使用Function Calling构建自主 AI 智能体
文章目录
将你的聊天机器人转变为可与外部API交互的智能体
Function Calling 函数调用不是新鲜事物。2023年7月,OpenAI为其GPT模型引入了函数调用功能,现在其他竞争对手也在采用这一特性。谷歌的Gemini API最近支持了它,Anthropic也将其集成到Claude中。函数调用正在成为大型语言模型(LLM)的必备功能,提升了它们的能力。学习这项技术将会更加有用!
有鉴于此,我将编写一个全面的教程,涵盖函数调用的实际实现,而不是基本介绍(已经有很多这样的教程)。重点将是构建一个完全自主的AI智能体,并将其与Streamlit集成,创建类似于ChatGPT的界面。尽管本文使用OpenAI进行演示,但只需稍加修改,本教程也可适用于支持函数调用的其他LLM,如Gemini。
函数调用的目的是什么?
函数调用使开发人员能够描述函数(也称为工具,你可以将其视为模型可执行的动作,如执行计算或下订单),并让模型智能地选择输出包含调用这些函数所需参数的JSON对象。简而言之,它允许:
它开启了诸多可能性:
- 自主AI助手: 机器人不仅可以回答查询,还可以与内部系统交互,处理诸如客户订单和退货等任务。
- 个人研究助手: 比如说,如果你在计划旅行,助手可以在网上搜索、爬取内容、比较选择并将结果汇总到Excel中。
- 物联网语音命令: 模型可以根据检测到的意图控制设备或建议操作,例如调整空调温度。
函数调用的结构
借鉴了 Gemini 的函数调用文档,函数调用具有以下结构,在 OpenAI 中也是如此
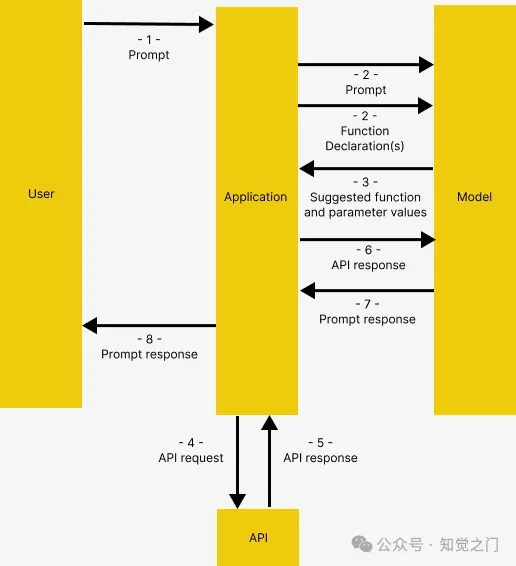
- 用户向应用程序发出提示
- 应用程序将用户提供的提示和函数声明(描述模型可以使用的工具)传递给模型
- 基于函数声明,模型建议使用哪个工具以及相关的请求参数。注意,模型只输出建议的工具和参数,而不实际调用函数
- 和 5. 基于响应,应用程序调用相关的API
- 和 7. 将API的响应再次输入到模型中,以生成可读的响应
- 应用程序将最终响应返回给用户,然后从1重复
这可能看起来有些复杂,但本文将通过示例对此进行详细说明
架构
在深入研究代码之前,先简单介绍一下演示应用程序的架构
解决方案
这里我们为访问酒店的游客构建一个助手。助手可以访问以下工具,从而与外部应用程序交互:
get_items、purchase_item: 通过API连接到存储在数据库中的产品目录,用于检索物品列表和进行购买rag_pipeline_func: 连接到文档库,使用检索增强生成(RAG)从非结构化文本(如酒店手册)中获取信息
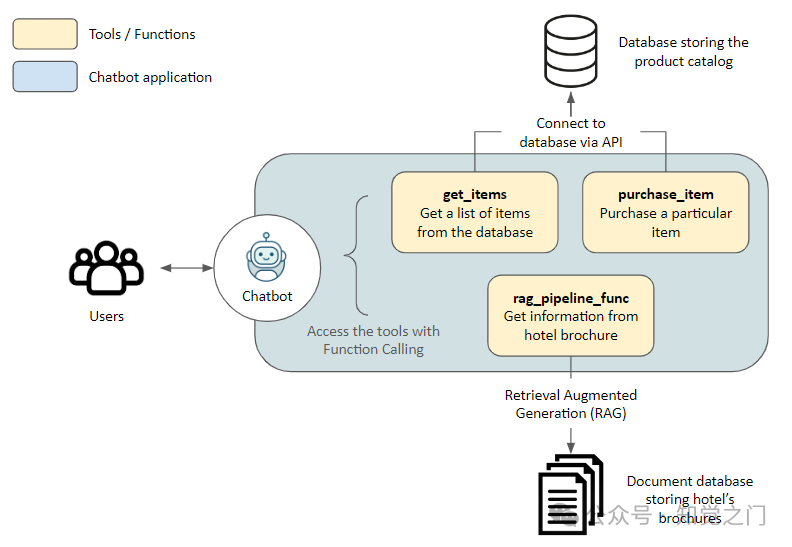
技术栈
- 嵌入模型: all-MiniLM-L6-v2
- 向量数据库: Haystack’s InMemoryDocumentStore
- LLM: 通过 OpenRouter 访问 GPT-4 Turbo。使用 OpenRouter,你可以从香港访问不同的 LLM API,而无需 VPN。只需对代码进行细微更改,该流程也可适用于支持函数调用的其他 LLM,比如 Gemini
- LLM 框架: Haystack 因其易于使用、出色的文档和在构建管道时的透明性。本教程实际上是对他们 同主题的精彩教程 的扩展
现在让我们开始吧!
示例应用程序
准备工作
前往 Github 克隆我的代码。下面的内容可以在 function_calling_demo 笔记本中找到。
请创建并激活一个虚拟环境,然后运行 pip install -r requirements.txt 安装所需的包。
初始化
我们首先连接到 OpenRouter。或者,不覆盖 api_base_url 而直接使用原始的 OpenAIChatGenerator 也可以,前提是你拥有一个 OpenAI API 密钥。
import os
from dotenv import load_dotenv
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.utils import Secret
from haystack.dataclasses import ChatMessage
from haystack.components.generators.utils import print_streaming_chunk
load_dotenv()
OPENROUTER_API_KEY = os.environ.get('OPENROUTER_API_KEY')
chat_generator = OpenAIChatGenerator(api_key=Secret.from_env_var("OPENROUTER_API_KEY"),
api_base_url="https://openrouter.ai/api/v1",
model="openai/gpt-4-turbo-preview",
streaming_callback=print_streaming_chunk)然后测试 chat_generator 是否可以成功调用
chat_generator.run(messages=[ChatMessage.from_user("Return this text: 'test'")])———-输出应如下所示———-
{'replies': [ChatMessage(content="'test'", role=<ChatRole.ASSISTANT: 'assistant'>, name=None, meta={'model': 'openai/gpt-4-turbo-preview', 'index': 0, 'finish_reason': 'stop', 'usage': {}})]}第1步: 建立数据存储
在这里,我们建立应用程序与两个数据源之间的连接: 文档库用于非结构化文本,应用程序数据库通过API连接。
使用管道索引文档
我们提供了 documents 中的示例文本,供模型执行检索增强生成(RAG)。这些文本被转换为嵌入并存储在内存中的文档库中。
from haystack import Pipeline, Document
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.writers import DocumentWriter
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
documents = [
Document(content="Coffee shop opens at 9am and closes at 5pm."),
Document(content="Gym room opens at 6am and closes at 10pm.")
]
document_store = InMemoryDocumentStore()
indexing_pipeline = Pipeline()
indexing_pipeline.add_component(
"doc_embedder", SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")
)
indexing_pipeline.add_component("doc_writer", DocumentWriter(document_store=document_store))
indexing_pipeline.connect("doc_embedder.documents", "doc_writer.documents")
indexing_pipeline.run({"doc_embedder": {"documents": documents}})它应该输出以下内容,对应于我们之前创建的 documents
{'doc_writer': {'documents_written': 2}}启动API服务器
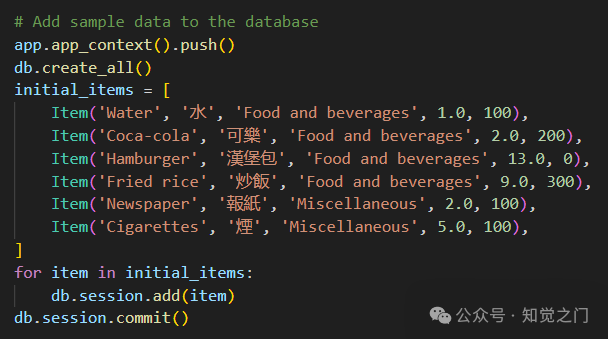
使用Flask创建了一个API服务器 db_api.py 以连接到SQLite。请在终端中运行 python db_api.py 启动它

另请注意, db_api.py 中已添加了一些初始数据:
第2步: 定义函数
在这里,我们准备了模型在执行函数调用后将调用的实际函数(步骤4-5,如函数调用结构中所述)
RAG函数
即 rag_pipeline_func。这用于模型通过搜索存储在文档库中的文本来提供答案。我们首先将RAG检索定义为一个Haystack管道。
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
template = """
Answer the questions based on the given context.
Context:
{% for document in documents %}
{{ document.content }}
{% endfor %}
Question: {{ question }}
Answer:
"""
rag_pipe = Pipeline()
rag_pipe.add_component("embedder", SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2"))
rag_pipe.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store))
rag_pipe.add_component("prompt_builder", PromptBuilder(template=template))
rag_pipe.add_component("llm", OpenAIGenerator(api_key=Secret.from_env_var("OPENROUTER_API_KEY"),
api_base_url="https://openrouter.ai/api/v1",
model="openai/gpt-4-turbo-preview"))
rag_pipe.connect("embedder.embedding", "retriever.query_embedding")
rag_pipe.connect("retriever", "prompt_builder.documents")
rag_pipe.connect("prompt_builder", "llm")测试函数是否工作
query = "When does the coffee shop open?"
rag_pipe.run({"embedder": {"text": query}, "prompt_builder": {"question": query}})这应该会产生以下输出。注意模型给出的 replies 来自我们之前提供的示例文档。
{'llm': {'replies': ['The coffee shop opens at 9am.'],
'meta': [{'model': 'openai/gpt-4-turbo-preview',
'index': 0,
'finish_reason': 'stop',
'usage': {'completion_tokens': 9,
'prompt_tokens': 60,
'total_tokens': 69,
'total_cost': 0.00087}}]}}然后我们可以将 rag_pipe 转换为一个函数,只提供 replies 而不添加其他详细信息。
def rag_pipeline_func(query: str):
result = rag_pipe.run({"embedder": {"text": query}, "prompt_builder": {"question": query}})
return {"reply": result["llm"]["replies"][0]}API调用
我们定义 get_items 和 purchase_item 函数与数据库交互。
db_base_url = 'http://127.0.0.1:5000'
import requests
import json
def get_categories():
response = requests.get(f'{db_base_url}/category')
data = response.json()
return data
def get_items(ids=None,categories=None):
params = {
'id': ids,
'category': categories,
}
response = requests.get(f'{db_base_url}/item', params=params)
data = response.json()
return data
def purchase_item(id,quantity):
headers = {
'Content-type':'application/json',
'Accept':'application/json'
}
data = {
'id': id,
'quantity': quantity,
}
response = requests.post(f'{db_base_url}/item/purchase', json=data, headers=headers)
return response.json()定义工具列表
现在我们已经定义了函数,需要让模型识别这些函数,并指示它们如何使用,通过为它们提供描述。
由于我们在这里使用的是OpenAI,因此 tools 的格式遵循 OpenAI 所需的格式
tools = [
{
"type": "function",
"function": {{
"name": "get_items",
"description": "Get a list of items from the database",
"parameters": {
"type": "object",
"properties": {
"ids": {
"type": "string",
"description": "Comma separated list of item ids to fetch",
},
"categories": {
"type": "string",
"description": "Comma separated list of item categories to fetch",
},
},
"required": [],
},
}
},
{
"type": "function",
"function": {
"name": "purchase_item",
"description": "Purchase a particular item",
"parameters": {
"type": "object",
"properties": {
"id": {
"type": "string",
"description": "The given product ID, product name is not accepted here. Please obtain the product ID from the database first.",
},
"quantity": {
"type": "integer",
"description": "Number of items to purchase",
},
},
"required": [],
},
}
},
{
"type": "function",
"function": {
"name": "rag_pipeline_func",
"description": "Get information from hotel brochure",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The query to use in the search. Infer this from the user's message. It should be a question or a statement",
}
},
"required": ["query"],
},
},
}
]第3步: 汇总所有内容
我们现在拥有了测试函数调用所需的所有输入!在这里我们做了以下几件事:
- 为模型提供初始提示,给出一些上下文
- 提供一个样本用户生成的消息
- 最重要的是,我们在
tools中向聊天生成器传递了工具列表
context = f"""You are an assistant to tourists visiting a hotel.
You have access to a database of items (which includes {get_categories()}) that tourists can buy, you also have access to the hotel's brochure.
If the tourist's question cannot be answered from the database, you can refer to the brochure.
If the tourist's question cannot be answered from the brochure, you can ask the tourist to ask the hotel staff.
"""
messages = [
ChatMessage.from_system(context),
ChatMessage.from_user("Can I buy a coffee?"),
]
response = chat_generator.run(messages=messages, generation_kwargs= {"tools": tools})
response———-输出———-
{'replies': [ChatMessage(content='[{"index": 0, "id": "call_AkTWoiJzx5uJSgKW0WAI1yBB", "function": {"arguments": "{\\"categories\\":\\"Food and beverages\\"}", "name": "get_items"}, "type": "function"}]', role=<ChatRole.ASSISTANT: 'assistant'>, name=None, meta={'model': 'openai/gpt-4-turbo-preview', 'index': 0, 'finish_reason': 'tool_calls', 'usage': {}})]}现在让我们检查一下响应。注意函数调用是如何同时返回模型选择的函数和调用所选函数所需的参数的。
function_call = json.loads(response["replies"][0].content)[0]
function_name = function_call["function"]["name"]
function_args = json.loads(function_call["function"]["arguments"])
print("Function Name:", function_name)
print("Function Arguments:", function_args)———-输出———-
Function Name: get_items
Function Arguments: {'categories': 'Food and beverages'}当提出另一个问题时,模型会使用更相关的工具
messages.append(ChatMessage.from_user("Where's the coffee shop?"))
response = chat_generator.run(messages=messages, generation_kwargs= {"tools": tools})
function_call = json.loads(response["replies"][0].content)[0]
function_name = function_call["function"]["name"]
function_args = json.loads(function_call["function"]["arguments"])
print("Function Name:", function_name)
print("Function Arguments:", function_args)———-输出———-
Function Name: rag_pipeline_func
Function Arguments: {'query': "Where's the coffee shop?"}同样,请注意这里并没有实际调用任何函数,这就是我们接下来要做的!
调用函数
我们可以将参数输入选择的函数
available_functions = {"get_items": get_items, "purchase_item": purchase_item,"rag_pipeline_func": rag_pipeline_func}
function_to_call = available_functions[function_name]
function_response = function_to_call(**function_args)
print("Function Response:", function_response)———-输出———-
Function Response: {'reply': 'The provided context does not specify a physical location for the coffee shop, only its operating hours. Therefore, I cannot determine where the coffee shop is located based on the given information.'}然后可以将 rag_pipeline_func 的响应作为上下文追加到 messages 中,以便模型提供最终答复。
messages.append(ChatMessage.from_function(content=json.dumps(function_response), name=function_name))
response = chat_generator.run(messages=messages)
response_msg = response["replies"][0]
print(response_msg.content)———-输出———-
For the location of the coffee shop within the hotel, I recommend asking the hotel staff directly. They will be able to guide you to it accurately.我们现在已经完成了一个聊天周期!
第4步: 将其转换为交互式聊天
上述代码展示了如何进行函数调用,但我们希望进一步将其转换为交互式聊天
这里我展示了两种实现方式,从在笔记本本身中打印对话的基本 input() 方法,到通过 Streamlit 渲染以提供类似于 ChatGPT 的 UI。
**input()** 循环
代码借鉴自 Haystack 的教程,允许我们快速测试模型。注意:这个应用程序旨在演示函数调用的思想,并非旨在完全健壮,例如不支持同时订购多个物品、无虚构等。
import json
from haystack.dataclasses import ChatMessage, ChatRole
response = None
messages = [
ChatMessage.from_system(context)
]
while True:
if response and response["replies"][0].meta["finish_reason"] == "tool_calls":
function_calls = json.loads(response["replies"][0].content)
for function_call in function_calls:
function_name = function_call["function"]["name"]
function_args = json.loads(function_call["function"]["arguments"])```
function_to_call = available_functions[function_name]
function_response = function_to_call(**function_args)
messages.append(ChatMessage.from_function(content=json.dumps(function_response), name=function_name))
else:
if not messages[-1].is_from(ChatRole.SYSTEM):
messages.append(response["replies"][0])
user_input = input("ENTER YOUR MESSAGE 👇 INFO: Type 'exit' or 'quit' to stop\n")
if user_input.lower() == "exit" or user_input.lower() == "quit":
break
else:
messages.append(ChatMessage.from_user(user_input))
response = chat_generator.run(messages=messages, generation_kwargs={"tools": tools})
虽然它可以工作,但我们可能希望有一个更好看的界面。
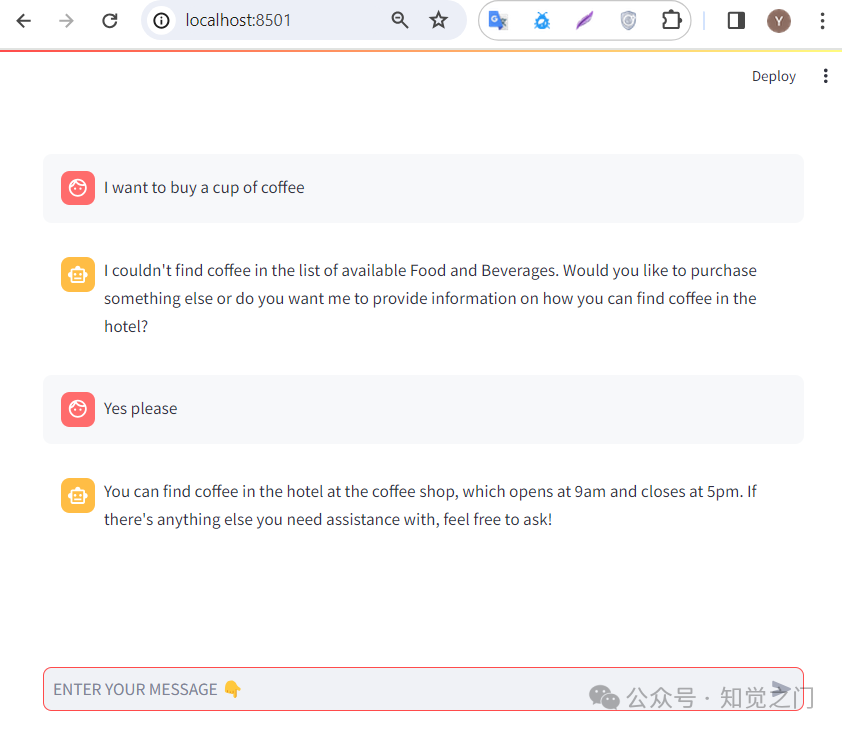
Streamlit 界面
Streamlit 可以将数据脚本转换为可共享的 Web 应用程序,为我们的应用程序提供了一个简洁的 UI。上面显示的代码已经适配到我的 repo 中 streamlit 文件夹下的 Streamlit 应用程序中。
你可以通过以下步骤运行它:
- 如果你还没有这样做,请使用
python db_api.py启动 API 服务器 - 设置 OPENROUTER_API_KEY 为环境变量,例如
export OPENROUTER_API_KEY='@替换为你的API密钥'(假设你在 Linux 上或使用 git bash 执行) - 在终端中导航到
streamlit文件夹,使用cd streamlit - 运行 Streamlit 命令
streamlit run app.py。你的浏览器中应该会自动打开一个新标签页,运行该应用程序
就是这样!希望你喜欢这篇文章。
文章转自微信公众号@知觉之门