

如何快速实现REST API集成以优化业务流程

在AIGC时代,Stable Diffusion无疑是其中最亮的“仔”,它是一个强大的文本条件隐式扩散模型(text-conditioned latent diffusion model),可以根据文字描述(也称为Prompt)生成精美图片。
对于基于transformer的大模型来说,self-attention的计算复杂度与输入数据是平方关系的,比如一张128X128像素的图片在像素数量上是64X64像素图片的4倍,内存和计算量是16倍。这正是高分辨率图像生成任务存在的普遍现象。
为了解决这个问题,提出了隐式扩散(Latent Diffusion)方法,该方法认为图片通常包含大量冗余信息,首先使用大量图片数据训练一个Variational Auto-Encode(VAE)模型,编码器将图片映射到一个较小的隐式表示,解码器可以将较小的隐式表示映射到原始图片。Stable Diffusion中的VAE接受一张3通道图片作为输入,生成一个4通道的隐式特征,同时每一个空间维度都将减少为原来的八分之一。例如,一张512X512像素的图片可以被压缩到一个4X64X64的隐式表示。
通过在隐式表示(而不是完整图像)上进行扩散,可以使用更少的内存也可以减少UNet层数,从而加速图片生成,极大降低了训练和推理成本。
隐式扩散的结构,如下图所示:
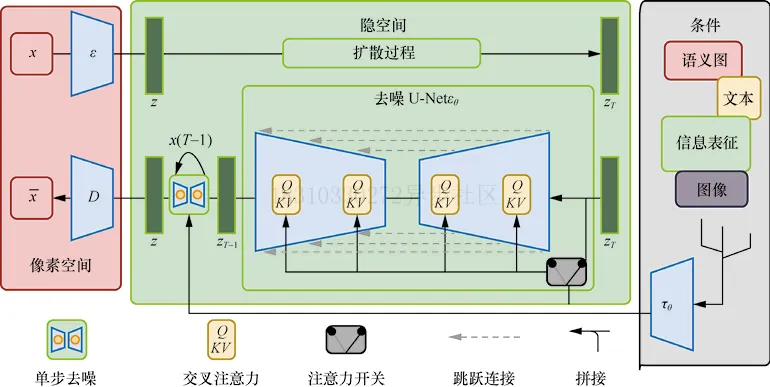
前面的章节展示了如何将额外信息输入给UNet,以实现对生成图像的控制,这种方法称为条件生成。以文本为条件进行控制图像的生成是在推理阶段,我们可以输入期望图像的文本描述(Prompt),并把纯噪声数据作为起点,然后模型对噪声数据进行“去噪”,从而生成能够匹配文本描述的图像。那么这个过程是如何实现的呢?
我们需要对文本进行编码表示,然后输入给UNet作为生成条件,文本嵌入表示如下图ENCODER_HIDDEN_STATES
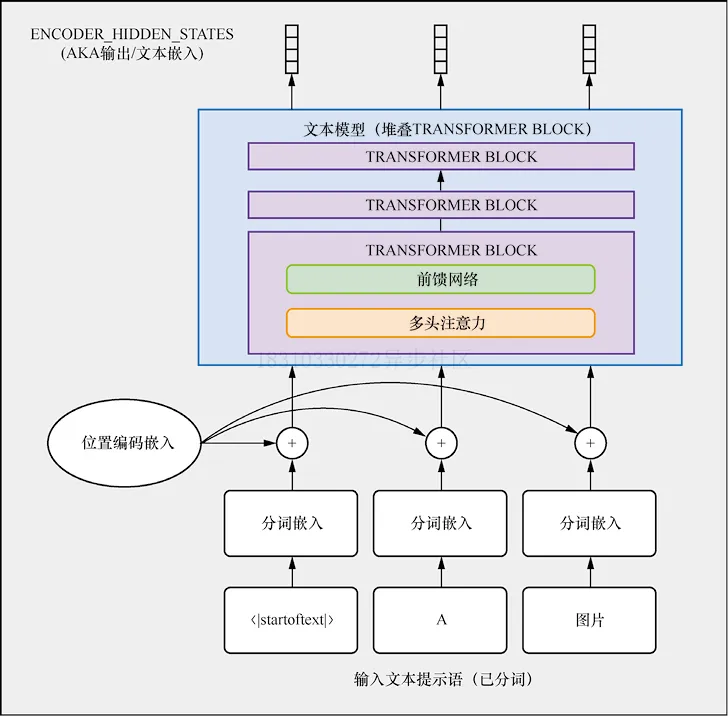
Stable Diffusion使用CLIP对文本描述进行编码,首先对输入文本描述进行分词,然后输入给CLIP文本编码器,从而为每个token产生一个768维(Stable Diffusion 1.x版本)或者1024维(Stable Diffusion 2.x版本)向量,为了使输入格式一致,文本描述总是被补全或者截断为77个token。
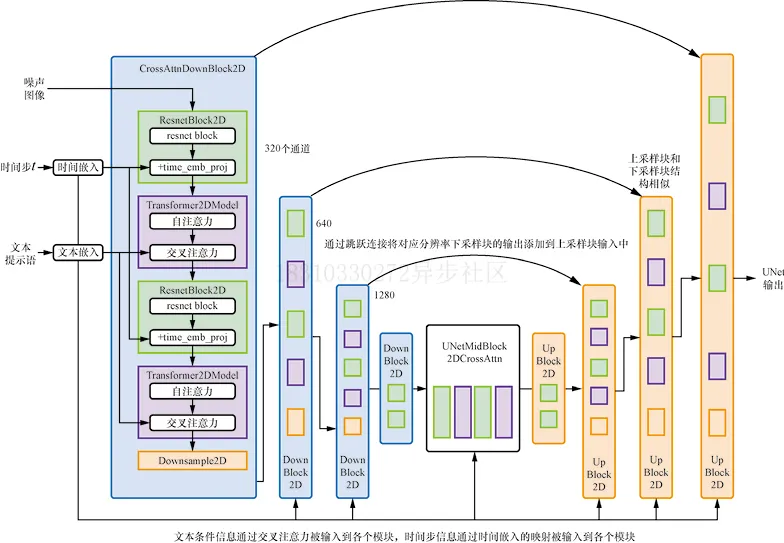
那么,如何将这些条件信息输入给UNet进行预测呢?答案是使用交叉注意力(cross-attention)机制。UNet网络中的每个空间位置都可以与文本条件中的不同token建立注意力(在稍后的代码中可以看到具体的实现),如下图所示:
第2节我们提到可以使用CLIP编码文本描述来控制图像的生成,但是实际使用中,每个生成的图像都是按照文本描述生成的吗?当然不一定,其实是大模型的幻觉问题,原因可能是训练数据中图像与文本描述相关性弱,模型可能学着不过度依赖文本描述,而是从大量图像中学习来生成图像,最终达不到我们的期望,那如何解决呢?
我们可以引入一个小技巧-无分类器引导(Classifier-Free Guidance,CFG)。在训练时,我们时不时把文本条件置空,强制模型去学习如何在无文字信息的情况下对图像“去噪”。在推理阶段,我们分别进行了两个预测:一个有文字条件,另一个则没有文字条件。这样我们就可以利用两者的差异来建立一个最终的预测了,并使最终结果在文本条件预测所指明的方向上依据一个缩放系数(引导尺度)更好的生成文本描述匹配的结果。从下图看到,更大的引导尺度能让生成的图像更接近文本描述。

其实除了使用文本描述作为条件生成图像,还有其他不同类型的条件可以控制Stable Diffusion生成图像,比如图片到图片、图片的部分掩码(mask)到图片以及深度图到图片,这些模型分别使用图片本身、图片掩码和图片深度信息作为条件来生成最终的图片。
Img2Img是图片到图片的转换,包括多种类型,如风格转换(从照片风格转换为动漫风格)和图片超分辨率(给定一张低分辨率图片作为条件,让模型生成对应的高分辨率图片,类似Stable Diffusion Upscaler)。Inpainting又称图片修复,模型会根据掩码的区域信息和掩码之外的全局结构信息生成连贯的图片。Depth2Img采用图片的深度新作为条件,模型生成与深度图本身相似的具有全局结构的图片,如下图所示:

DreamBooth可以微调文本到图像的生成模型,最初是为Google的Imagen Model开发的,很快被应用到Stable Diffusion中。它可以根据用户提供的一个主题3~5张图片,就可以生成与该主题相关的图像,但它对于各种设置比较敏感。
安装python库
pip install -Uq diffusers ftfy accelerate
pip install -Uq git+https://github.com/huggingface/transformers数据准备
import torch
import requests
from PIL import Image
from io import BytesIO
from matplotlib import pyplot as plt
# 这次要探索的管线比较多
from diffusers import (
StableDiffusionPipeline,
StableDiffusionImg2ImgPipeline,
StableDiffusionInpaintPipeline,
StableDiffusionDepth2ImgPipeline
)
# 因为要用到的展示图片较多,所以我们写了一个旨在下载图片的函数
def download_image(url):
response = requests.get(url)
return Image.open(BytesIO(response.content)).convert("RGB")
# Inpainting需要用到的图片
img_url = "https://raw.githubusercontent.com/CompVis/latent-
diffusion/main/data/inpainting_examples/overture-creations-
5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-
diffusion/main/data/ inpainting_examples/overture-creations-
5sI6fQgYIuo_mask.png"
init_image = download_image(img_url).resize((512, 512))
mask_image = download_image(mask_url).resize((512, 512))
device = (
"mps"
if torch.backends.mps.is_available()
else "cuda"
if torch.cuda.is_available()
else "cpu"
)加载Stable Diffusion Pipeline,当然可以通过model_id切换Stable Diffusion版本
# 载入管线
model_id = "stabilityai/stable-diffusion-2-1-base"
pipe = StableDiffusionPipeline.from_pretrained(model_id).to(device)如果GPU显存不足,可以尝试以下方法来减少GPU显存的使用
pipe = StableDiffusionPipeline.from_pretrained(model_id,
revision="fp16",torch_dtype=torch.float16).to(device)pipe.enable_attention_slicing()# 给生成器设置一个随机种子,这样可以保证结果的可复现性
generator = torch.Generator(device=device).manual_seed(42)
# 运行这个管线
pipe_output = pipe(
prompt="Palette knife painting of an autumn cityscape",
# 提示文字:哪些要生成
negative_prompt="Oversaturated, blurry, low quality",
# 提示文字:哪些不要生成
height=480, width=640, # 定义所生成图片的尺寸
guidance_scale=8, # 提示文字的影响程度
num_inference_steps=35, # 定义一次生成需要多少个推理步骤
generator=generator # 设定随机种子的生成器
)
# 查看生成结果,如图6-7所示
pipe_output.images[0]
主要参数介绍:
width和height:用于指定生成图片的尺寸,他们必须可以被8整除,否则VAE不能整除工作;
num_inference_steps:会影响生成图片的质量,采用默认50即可,用户也可以尝试不同的值来对比一下效果;
negative_prompt:用于强调不希望生成的内容,该参数一般在无分类器引导的情况下使用。列出一些不想要的特征,以帮助模型生成更好的结果;
guidance_scale:决定了无分类器引导的影响强度。增大这个参数可以使生成的内容更接近给出的文本描述,但是参数值过大,则可能导致结果过于饱和,不美观,如下图所示:
cfg_scales = [1.1, 8, 12]
prompt = "A collie with a pink hat"
fig, axs = plt.subplots(1, len(cfg_scales), figsize=(16, 5))
for i, ax in enumerate(axs):
im = pipe(prompt, height=480, width=480,
guidance_scale=cfg_scales[i], num_inference_steps=35,
generator=torch.Generator(device=device).manual_seed(42)).
images[0]
ax.imshow(im); ax.set_title(f'CFG Scale {cfg_scales[i]}')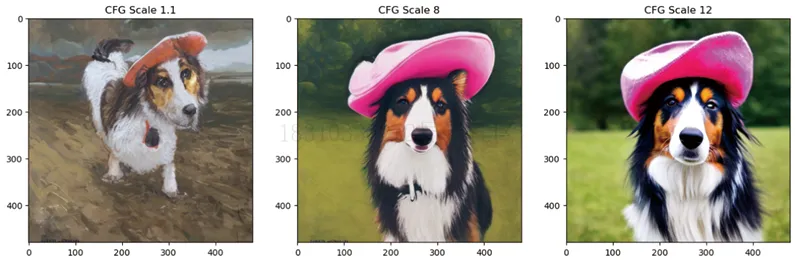
文章转自微信公众号@ArronAI






