一文搞懂生成式检索增强
文章目录
生成式人工智能最近取得了巨大的成功,并引起了轰动,其模型可以生成流畅的文本、逼真的图像甚至视频。就语言而言,经过大量数据训练的大型语言模型能够理解上下文并生成与问题相关的答案。这篇博文探讨了与生成式人工智能相关的挑战、检索增强生成 (RAG) 如何帮助克服这些挑战、RAG 的工作原理以及使用 RAG 的优势和挑战。
生成式人工智能面临的挑战
不过,重要的是要明白,这些模型并不完美。 这些模型所拥有的知识是它们在训练过程中学到的参数知识,是整个训练数据集的浓缩表示。
缺乏领域知识
这些模型应该能够很好地回答训练数据中出现的有关常识的问题。 但它们无法可靠地回答训练数据集中没有的事实问题。 如果模型匹配良好,它就会拒绝回答此类域外问题。 不过,它也有可能简单地编造答案(也称为幻觉)。 例如,通用模型通常会笼统地理解每家公司都有休假政策,但它并不了解我所在公司的休假政策。
冷冻参数知识
LLM(大语言模型)的知识是冻结的,也就是说,他对培训后发生的事件一无所知。 这意味着它无法可靠地回答有关当前事件的问题。 对模型进行培训时,通常会限定它们对此类问题的回答。
幻觉
有人认为,LLM (大语言模型)在其参数中捕捉到了类似于一般本体的知识图谱表示:表示实体的事实和实体之间的关系。 在训练数据中经常出现的常见事实在知识图谱中得到了很好的体现。 但是,在训练数据中不可能有很多实例的利基知识,在知识图谱中只有近似的表示。 因此,LLM (大语言模型)对这些事实的理解是模糊的。
校准过程至关重要,在这一过程中,模型会对其已知信息进行校准。 错误往往发生在已知信息和未知信息之间的灰色地带,这凸显了区分相关细节的挑战。
培训费用昂贵
虽然 LLM (大语言模型)在特定领域的数据上经过训练后能够生成相关的问题回答,但其训练成本高昂,需要大量的数据和计算来开发。 同样,对模型进行微调也需要专业知识和时间,而且在这个过程中有可能 “遗忘 “其他重要功能。
RAG 如何帮助解决这一问题?
检索增强生成(RAG)通过将生成模型的参数知识与来自数据库等信息检索系统的外部源知识结合起来,帮助解决这一问题。 这些源知识将作为额外的上下文传递给模型,帮助模型生成与问题更相关的回答。
RAG 如何工作?
RAG 管道通常由三个主要部分组成:
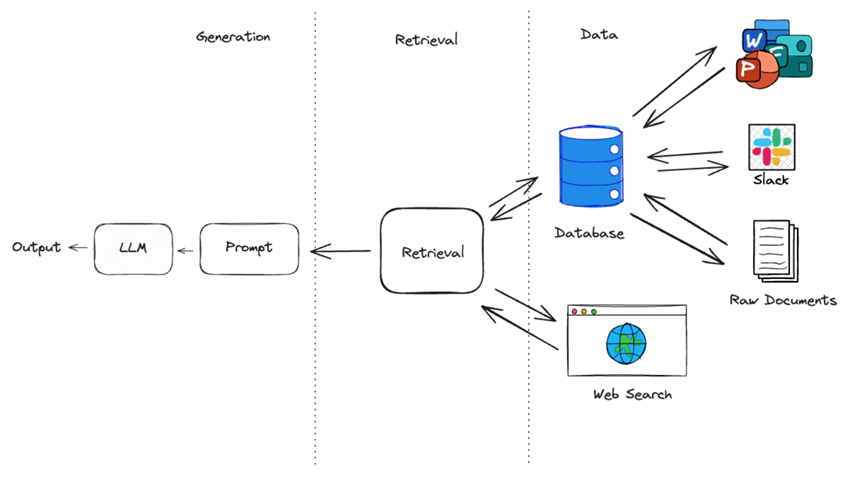
数据:包含回答问题的相关信息的数据集合(如文件、网页)。
检索: 能从数据中检索相关源知识的检索策略。
生成: 利用相关源知识,在 LLM 的帮助下生成回复。
RAG 管道流量
在与模型直接交互时,LLM (大语言模型)会收到一个问题,并根据其参数知识生成一个响应。 RAG 在此过程中增加了一个额外步骤,利用检索功能查找相关数据,为 LLM (大语言模型)建立额外的上下文。
在下面的例子中,我们使用密集向量检索策略从数据中检索相关的源知识。 然后将这些源知识作为上下文传递给 LLM(大语言模型),以生成响应。
RAG 不一定要使用密集矢量检索,它可以使用任何能从数据中检索出相关源知识的检索策略。 它可以是简单的关键词搜索,甚至是谷歌网页搜索。
我们将在今后的文章中介绍其他检索策略。
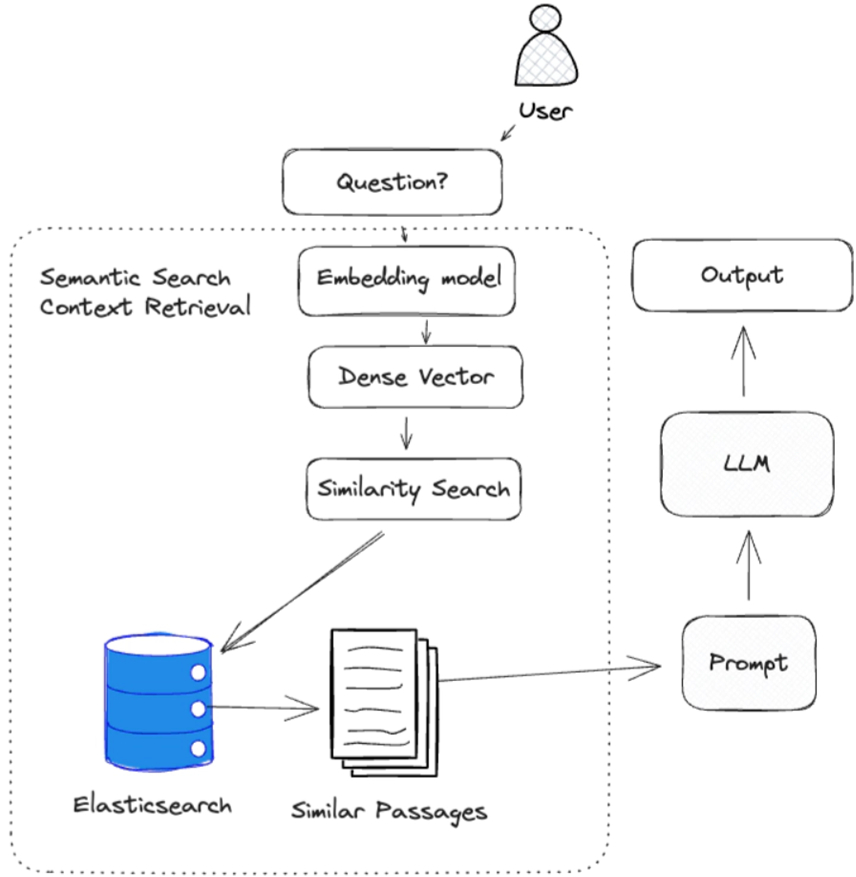
检索源知识
检索相关源知识是有效回答问题的关键。
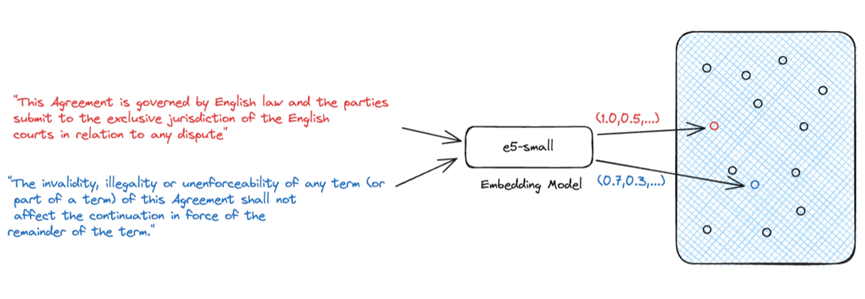
生成式人工智能最常用的检索方法是使用密集向量进行语义搜索。 语义搜索是一种需要嵌入模型将自然语言输入转化为表示源知识的密集向量的技术。 我们依靠这些密集向量来表示源知识,因为它们能够捕捉文本的语义。 这一点非常重要,因为它允许我们将源知识的语义与问题进行比较,以确定源知识是否与问题相关。
给定一个问题及其嵌入,我们就能找到最相关的源知识。
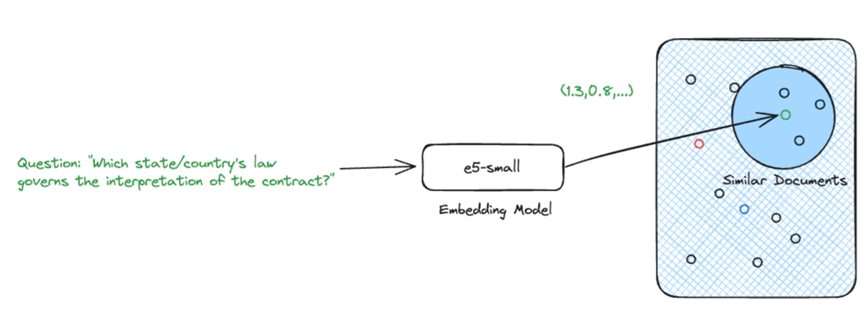
使用密集向量进行语义搜索并不是唯一的检索选择,但却是当今最流行的方法之一。 我们将在今后的文章中介绍其他方法。
RAG 的优势
训练后,LLM (大语言模型)被冻结。 模型的参数知识是固定的,无法更新。 但是,当我们在 RAG 管道中添加数据和检索时,我们可以根据底层数据源的变化更新源知识,而无需重新训练模型。
以源知识为基础
模型的响应也可以受限于只使用上下文中提供的源知识,这有助于限制幻觉。 这种方法还允许使用较小的、针对特定任务的 LLM(大语言模型),而不是大型的、通用的模型。 这样就能优先使用源知识来回答问题,而不是在训练过程中获得的一般知识。
在答复中引用资料来源
此外,RAG 还能提供用于回答问题的源知识的清晰可追溯性。 这对于合规性和监管原因非常重要,也有助于发现 LLM(大语言模型) 的幻觉。 这就是所谓的源跟踪。
行动中的 RAG
检索到相关源知识后,我们就可以利用它来生成对问题的回答。 为此,我们需要
建立背景:包含回答问题相关信息的源知识集合(如文档、网页)。 这为模型生成回复提供了背景。
提示模板:针对特定任务(回答问题、总结文本)用自然语言编写的模板。 用作 LLM (大语言模型)的输入。
问题:与任务相关的问题。 一旦有了这三个组件,我们就可以使用 LLM(大语言模型)生成对问题的回复。
RAG 面临的挑战
有效检索是有效回答问题的关键。 良好的检索可为上下文提供一系列不同的相关源知识。 然而,这与其说是一门科学,不如说是一门艺术,需要大量的实验才能获得成功,而且在很大程度上取决于使用情况。
精确的密集矢量
由于大型文档包含多种语义,因此难以用单个密集向量来表示。 为了实现有效的检索,我们需要将文档分解成较小的文本块,这些文本块可以准确地表示为单个密集向量。
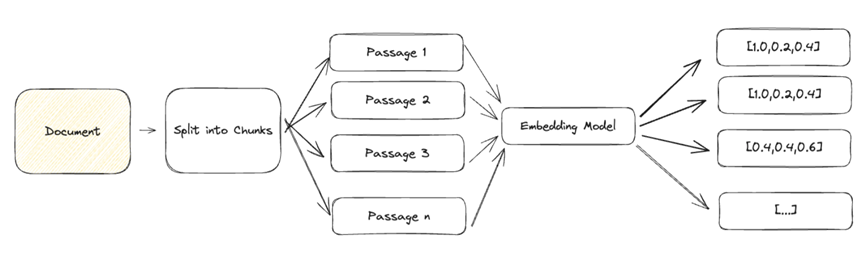
一般文本的常见方法是按段落分块,并将每个段落表示为一个密集的向量。 根据您的使用情况,您可能希望使用标题、小标题甚至句子将文档细分为若干小块。
大背景
在使用 LLM(大语言模型) 时,我们需要注意传递给模型的上下文的大小。
LLM (大语言模型)一次可处理的令牌数量有限制。 例如,GPT-3.5-turbo 有 4096个令牌的限制。
其次,随着情境的增加,产生的反应质量可能会下降,从而增加产生幻觉的风险。
较大的背景也需要更多的时间来处理,更重要的是,它们会增加 LLM 的成本。
这又回到了检索的艺术上。 我们需要在分块大小和嵌入准确性之间找到恰当的平衡点。
结论:
Retrieval Augmented Generation(检索增强生成)是一种强大的技术,可以通过提供相关的源知识作为上下文,帮助提高 LLM (大语言模型)生成的回复质量。 但 RAG 并不是灵丹妙药。它需要大量的实验和调整才能达到最佳效果,而且在很大程度上取决于您的使用情况。
本文翻译源自:https://www.elastic.co/search-labs/blog/retrieval-augmented-generation-rag