用 AWS Smithy 构建下一代 API 服务
文章目录
自动化代码生成这种能减少工作量的事情一直是程序员们的最爱。如果某些代码片段不断重复自身,我们会用宏替换来减少这种重复,但如果涉及到大规模,架构级别的重复,那么我们倾向于用代码生成来解决这种重复。日常工作中,大家使用得比较多的代码生成工具有 gRPC(或者其衍生的一系列 xRPC),用于把微服务的描述生成不同语言的代码。此外还有 GraphQL,用于把 GraphQL schema 生成服务端和客户端的代码。
但大部分时候,我们的服务端在提供对外接口时还离不开 REST API。REST API 以其简单,直观,容易使用,有庞大的工具链和生态圈牢牢地占据着服务端接口的主导位置。对于服务提供者,无论是 stripe,github,slack,还是 openai,对用户提供 REST API 永远是第一优先级。因而,当我们自己在构建产品时,对外的接口 REST API 也应该是最优先考虑的。
在 REST API 领域,没有像 gRPC 或者 GraphQL 那样从零开始严格进行数据建模和服务接口描述的规范。目前主流使用的 API 定义规范是 OpenAPI。虽然 OpenAPI 也提供了相应的代码生成器,可以根据 spec 生成代码,但其生成的代码质量实在不敢令人恭维。大家感兴趣的话,可以看看这个 issue 上大伙的吐槽:https://github.com/OpenAPITools/openapi-generator/issues/7490。几年前,我曾经试图构建一个 elixir 框架(tyrchen/quenya),通过解析 OpenAPI spec ,进行一系列的 变换,生成高质量的服务端代码(甚至包括测试)。虽然在定义良好的 OpenAPI spec 上它工作得很好,但 OpenAPI 以及其底层的 JSON Schema 毕竟不是为了数据建模而设计的,这就导致代码生成器无论怎么处理,都会陷入各种问题,只能疲于奔命地打补丁。因为规范的不严谨,用户很容易写出有问题的 API spec(但依然是一个正确的 OpenAPI spec),代码生成器也就有很大的可能停止工作,甚至产生错误的代码。如果要彻底修正这个问题,就得像 gRPC 或者 GraphQL 那样,严格地定义语法,严格地定义数据结构,但这样就意味着要对 OpenAPI 的规范进行伤筋动骨的改动,甚至需要在数据建模中完全抛弃 Json Schema。
好在,这个领域还有其他并不那么知名的规范和工具。其中一个就是 AWS Smithy。Smithy 是一个可以对任何服务进行接口建模的工具,包括但并不局限于构建 REST API。但由于 AWS 成百上千个服务的对外的 REST 接口,以及其主流的客户端都使用 Smithy 来构建,所以 REST API 是它的一个非常重要的使用场景。Smithy 项目 2019 年由 Amazon 开源,2021 年才陆陆续续掀起了一些水花。2022 年 8 月 Smithy IDL 2.0,以及 2023 年 4 月 Smithy CLI 的发布,标志着 Smithy 社区逐渐开始走向成熟。如今,Smithy 的几个代码生成器,Rust,TypeScript,Python,Swift 都有不错的质量。
然而,Amazon 以外的工程师要使用 Smithy 构建他们自己的 REST API 系统,还有很多难关。首先是环境的搭建 —— 如果你不是个 Java/Kotlin 工程师,且没有深入研究过 Smithy,这一步可以要了你的老命;接下来是需要学习一门新的语言 Smithy IDL;然后,是掌握生成的代码的使用,尤其对于服务端代码而言(客户端毕竟就是一个 API call,再复杂也就那样)。所有这些难关,如果有很好的文档,很好的示例代码,那上手难度就大大减小,可偏偏 Amazon 本就不擅长撰写具有初学者亲和力的文档 —— 你看看 AWS service 需要养那么多 solution architect 就可知一二,而 Smithy 又不是个直接和赚钱的服务有关的东西,所以文档的质量就更加一般。注意,我这里说的「质量」,是指对新手的质量,Smithy 的文档和例子,面向的是「专家」,或者说 AWS 内部需要写接口的那帮人。
我去年在 Smithy 2.0 发布时捣鼓了一把,卡在了环境的搭建 —— 比 demo 稍微复杂一些的代码生成,我就玩不转,无奈放弃;感恩节假期和过去这个周末,分别把环境和实际应用都捣鼓成功了,所以在这里跟大家分享一下。
一、为什么要用 Smithy
一个服务往往有一系列和资源维护相关的 API(比如 S3 常用的 API 就有近十个)。以这两周我在 B 站上连载的 Ava Bot 为例,如果我们要将其产品化,那么很可能需要这些 API:
- 用户管理:信息维护,子账号维护(一个付费家庭可以有多个成员)
- 认证:注册,登录,邮件验证等
- 聊天记录管理:聊天记录的增删查
- 搜索:全文检索,语义检索,搜索记录的增删查
- 计费:付费信息的增删查,计费信息的查询
这些 API 的数量乘以需要支持的客户端的数量(比如 web / iOS / android / desktop),维护成本对个人或者小团队代价也不小。对于像 AWS 这样的拥有海量服务的公司,再乘以服务数量,那更是天文数字。使用像 smithy 这样的代码生成工具可以显著降低维护的难度。
成本是最主要的考量,其次便是建模的规范性。好的建模工具带有从长期的工程经验中累计的必要的约束性,让你可以在最佳实践的条条框框中思考。对于一定规模的团队,仅仅通过团队内部的规范很难约束开发者的天马行空,最好的约束就是工具的强制性约束。比如 lint 工具可以让大家撰写的代码都有一致的风格,而 Smithy 这样的工具可以让所有人的 API 设计都比较类似,避免意外。
最后是开发流程,通过 Smithy 可以大大提升服务设计和设计 review 的效率,使得我们可以关注于如何构建 API 的用户体验,而把脏活累活都交给代码生成器完成,并且这个过程是可以不断重复快速迭代的:
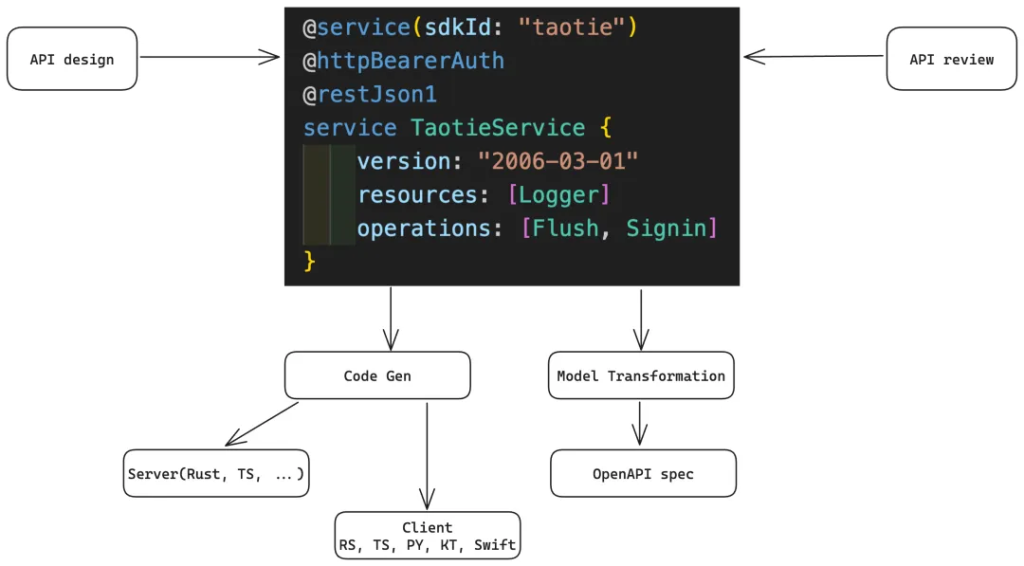
二、如何使用 Smithy
前面说过,环境的设置是第一道难关。由于 Smithy CLI 的出现,这个问题得到大大地缓解。感恩节期间,我探索出一套简单可行的环境配置方案。
一开始,我是想把所有应用到的资源都打包成一个 docker,然后把 smithy build 所需要的配置和 model 描述放进 docker 中进行构建,生成的代码所在的路径映射到宿主机。
后来我发现这有些多此一举:Smithy 所依赖的代码生成器都是 jar 包,所以我其实预先打包好这些 jar,使用时(无论是 CI 还是本地)直接下载这些 jar,放在合适的位置,然后使用即可。
比如写这样的 Makefile 来设置环境:
ASSETS = assets.tar.gz
update-smithy:
@gh release download -R tyrchen/smithy-docker -p '$(ASSETS)'
@rm -rf $HOME/.m2
@tar -xzf $(ASSETS) -C $(HOME) --strip-components=2
@rm $(ASSETS)其中 tyrchen/smithy-docker 是我用于编译各种 Smithy 代码生成器的 repo,编译好的资源打包成一个 assets.tar.gz。你只需要将其下载下来,解压到本地的 maven 路径下即可。注意 Smithy 相关的代码都用 jdk 17,所以确保你本地的 java 是正确的版本。
之后,安装 Smithy CLI,撰写你的 model,以及 build 配置,就可以用 smithy build 生成相关的代码了。
有了这个环境,你再也不需要和 gradle 以及复杂的环境设置打交道了。
三、构建第一个 Smithy 服务
我构建了一个最简单的 repo: tyrchen/smithy-test 来展示如何使用 smithy,你可以使用 make build-smithy 来体验对一个 smithy API 定义构建出 Rust 服务器和客户端,python/typescript/swift 客户端的过程。
服务的 model 如下:
$version: "2.0"
namespace com.example
use aws.protocols#restJson1
use smithy.framework#ValidationException
@restJson1
service EchoService {
version: "2006-03-01"
operations: [EchoMessage]
}
@http(uri: "/echo", method: "POST")
operation EchoMessage {
input := {
@required
@httpHeader("x-echo-message")
message: String
}
output := {
@required
message: String
}
errors: [ValidationException]
}它只有一个服务,服务下没有任何资源(resource),只有一个操作(operation)。Smithy IDL 有 trait 的概念,其中 @ 开头的这些修饰,如 restJson1,http 都是 trait。trait 具体描述了代码生成时,这个服务使用什么协议(http),该如何序列化/反序列化资源(restJson1),以及哪些是必要字段(required),字段出现在服务操作的什么位置(httpHeader,httpLabel,httpPayload 等)。每个操作可以定义 input,output 和 errors。
比如一个更复杂的服务:
@service(sdkId: "taotie")
@httpBearerAuth
@restJson1
service TaotieService {
version: "2006-03-01"
resources: [Logger]
operations: [Flush, Signin]
}
/// Logger resource provides the ability to manage different loggers.
resource Logger {
identifiers: { id: Name }
read: GetLogger
create: CreateLogger
operations: [IngestLog]
}
@readonly
@http(uri: "/logger/{id}", method: "GET")
operation GetLogger {
input := {
@required
@httpLabel
id: Name
}
output := {
@required
@httpPayload
payload: LoggerSummary
}
errors: [ValidationException, NotFoundError, ThrottlingError, ServerError]
}
...
structure LoggerSummary {
@required
total: Integer
@required
schema: LoggerSchema
}
...
@error("client")
@retryable
@httpError(429)
structure ThrottlingError {
@required
message: String
}
...
@error("server")
@httpError(500)
structure ServerError {
@required
code: ErrorCode
@required
message: String
}服务的输入输出可以以内联的方式定义,也可以详细定义每种数据结构。数据结构可以用 structure,list 和 enum 来定义。有了上述基本的介绍,相信不难理解这段 spec。如果你想要学习更多关于 spec 的细节,可以自行阅读 Smithy 2.0 官方文档。
搞定了 model 的定义后,你还需要一个 smithy-build.json 来描述如何让 smithy build 工作。根据你使用的代码生成器的多少,这个配置文件可以很长,但基本上根据示例文件,然后连蒙带猜可以攒出一个可用的版本(见 tyrchen/smithy-test):
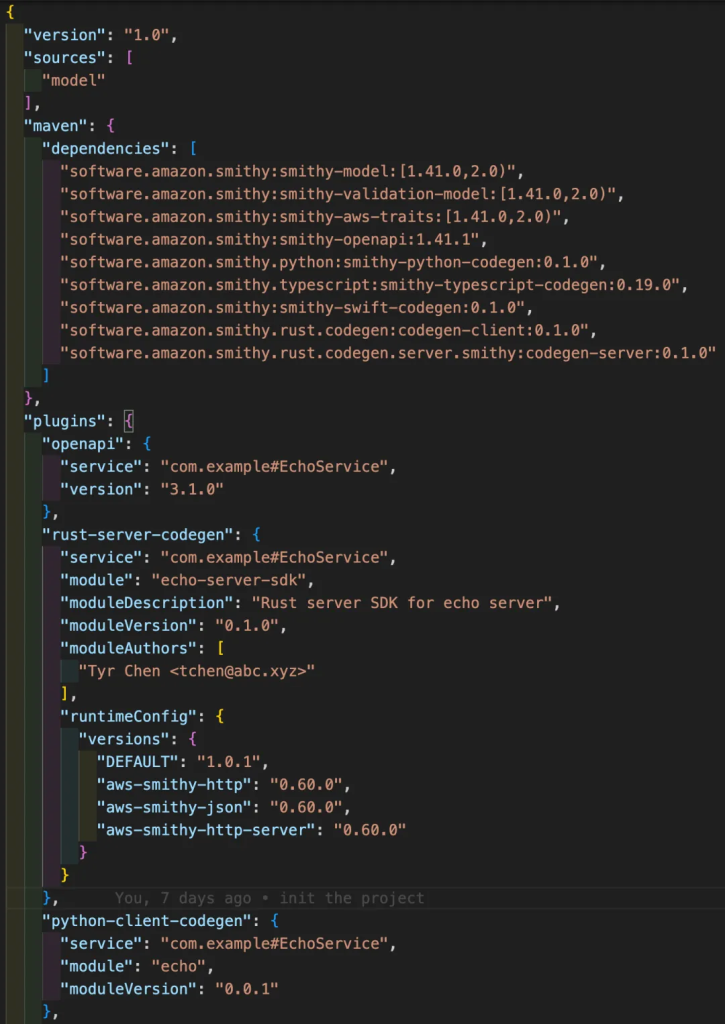
如果一切正常,那么,运行 smithy build 就可以生成大量的代码。
四、使用 Smithy 生成的服务器代码
Smithy 官方支持 rust / typescript 的服务器代码生成,但这里我们只介绍 Rust。感谢 Rust 生态下的 tower 生态和 hyper 生态(它们衍生出 tower-http,axum,tonic 等一系列优秀的 crate),smithy-rs 也将它们作为构建服务端 SDK 的基石。这也就意味着 smithy 生成的代码中广泛采用的注入 Request 和 Response 这样的概念大家都是相通的,比如你可以通过 Extension 为路由添加新的属性,你可以用 Service 和 Layer 来构建中间层。甚至,你可以把 Smithy 生成的 server SDK 作为一个 Route Service 添加到 axum 的一个子路由中,实现 website 和 REST API 共用同一个服务器的功能。在我的 smithy-test 演示代码中,我混用了 axum 和 smithy server sdk:
pub async fn get_router(conf: AppConfig) -> Router {
// make name with static lifetime
let name = Box::leak(Box::new(conf.server_name.clone()));
let state = Arc::new(AppState::new(conf));
// smithy config
let config = EchoServiceConfig::builder()
// IdentityPlugin is a plugin that adds a middleware to the service, it just shows how to use plugins
.http_plugin(IdentityPlugin)
.layer(AddExtensionLayer::new(state.clone()))
// 我做的 smithy auth middleware
.layer(BearerTokenProviderLayer::new())
.layer(ServerRequestIdProviderLayer::new_with_response_header(
HeaderName::from_static("x-request-id"),
))
.build();
// smithy 兼容 Tower 的 service
let api = EchoService::builder(config)
.echo_message(api::echo_message)
.signin(api::signin)
.build()
.expect("failed to build an instance of Echo Service");
let doc_url = "/swagger/openapi.json";
let doc = include_str!("../../../smithy/gen/openapi/EchoService.openapi.json");
// axum 路由
Router::new()
.route("/swagger", get(|| async { Html(swagger_ui(doc_url)) }))
.route(doc_url, get(move || async move { doc }))
// 使用 nest_service 将 smithy service 加载为子路由
.nest_service("/api/", api)
// 在 smithy 之外定义的 middleware 也会影响 smithy Response
.layer(ServerTimingLayer::new(name))
.with_state(state)
}如果你熟悉 axum,那么这段代码很好地诠释了 tower 生态的强大之处。说句题外话,我觉得 Rust 下的 web 框架,如果现在还没有构建在 tower 和 hyper 生态下,那么是不值得学习和使用的。它们会慢慢凋零,无论它曾经有多大的用户群体。Rocket 如此,actix-web 亦如此。
如上代码所示,构建一个 smithy server sdk 的 middleware 其实就是构建一个 tower Service。比如代码中提供的 Bearer Auth 的支持,就是实现这个接口而已:
impl<Body, S> Service<Request<Body>> for BearerTokenProvider<S>
where
S: Service<Request<Body>, Response = Response<BoxBody>>,
S::Future: std::marker::Send + 'static,由于我对 smithy 的了解还不够深入,所以我一直没有找到正确的姿势让 smithy server sdk 生成处理 auth 的代码。我觉得这应该是框架提供的,我只需要提供一个回调函数来验证 auth token 即可。然而我并未在 smithy-rs 的源码中找到这样的代码,所以这里我自己为其实现了一个 middleware。
在我尝试构建服务端代码时,我的一个最大的感悟是 smithy 让你在定义 API 时就想好都有什么错误,如何组合他们,并且随着服务的迭代,可以不断累加错误的定义。错误处理一直是做任何系统的梦魇,但 smithy 以一种非常简单的方式把错误的定义集中起来,并根据需要组合使用。比如 signin 这个操作,我目前是如下定义的:
errors: [
ValidationException,
UnauthorizedError,
ForbiddenError,
ThrottlingError
]以后我需要更多错误类型时,如 ServerError,只需要相应添加,重新生成代码,然后在代码中应用新的错误类型即可。
五、使用 Smithy 生成的客户端代码
所有代码生成器,减轻的最大的负担是客户端代码。服务端一般会固定一种语言撰写,但客户端语言可以千变万化,光是主流的客户端语言就有 typescript / swift / kotlin / dart (flutter),如果考虑服务和服务间的集成,那还有 rust / go / python / csharp / java 等。为服务接口维护这么多客户端是一种极大的痛苦。我们看看上面的 Echo service,如何使用 Rust 调用:
let config = Config::builder()
.endpoint_url("http://localhost:3000/api")
.bearer_token(Token::new(token, None))
.behavior_version_latest()
.build();
let client = Client::from_conf(config);
let ret = client.echo_message().message("example").send().await?;是不是似曾相识?对,如果你用 aws Rust SDK 访问 AWS service,那么你的代码有几乎一样的结构。在这样的客户端代码中,你无需关心 REST API 的细节(比如 message 放在 header 而非 body),就可以轻松调用。
除了各种语言的客户端代码外, Smithy 还可以生成 OpenAPI spec。这带来一个巨大的好处就是可以在服务定义完成之后,就能借助 swagger UI 的力量,有一个可以简单交互的 API 工具:
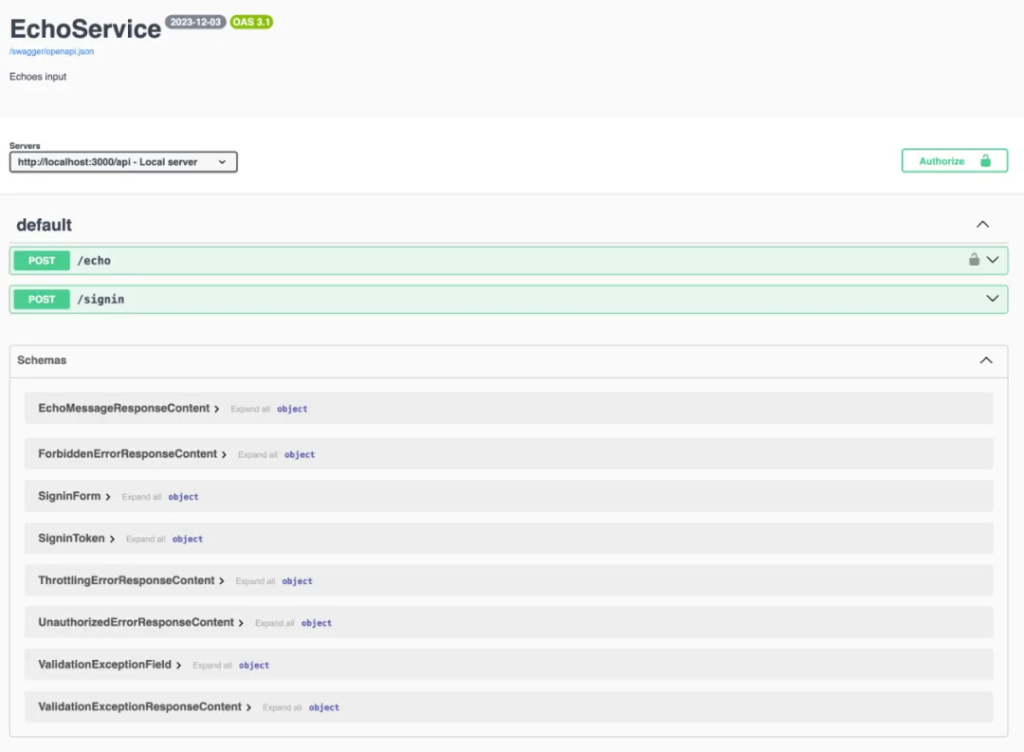
六、扩展 Smithy
理论上,任何人都可以通过添加 trait 来扩展 smithy 的能力。但 smithy 整套构建体系基于 kotlin 和 gradle,所以这个「任何人」至少不包括对 java 体系一无所知的我。业界比较知名的 smithy 的扩展是 Tubi 同行 Disney streaming 的 smithy4s,看名字就知道 Disney 为 smithy 提供了 scala 支持。在这个支持中,Disney 顺带对 smithy 做了不少扩展的 trait。
本来 smithy 相关的文档和示例就很少,关于扩展 smithy,自己撰写 trait 和代码生成器的就更是凤毛麟角。如果你对此有需要,相较于在互联网上求助,不若直接联系熟悉的 aws 工程师或者 disney 工程师来得更快。
七、总结
当我耐着极大的性子,一点点看 smithy pokemon rust 的示例代码,smithy-rs 源码并和网上其他各种资料相互印证,把各种艰难险阻踩在脚下,成功调用生成好的代码时,我一下子有了桃花源记中「初极狭,才通人,复行数十步,豁然开朗」的感觉。Smithy 绝对是那种上手很痛苦(因为文档例子不给力),但用起来很舒服(至少 Rust server SDK 如此)的工具。
这个周末,我用 smithy 写了个 POC 项目。我把我的心得记录于此,一来让知识和技能得到传播,让这么优秀的工具不至于无人问津;二来也是把我自己在全速写代码,不断踩坑又埋坑的过程梳理一下。有机会我会在 B 站做个系列视频,系统地介绍一下用 smithy 的生态构建一个 API 服务。敬请期待!
文章转自微信公众号@程序人生
最新文章
- 小红书AI文章风格转换:违禁词替换与内容优化技巧指南
- REST API 设计:过滤、排序和分页
- 认证与授权API对比:OAuth vs JWT
- 如何获取 Coze开放平台 API 密钥(分步指南)
- 首次构建 API 时的 10 个错误状态代码以及如何修复它们
- 当中医遇上AI:贝业斯如何革新中医诊断
- 如何使用OAuth作用域为您的API添加细粒度权限
- LLM API:2025年的应用场景、工具与最佳实践 – Orq.ai
- API密钥——什么是API Key 密钥?
- 华为 UCM 推理技术加持:2025 工业设备秒级监控高并发 API 零门槛实战
- 使用JSON注入攻击API
- 思维链提示工程实战:如何通过API构建复杂推理的AI提示词系统