

使用NestJS和Prisma构建REST API:身份验证
使用Flink开发批式或流式Job,除了基本的处理逻辑与实际应用场景相关,我们更关心的是Flink提供的基本框架,是如何在API层面进行统一处理的,或者说尽量使API统一,这样有助于我们对Flink框架更深入地理解。目前使用Flink 1.10版本开发批式和流式Job,在API层面来看,大部分还是比较统一的,但是由于批式和流式场景还是有一定的差异,想要完全统一还是有一定难度。
Flink数据流编程模型的分层设计,如下图所示:
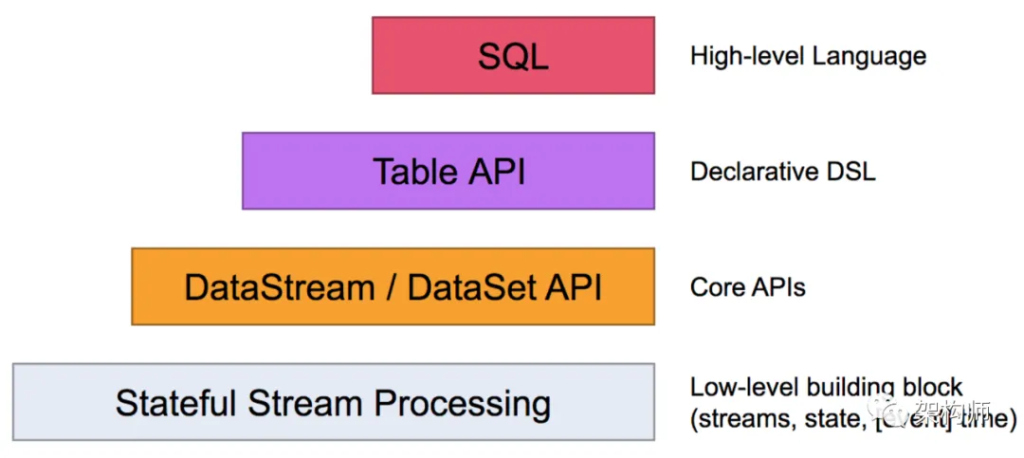
Flink编程API中,我们开发的数据处理Job程序,都是始于一个Source,对应的输入数据源,终于一个Sink,对应输出的存储系统,中间是各种丰富的处理算子。但是对于批式和流式编程API,从代码层面对应的抽象基本上是名称不同,具体逻辑功能比较一致:批式编程API对批式Job DAG中每个节点的抽象使用的是DataSet,而流式编程API中对应的是DataStream。
对于批式Job DAG中,DataSet的类设计体系,如下图所示:
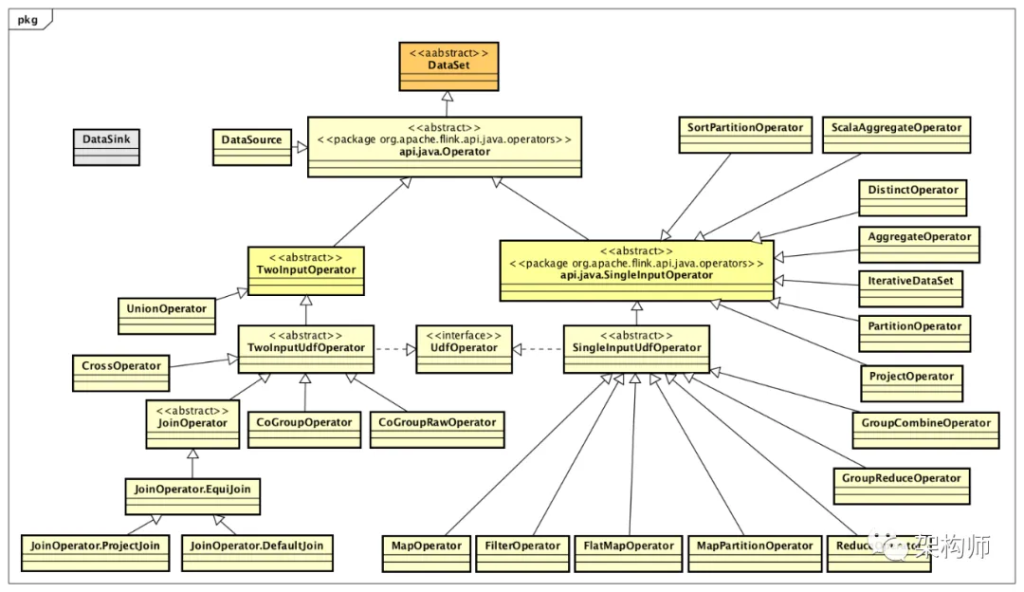
相关的类都在包org.apache.flink.api.java.operators下面,通过上图可以看出,主要分为4类:DataSource、DataSink、SingleInputOperator、TwoInputOperator。其中,DataSink并没有继承自DataSet,但是作为批式Job DAG的输出节点抽象,也还是与上图中各个Operator有直接或间接的关系。 在编写批式Job过程中,输入是一个DataSource(实际也是DataSet),处理中每经过一个转换操作(Transformation),都会生成一个新的类型的DataSet,这在API上看是统一的,实际底层稍微有一点不同。比如,经过groupBy操作后,返回的是一个UnsortedGrouping,它不是一个DataSet实现,而是一种中间结构,封装了很多有用的信息以供翻译过程中使用,通过使用这种中间结构能够更好地处理复杂的转换操作,通过下面代码来看可能更直观一些,在DataSet中查看groupBy()方法代码,如下所示:
public UnsortedGrouping<T> groupBy(int... fields) {
return new UnsortedGrouping<>(this, new Keys.ExpressionKeys<>(fields, getType()));
}上面代码中UnsortedGrouping并不是一个DataSet实现,而是一个用来处理groupBy操作的中间结构,它继承自Grouping抽象类,类定义如下所示:
@Public
public abstract class Grouping<T> {
protected final DataSet<T> inputDataSet;
protected final Keys<T> keys;
protected Partitioner<?> customPartitioner;
public Grouping(DataSet<T> set, Keys<T> keys) {
if (set == null || keys == null) {
throw new NullPointerException();
}
if (keys.isEmpty()) {
throw new InvalidProgramException("The grouping keys must not be empty.");
}
this.inputDataSet = set;
this.keys = keys;
}
@Internal
public DataSet<T> getInputDataSet() {
return this.inputDataSet;
}
@Internal
public Keys<T> getKeys() {
return this.keys;
}
@Internal
public Partitioner<?> getCustomPartitioner() {
return this.customPartitioner;
}
}对于流式Job DAG中,类设计方面稍有不同,Flink使用了DataStream和StreamOperator这两个类设计体系。我们先看DataStream类设计体系,如下图所示:
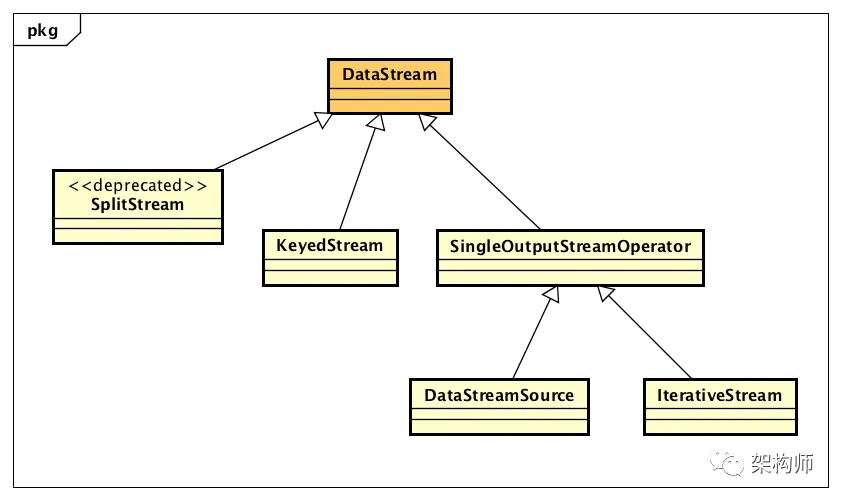
DataStream表示在流式Job DAG中每一步转换操作之前与之后,都对应着一个DataStream的数据结构,它内部封装了与转换操作相关的处理逻辑,其实就是StreamOperator。对应上图中,我们举几个编写流式处理程序的例子说明:调用StreamExecutionEnvironment.readTextFile()时会生成一个DataStreamSource,调用keyBy()时会生成一个KeyedStream,调用split()时会生成一个SplitStream,调用iterate()时会生成一个IterativeStream。
下面看下StreamOperator类的设计体系,如下图所示:
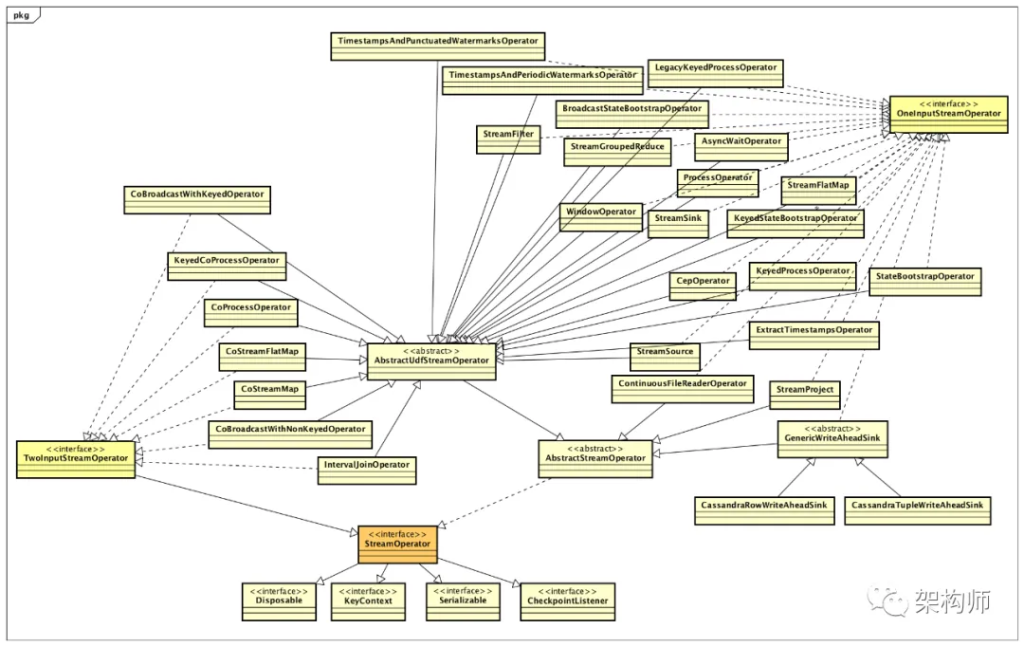
编写批式Job程序,使用执行上线文环境对象ExecutionEnvironment,而流式使用的是StreamExecutionEnvironment。通过用户编程API构建好DAG Job后,都是通过调用执行上线文环境对象的execute()方法提交Job去运行。无论是批式Job还是流式Job,它们在提交执行过程中,有相同的流程,也有不同的流程,通过识别这个过程中涉及相同/不同的API对象,我们抽象出如下流程概念图:
上图中,左侧是批式Job通过API构建并提交到计算集群,基于DataSet进行编程实现,始于DataSource,终于DataSink;右侧是流式Job通过API构建并提交到计算集群,基于DataStream进行编程实现,始于DataStreamSource,终于DataStreamSink。中间部分,跨两个不同环境上下文对象是在提交Job过程中公共的抽象。
对于批式Job程序提交,核心代码如下所示:
final Plan plan = createProgramPlan(jobName);
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(plan, configuration);对于流式Job程序提交运行的核心代码,如下所示:
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
… …
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(streamGraph, configuration); 上面代码中的Plan和StreamGraph,都是Pipeline接口的具体实现,这两个实现分别用来表示批式和流式Job程序的拓扑,内部封装了用于构建生成JobGraph所需要的全部信息。
上面代码是构建生成JobGraph的主要逻辑,先是通过getExecutor()获取到一个PipelineExecutor,然后调用PipelineExecutor的execute()来构建并提交JobGraph。这里,PipelineExecutor表示执行Flink Job的方式,比如,本地执行使用LocalExecutor,或提交到YARN集群上执行使用YarnJobClusterExecutor,或提交到Kubernetes集群上执行使用KubernetesSessionClusterExecutor,等等。
无论是提交批式还是流式Job,最终都被转换成JobGraph对象,构建JobGraph的处理逻辑是完全统一的。构建JobGraph的代码逻辑,如下代码所示:
public static JobGraph getJobGraph(
Pipeline pipeline,
Configuration optimizerConfiguration,
int defaultParallelism) {
FlinkPipelineTranslator pipelineTranslator = getPipelineTranslator(pipeline);
return pipelineTranslator.translateToJobGraph(pipeline,
optimizerConfiguration,
defaultParallelism);
}上面,输入的Pipeline对象,批式编程对应具体实现Plan,流式编程对应具体实现StreamGraph。由于用户编程API的不同,这里面选择了不同的FlinkPipelineTranslator来对输入的Pipeline对象进行翻译,其中批式对应的是PlanTranslator,流式对应的是StreamGraphTranslator,最终通过翻译,都生成一个统一的JobGraph。当然,调用translateToJobGraph()方法进行翻译处理的逻辑有很大的不同。
文章转自微信公众号@架构师






