从入门到实践:如何利用Stacking集成多种机器学习算法提高模型性能
背景
在机器学习领域,通常会接触到多种回归或分类模型,但单一模型的性能可能受限于算法本身的特点。如何整合多个模型的优势,进一步提升模型性能?Stacking(堆叠)技术便应运而生,本文通过一个实际案例,深入浅出地讲解如何使用Stacking进行模型构建。
什么是Stacking?
Stacking(堆叠)是机器学习中一种集成学习的方法,它通过结合多个模型的预测结果,从而提高整体的预测性能,相比简单的平均或投票法,Stacking更灵活,能够学习更复杂的组合方式。
核心思想
- 多模型融合:同时使用多个不同的基学习器(Base Learners),每个模型对同一任务进行预测。
- 元学习器(Meta Learner):使用一个额外的模型(通常是简单模型,如线性回归或逻辑回归)来学习如何将这些基学习器的预测结果进行最优组合。
实现流程
- 第一层:基学习器的训练,使用训练数据训练多个基学习器,例如决策树、支持向量机、神经网络等,每个基学习器独立工作,生成预测结果。
- 生成元数据集:将基学习器对训练集的预测结果作为新的特征,生成一个“元数据集”,元数据集的标签仍然是原始训练数据的标签。
- 第二层:训练元学习器,使用元数据集训练一个元学习器,它学会如何组合基学习器的预测结果。
- 最终预测:在测试阶段,基学习器对测试数据进行预测,并将预测结果输入到元学习器中,输出最终的预测结果。
关键点与优缺点
Stacking的核心在于结合多个基学习器的预测结果,通过元学习器进行优化以提升整体性能。其关键点包括:使用不同类型的基学习器(异质性)来提高模型多样性和泛化能力;通过交叉验证避免数据泄漏,确保元数据集的独立性;选择简单且稳定的元学习器(如逻辑回归、线性回归等)来组合基学习器的输出,优点在于通过模型的互补性提升预测效果,适用于复杂任务;但缺点是需要较高的计算资源,并增加了调参复杂度和时间成本。

代码实现
数据读取
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('2024-12-06公众号Python机器学习AI.xlsx')
from sklearn.model_selection import train_test_split, KFold
X = df.drop(['Y'],axis=1)
y = df['Y']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
random_state=42)导入必要的库,读取一个包含特征X和目标变量Y的Excel数据集,将其分成训练集和测试集,目标是构建回归模型进行预测,其中特征X和目标变量Y是针对回归任务设计的。
构建多模型融合的Stacking回归器
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, AdaBoostRegressor, StackingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
from sklearn.linear_model import LinearRegression
# 定义一级学习器
base_learners = [
("RF", RandomForestRegressor(n_estimators=100, random_state=42)),
("XGB", XGBRegressor(n_estimators=100, random_state=42, verbosity=0)),
("LGBM", LGBMRegressor(n_estimators=100, random_state=42, verbose=-1)),
("GBM", GradientBoostingRegressor(n_estimators=100, random_state=42)),
("AdaBoost", AdaBoostRegressor(n_estimators=100, random_state=42)),
("CatBoost", CatBoostRegressor(n_estimators=100, random_state=42, verbose=0))
]
# 定义二级学习器
meta_model = LinearRegression()
# 创建Stacking回归器
stacking_regressor = StackingRegressor(estimators=base_learners, final_estimator=meta_model, cv=5)
# 训练模型
stacking_regressor.fit(X_train, y_train)
通过集成学习中的Stacking方法,结合多种回归模型(包括随机森林、XGBoost、LightGBM、Gradient Boosting、AdaBoost 和 CatBoost)作为一级学习器,利用线性回归作为二级元学习器,学习各模型预测的最佳组合方式。最终通过5折交叉验证优化模型性能,并在训练数据上训练Stacking回归器,以提升整体的回归预测效果。
如果将代码用于分类模型,主要变化如下:
模型选择:将所有的回归模型替换为对应的分类模型,例如:
RandomForestRegressor→RandomForestClassifier
GradientBoostingRegressor→GradientBoostingClassifier
AdaBoostRegressor→AdaBoostClassifier
XGBRegressor→XGBClassifier
LGBMRegressor→LGBMClassifier
CatBoostRegressor→CatBoostClassifier
元学习器:将LinearRegression替换为适合分类任务的模型,如LogisticRegression或其他分类器,目标变量(y):确保 y 是分类标签而非连续值,StackingClassifier:使用StackingClassifier而不是StackingRegressor。
模型性能评价
from sklearn import metrics
# 真实值
y_train_true = y_train.values
y_test_true = y_test.values
# 预测值
y_pred_train = stacking_regressor.predict(X_train)
y_pred_test = stacking_regressor.predict(X_test)
# 计算训练集的指标
mse_train = metrics.mean_squared_error(y_train_true, y_pred_train)
rmse_train = np.sqrt(mse_train)
mae_train = metrics.mean_absolute_error(y_train_true, y_pred_train)
r2_train = metrics.r2_score(y_train_true, y_pred_train)
# 计算测试集的指标
mse_test = metrics.mean_squared_error(y_test_true, y_pred_test)
rmse_test = np.sqrt(mse_test)
mae_test = metrics.mean_absolute_error(y_test_true, y_pred_test)
r2_test = metrics.r2_score(y_test_true, y_pred_test)
# 输出结果
print("训练集评价指标:")
print("均方误差 (MSE):", mse_train)
print("均方根误差 (RMSE):", rmse_train)
print("平均绝对误差 (MAE):", mae_train)
print("拟合优度 (R-squared):", r2_train)
print("n测试集评价指标:")
print("均方误差 (MSE):", mse_test)
print("均方根误差 (RMSE):", rmse_test)
print("平均绝对误差 (MAE):", mae_test)
print("拟合优度 (R-squared):", r2_test) 全面评估模型在训练集和测试集上的回归性能,帮助判断模型的拟合程度和泛化能力,从结果可以看出,模型在训练集上的性能非常好( =0.96误差较小),但在测试集上性能有所下降( =0.83误差增大),这表明模型存在一定的过拟合,即在训练数据上表现很好,但在未见数据上泛化能力稍弱。
全面评估模型在训练集和测试集上的回归性能,帮助判断模型的拟合程度和泛化能力,从结果可以看出,模型在训练集上的性能非常好( =0.96误差较小),但在测试集上性能有所下降( =0.83误差增大),这表明模型存在一定的过拟合,即在训练数据上表现很好,但在未见数据上泛化能力稍弱。
不过,这里主要的目标是演示 Stacking 回归器的实现,因此对模型的具体参数(如基学习器和元学习器的超参数)未进行调优,而是采用了默认配置。这种实现方式更侧重于让读者理解Stacking的工作机制,而不是追求最佳的模型性能。如果要进一步改进,可以针对基学习器和元学习器的超参数进行优化,或引入正则化手段来减少过拟合问题。
可视化模型预测结果

通过散点图和拟合线结合置信区间、直方图,全面可视化Stacking回归模型在训练集和测试集上的预测表现,旨在直观展示模型的拟合质量、预测误差分布以及与真实值的匹配情况。
单模型预测性能评估:多算法对比分析
from sklearn.model_selection import cross_val_score
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, explained_variance_score
# 初始化结果存储列表
train_results = []
test_results = []
# 修改 evaluate_model 函数,分别存储训练集和测试集的评价指标
def evaluate_model(model_name, model, X_train, y_train, X_test, y_test, cv=5):
# K折交叉验证
kf = KFold(n_splits=cv, shuffle=True, random_state=42)
cv_scores = cross_val_score(model, X_train, y_train, cv=kf, scoring='r2')
mean_cv_r2 = np.mean(cv_scores)
std_cv_r2 = np.std(cv_scores)
# 训练模型
model.fit(X_train, y_train)
# 测试集预测
y_pred_test = model.predict(X_test)
# 训练集预测
y_pred_train = model.predict(X_train)
# 测试集指标
r2_test = r2_score(y_test, y_pred_test)
rmse_test = mean_squared_error(y_test, y_pred_test, squared=False)
mae_test = mean_absolute_error(y_test, y_pred_test)
mape_test = np.mean(np.abs((y_test - y_pred_test) / y_test)) if np.all(y_test != 0) else np.nan
ev_test = explained_variance_score(y_test, y_pred_test)
test_results.append({
"CV Mean R²": mean_cv_r2,
"CV Std R²": std_cv_r2,
"R²": r2_test,
"RMSE": rmse_test,
"MAE": mae_test,
"MAPE": mape_test,
"EV": ev_test,
"Model": model_name
})
# 训练集指标
r2_train = r2_score(y_train, y_pred_train)
rmse_train = mean_squared_error(y_train, y_pred_train, squared=False)
mae_train = mean_absolute_error(y_train, y_pred_train)
mape_train = np.mean(np.abs((y_train - y_pred_train) / y_train)) if np.all(y_train != 0) else np.nan
ev_train = explained_variance_score(y_train, y_pred_train)
train_results.append({
"R²": r2_train,
"RMSE": rmse_train,
"MAE": mae_train,
"MAPE": mape_train,
"EV": ev_train,
"Model": model_name
})
# 单独训练每个模型
evaluate_model("Random Forest", RandomForestRegressor(random_state=42), X_train, y_train, X_test, y_test)
evaluate_model("XGBoost", XGBRegressor(random_state=42, verbosity=0), X_train, y_train, X_test, y_test)
evaluate_model("LightGBM", LGBMRegressor(random_state=42, verbose=-1), X_train, y_train, X_test, y_test)
evaluate_model("Gradient Boosting", GradientBoostingRegressor(random_state=42), X_train, y_train, X_test, y_test)
evaluate_model("AdaBoost", AdaBoostRegressor(random_state=42), X_train, y_train, X_test, y_test)
evaluate_model("CatBoost", CatBoostRegressor(random_state=42, verbose=0), X_train, y_train, X_test, y_test)
train_results_df = pd.DataFrame(train_results)
train_results_df “`
“`
test_results_df = pd.DataFrame(test_results)
test_results_df
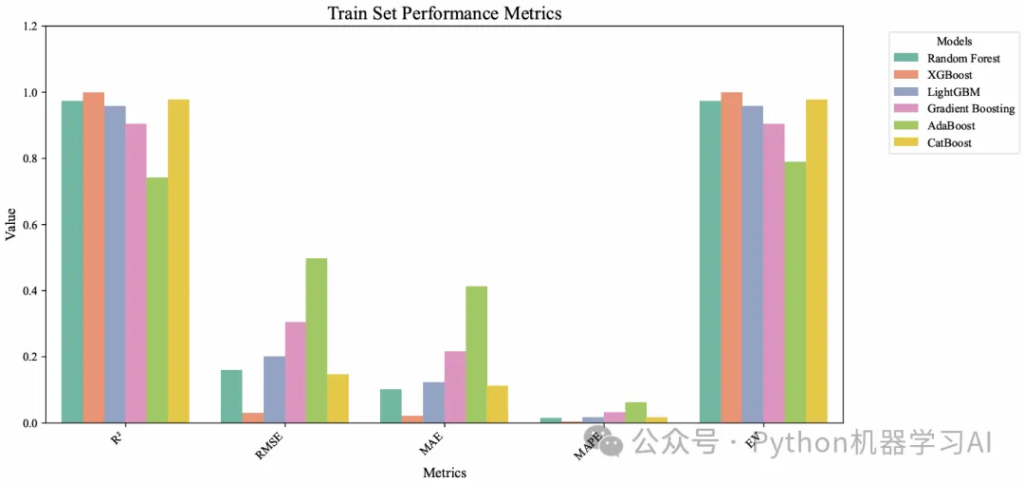
 和 CatBoost),分别在训练集和测试集上评估单一模型的预测性能,通过计算 R^2、RMSE、MAE、MAPE 和解释方差等指标,为单一模型提供基准性能,用于对比 Stacking 模型是否通过融合多模型的优势显著提升了预测精度和稳定性,接下来对这些评价指标进行一个简单的可视化。import seaborn as sns
def plot_model_performance(results_df, dataset_type="Train", save_path=None):
colors = sns.color_palette("Set2", len(results_df))
long_format = results_df.melt(
id_vars=["Model"],
var_name="Metric",
value_name="Value"
)
plt.figure(figsize=(12, 6))
sns.barplot(data=long_format, x="Metric", y="Value", hue="Model", palette=colors)
plt.title(f"{dataset_type} Set Performance Metrics", fontsize=16)
plt.ylabel("Value", fontsize=12)
plt.xlabel("Metrics", fontsize=12)
plt.xticks(rotation=45, ha="right")
plt.ylim(0, 1.2)设置Y轴范围,确保留白
plt.legend(title="Models", bbox_to_anchor=(1.05, 1), loc='upper left', fontsize=10)
if save_path:
plt.savefig(save_path, format="pdf", bbox_inches="tight", dpi=300)
plt.tight_layout()
plt.show()绘制训练集指标可视化
plot_model_performance(train_results_df, dataset_type="Train", save_path="train_metrics.pdf")
 ```
# 绘制测试集指标可视化
plot_model_performance(test_results_df.iloc[:,2::], dataset_type="Test", save_path="test_metrics.pdf") 通过绘制柱状图直观对比单一模型之间在训练集和测试集上的性能指标,在单一模型和Stacking模型相比,特别是测试集上的评价指标如R^2、RMSE、MAE 和 MAPE,总体来看,Stacking 模型的性能普遍优于单一模型,尤其在R^2和 RMSE等关键指标上表现更优,显示出更强的泛化能力。然而,也有个别单一模型(如XGBoost或LightGBM)在测试集上的表现接近 Stacking,但Stacking依然稍胜一筹。
通过绘制柱状图直观对比单一模型之间在训练集和测试集上的性能指标,在单一模型和Stacking模型相比,特别是测试集上的评价指标如R^2、RMSE、MAE 和 MAPE,总体来看,Stacking 模型的性能普遍优于单一模型,尤其在R^2和 RMSE等关键指标上表现更优,显示出更强的泛化能力。然而,也有个别单一模型(如XGBoost或LightGBM)在测试集上的表现接近 Stacking,但Stacking依然稍胜一筹。