

如何快速实现REST API集成以优化业务流程

在本文中,我们以生成绚丽多彩的蝴蝶图像为例,学习Diffusers库相关知识,并学会训练自己的扩散模型。
%pip install -qq -U diffusers datasets transformers accelerate ftfy pyarrow==9.0.0我们计划把训练好的模型上传到huggingface中,因此我们需要首先登录huggingface,可以通过访问https://huggingface.co/settings/tokens获取huggingface的token。
复制上图的token,然后执行下面的代码,并粘贴到执行如下代码的文本框中:
from huggingface_hub import notebook_login
notebook_login()%%capture
!sudo apt -qq install git-lfs
!git config --global credential.helper storeimport numpy as np
import torch
import torch.nn.functional as F
from matplotlib import pyplot as plt
from PIL import Image
def show_images(x):
"""给定一批图像,创建一个网格并将其转换为PIL"""
x = x * 0.5 + 0.5 # 将(-1,1)区间映射回(0,1)区间
grid = torchvision.utils.make_grid(x)
grid_im = grid.detach().cpu().permute(1, 2, 0).clip(0, 1) * 255
grid_im = Image.fromarray(np.array(grid_im).astype(np.uint8))
return grid_im
def make_grid(images, size=64):
"""给定一个PIL图像列表,将它们叠加成一行以便查看"""
output_im = Image.new("RGB", (size * len(images), size))
for i, im in enumerate(images):
output_im.paste(im.resize((size, size)), (i * size, 0))
return output_im
# 对于Mac,可能需要设置成device = 'mps'(未经测试)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")DreamBooth可以对Stable Diffusion进行微调,并在整个过程中引入特定的面部、物体或者风格等额外信息。我们可以初步体验一下Corridor Crew使用DreamBooth制作的视频(https://www.bilibili.com/video/BV18o4y1c7R7/?vd_source=c5a5204620e35330e6145843f4df6ea4),目前模型以及集成到Huggingface上,下面是加载的代码:
from diffusers import StableDiffusionPipeline
# https://huggingface.co/sd-dreambooth-library ,这里有来自社区的各种模型
model_id = "sd-dreambooth-library/mr-potato-head"
# 加载管线
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_
dtype=torch.float16). to(device)prompt = "an abstract oil painting of sks mr potato head by picasso"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).
images[0]
image生成的图像如下图所示:

num_inference_steps:表示采样步骤的数量;
guidance_scale:决定模型的输出与Prompt之间的匹配程度;
import torchvision
from datasets import load_dataset
from torchvision import transforms
dataset = load_dataset("huggan/smithsonian_butterflies_subset",
split="train")
# 也可以从本地文件夹中加载图像
# dataset = load_dataset("imagefolder", data_dir="path/to/folder")
# 我们将在32×32像素的正方形图像上进行训练,但你也可以尝试更大尺寸的图像
image_size = 32
# 如果GPU内存不足,你可以减小batch_size
batch_size = 64
# 定义数据增强过程
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)), # 调整大小
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(), # 将张量映射到(0,1)区间
transforms.Normalize([0.5], [0.5]), # 映射到(-1, 1)区间
]
)
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in
examples["image"]]
return {"images": images}
dataset.set_transform(transform)
# 创建一个数据加载器,用于批量提供经过变换的图像
train_dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True
)可视化其中部分数据集
xb = next(iter(train_dataloader))["images"].to(device)[:8]
print("X shape:", xb.shape)
show_images(xb).resize((8 * 64, 64), resample=Image.NEAREST)# 输出
X shape: torch.Size([8, 3, 32, 32])
在训练扩散模型和使用扩散模型进行推理时都可以由调度器(scheduler)来完成,噪声调度器能够确定在不同迭代周期分别添加多少噪声,通常可以使用如下两种方式来添加噪声,代码如下:
# 仅添加了少量噪声
# 方法一:
# noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_
# start=0.001, beta_end=0.004)
# 'cosine'调度方式,这种方式可能更适合尺寸较小的图像
# 方法二:
# noise_scheduler = DDPMScheduler(num_train_timesteps=1000,
# beta_schedule='squaredcos_cap_v2')参数说明:
beta_start:控制推理阶段开始时beta的值;
beta_end:控制推理阶段结束时beta的值;
beta_schedule:可以通过一个函数映射来为模型推理的每一步生成一个beta值
无论选择哪个调度器,我们都可以通过noise_scheduler.add_noise为图片添加不同程度的噪声,代码如下:
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.randn_like(xb)
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print("Noisy X shape", noisy_xb.shape)
show_images(noisy_xb).resize((8 * 64, 64), resample=Image.NEAREST)# 输出
Noisy X shape torch.Size([8, 3, 32, 32])
下面是Diffusers的核心概念-模型介绍,本文采用UNet,模型结构如图所示:
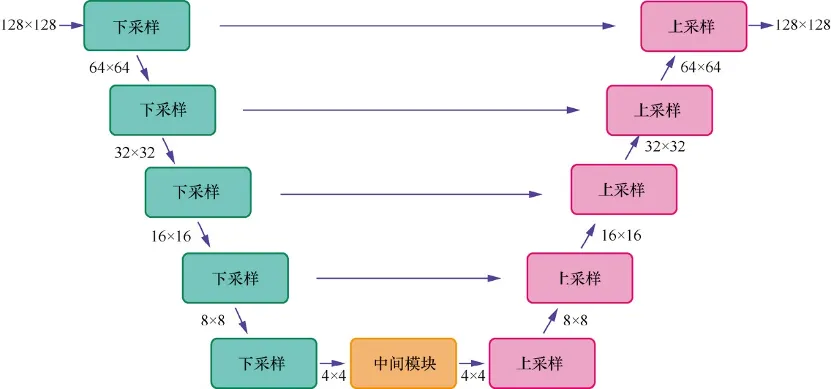
下面代码中down_block_types对应下采样模型(绿色部分),up_block_types对应上采样模型(粉色部分)
from diffusers import UNet2DModel
# 创建模型
model = UNet2DModel(
sample_size=image_size, # 目标图像分辨率
in_channels=3, # 输入通道数,对于RGB图像来说,通道数为3
out_channels=3, # 输出通道数
layers_per_block=2, # 每个UNet块使用的ResNet层数
block_out_channels=(64, 128, 128, 256), # 更多的通道→更多的参数
down_block_types=(
"DownBlock2D", # 一个常规的ResNet下采样模块
"DownBlock2D",
"AttnDownBlock2D", # 一个带有空间自注意力的ResNet下采样模块
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # 一个带有空间自注意力的ResNet上采样模块
"UpBlock2D",
"UpBlock2D", # 一个常规的ResNet上采样模块
),
)
model.to(device);# 设定噪声调度器
noise_scheduler = DDPMScheduler(
num_train_timesteps=1000, beta_schedule="squaredcos_cap_v2"
)
# 训练循环
optimizer = torch.optim.AdamW(model.parameters(), lr=4e-4)
losses = []
for epoch in range(30):
for step, batch in enumerate(train_dataloader):
clean_images = batch["images"].to(device)
# 为图片添加采样噪声
noise = torch.randn(clean_images.shape).to(clean_images.
device)
bs = clean_images.shape[0]
# 为每张图片随机采样一个时间步
timesteps = torch.randint(
0, noise_scheduler.num_train_timesteps, (bs,),
device=clean_images.device
).long()
# 根据每个时间步的噪声幅度,向清晰的图片中添加噪声
noisy_images = noise_scheduler.add_noise(clean_images,
noise, timesteps)
# 获得模型的预测结果
noise_pred = model(noisy_images, timesteps, return_
dict=False)[0]
# 计算损失
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
losses.append(loss.item())
# 迭代模型参数
optimizer.step()
optimizer.zero_grad()
if (epoch + 1) % 5 == 0:
loss_last_epoch = sum(losses[-len(train_dataloader) :]) /
len(train_dataloader)
print(f"Epoch:{epoch+1}, loss: {loss_last_epoch}")我们绘制一下训练过程中损失变化:
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
axs[0].plot(losses)
axs[1].plot(np.log(losses))
plt.show()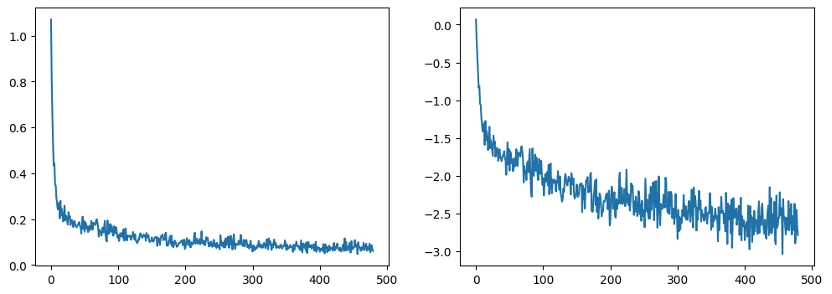
4.5 生成图像
我们使用如下两种方法来生成图像。
方法一:建立一个Pipeline
from diffusers import DDPMPipeline
image_pipe = DDPMPipeline(unet=model, scheduler=noise_scheduler)
pipeline_output = image_pipe()
pipeline_output.images[0]保存Pipeline到本地文件夹
image_pipe.save_pretrained("my_pipeline")我们查看一下my_pipeline文件夹里面保存了什么?
!ls my_pipeline/
# 输出
model_index.json scheduler unetscheduler和unet两个子文件夹包含了生成图像所需的全部组件,其中unet子文件夹包含了描述模型结构的配置文件config.json和模型参数文件diffusion_pytorch_model.bin
!ls my_pipeline/unet/
# 输出
config.json diffusion_pytorch_model.bin我们只需要将 scheduler和unet两个子文件上传到Huggingface Hub中,就可以实现模型共享。
方法二:加入时间t进行循环采样
我们按照不同时间步t进行逐步采样,我们看一下生成的效果,代码如下:
# 随机初始化(8张随机图片)
sample = torch.randn(8, 3, 32, 32).to(device)
for i, t in enumerate(noise_scheduler.timesteps):
# 获得模型的预测结果
with torch.no_grad():
residual = model(sample, t).sample
# 根据预测结果更新图像
sample = noise_scheduler.step(residual, t, sample).prev_sample
show_images(sample)
我们定义上传模型的名称,名称会包含用户名,代码如下:
from huggingface_hub import get_full_repo_name
model_name = "sd-class-butterflies-32"
hub_model_id = get_full_repo_name(model_name)
hub_model_id# 输出
Arron/sd-class-butterflies-32在Huggingface Hub上创建一个模型仓库并将其上传,代码如下:
from huggingface_hub import HfApi, create_repo
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(
folder_path="my_pipeline/scheduler", path_in_repo="",
repo_id=hub_model_id
)
api.upload_folder(folder_path="my_pipeline/unet", path_in_repo="",
repo_id=hub_model_id)
api.upload_file(
path_or_fileobj="my_pipeline/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)# 输出
https://huggingface.co/Arron/sd-class-butterflies-32/blob/main/model_index.json创建一个模型卡片以便描述模型的细节,代码如下:
from huggingface_hub import ModelCard
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# 这个模型用于生成蝴蝶图像的无条件图像生成扩散模型
'''python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('{hub_model_id}')
image = pipeline().images[0]
image
"""
card = ModelCard(content) card.push_to_hub(hub_model_id)# 输出
https://huggingface.co/Arron/sd-class-butterflies-32/blob/main/README.md至此,我们已经把自己训练好的模型上传到Huggingface Hub了,下面就可以使用DDPMPipeline的from_pretrained方法来加载模型了:
from diffusers import DDPMPipeline
image_pipe = DDPMPipeline.from_pretrained(hub_model_id)
pipeline_output = image_pipe()
pipeline_output.images[0]文章转自微信公众号@ArronAI






