcare
rpn_bbox_targets: (1, 4xA, H, W), distances of the anchors to the gt_boxes(may contains some transform)
that are the regression objectives
rpn_bbox_inside_weights: (1, 4xA, H, W) weights of each boxes, mainly accepts hyper param in cfg
rpn_bbox_outside_weights: (1, 4xA, H, W) used to balance the fg/bg,
beacuse the numbers of bgs and fgs mays significiantly different
"""
rpn_cls_score = rpn_cls_score.data.cpu().numpy()
rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = \
anchor_target_layer_py(rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas, im_info, _feat_stride, anchor_scales)
rpn_labels = network.np_to_variable(rpn_labels, is_cuda=True, dtype=torch.LongTensor)
rpn_bbox_targets = network.np_to_variable(rpn_bbox_targets, is_cuda=True)
rpn_bbox_inside_weights = network.np_to_variable(rpn_bbox_inside_weights, is_cuda=True)
rpn_bbox_outside_weights = network.np_to_variable(rpn_bbox_outside_weights, is_cuda=True)
return rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights
def load_from_npz(self, params):
# params = np.load(npz_file)
self.features.load_from_npz(params)
pairs = {'conv1.conv': 'rpn_conv/3x3', 'score_conv.conv': 'rpn_cls_score', 'bbox_conv.conv': 'rpn_bbox_pred'}
own_dict = self.state_dict()
for k, v in pairs.items():
key = '{}.weight'.format(k)
param = torch.from_numpy(params['{}/weights:0'.format(v)]).permute(3, 2, 0, 1)
own_dict[key].copy_(param)
key = '{}.bias'.format(k)
param = torch.from_numpy(params['{}/biases:0'.format(v)])
own_dict[key].copy_(param)当RPN生成了候选区域后,这些区域就会进入Fast RCNN进行最后的分类和边界框回归。这个过程和Fast RCNN里很像,只不过现在用的候选区域是RPN自己生成的,所以整个流程更高效,训练和测试的时间也大大缩短了。
你可能会问,为什么RPN这么重要,能提高检测精度呢?这跟它生成区域提议的方式有关。传统的方法(如选择性搜索)通过图像分割和聚类来生成区域,虽然有效,但没有利用到深度网络的强大特征提取能力。而RPN是通过卷积神经网络直接在特征图上滑动窗口来生成区域的,它不仅能在不同尺度上做出准确的判断,还能通过回归来不断优化候选区域的位置。这样一来,RPN生成的候选区域质量更高,还能捕捉到更多细节。
那Faster RCNN的具体架构是怎样的呢?简单来说,它包括以下几个部分:
Faster RCNN的训练是通过联合损失函数来实现的,包括分类损失和边界框回归损失。分类损失用的是交叉熵损失函数,回归损失用的是平滑L1损失。这两个损失函数的结合确保了模型既能准确预测物体类别,又能精确定位物体位置。
下面给一个Faster RCNN的调用例子:
import torch
import torchvision
import torchvision.transforms as T
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.datasets import VOCDetection
# 定义数据预处理函数
def get_transform():
# 预处理包括将图像转换为 tensor 和进行标准化
return T.Compose([
T.ToTensor(),
])
# 下载 PASCAL VOC 数据集并定义训练集
train_dataset = VOCDetection(root='./data', year='2012', image_set='train', download=True, transform=get_transform())
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=4)
# 加载预训练的 Faster RCNN 模型
model = fasterrcnn_resnet50_fpn(pretrained=True)
# 需要修改模型以适应 VOC 数据集(类别数为 21)
num_classes = 21 # VOC 数据集类别数(包括背景)
in_features = model.roi_heads.box_predictor.cls_score.in_features
# 替换最后一层分类头,以适应 VOC 数据集
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# 使用 SGD 优化器
optimizer = optim.SGD(model.parameters(), lr=0.005, momentum=0.9, weight_decay=0.0005)
# 定义训练函数
def train(model, dataloader, optimizer, num_epochs=10):
model.train()
for epoch in range(num_epochs):
for images, targets in dataloader:
# 将输入数据移动到 GPU
images = [image.cuda() for image in images]
targets = [{k: v.cuda() for k, v in t.items()} for t in targets]
# 清空梯度
optimizer.zero_grad()
# 前向传播
loss_dict = model(images, targets)
# 计算总损失
losses = sum(loss for loss in loss_dict.values())
# 反向传播
losses.backward()
# 更新模型参数
optimizer.step()
# 输出当前的损失
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {losses.item()}")
# 训练模型
model.cuda()
train(model, train_loader, optimizer, num_epochs=5)
# 定义测试函数
def test(model, dataloader):
model.eval()
with torch.no_grad():
for images, targets in dataloader:
images = [image.cuda() for image in images]
# 获得模型的预测结果
prediction = model(images)
# 可视化检测结果
for i in range(len(images)):
image = images[i].cpu().numpy().transpose(1, 2, 0)
plt.imshow(image)
boxes = prediction[i]['boxes'].cpu().numpy()
labels = prediction[i]['labels'].cpu().numpy()
scores = prediction[i]['scores'].cpu().numpy()
# 筛选出得分较高的预测框
high_score_idx = scores > 0.5
boxes = boxes[high_score_idx]
labels = labels[high_score_idx]
for box in boxes:
plt.gca().add_patch(plt.Rectangle((box[0], box[1]), box[2] - box[0], box[3] - box[1],
fill=False, color='red', linewidth=2))
plt.show()
# 使用测试集进行评估
test(model, train_loader)在实际应用中,Faster RCNN的速度和精度都很不错。它在COCO和PASCAL VOC等数据集上表现优异,特别是在高精度目标检测任务中,经常成为基准模型。比如在COCO数据集上,Faster RCNN的mAP能达到36.2%以上,在PASCAL VOC上的表现也很棒。
总的来说,Faster RCNN解决了目标检测中的很多关键问题,让速度和精度都有了很大的提升。它不再依赖传统的候选区域生成方法,而是通过RPN实现了端到端的训练,效率大大提高。虽然Faster RCNN已经很成熟了,但在实时检测和大规模数据集上还有提升的空间。随着技术的发展,相信目标检测模型会越来越好。每一次算法的进步,都是对计算能力、数据处理、网络架构等多方面的深入理解和优化的结果。相信在未来,目标检测会变得更加智能、更加高效!
本文章转载微信公众号@Chal1ceAI










