利用Python调用百度千帆大模型接口实战指南
百度宣布其先进的千帆大模型现在免费开放给公众使用,为开发者和企业提供了一个强大的AI驱动工具。本文将深入探讨如何利用百度千帆大模型的API接口,解锁人工智能的潜力。从基础的API调用到复杂的集成方案,我们将一步步指导用户如何通过简单的接口请求,实现自然语言处理、图像识别等高级功能。
您可以在API HUB找到大量AI技术类API,其中包含了百度千帆大模型。
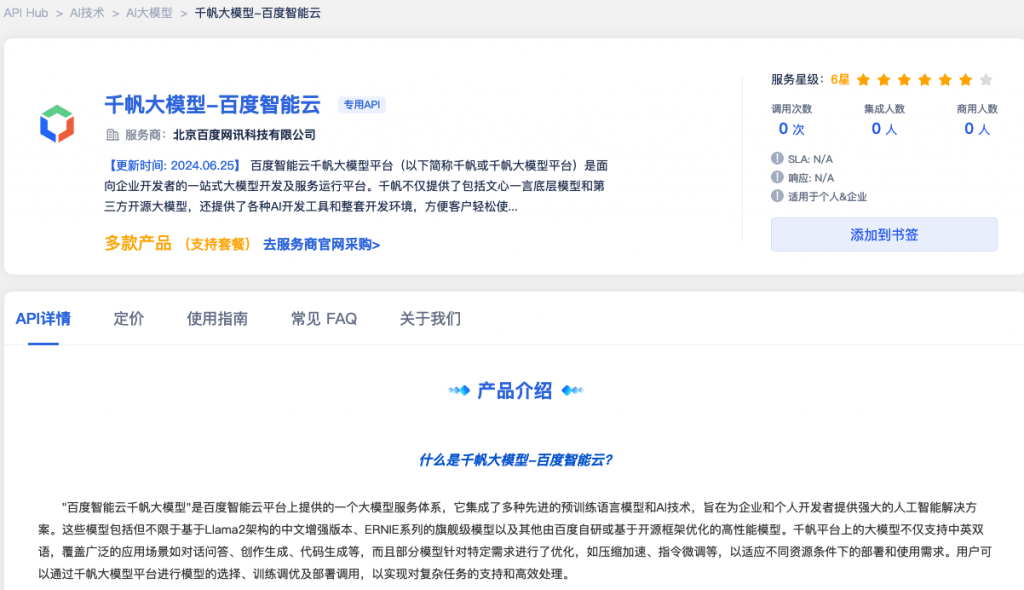 "百度智能云千帆大模型"是百度智能云平台上提供的一个大模型服务体系,它集成了多种先进的预训练语言模型和AI技术,旨在为企业和个人开发者提供强大的人工智能解决方案。这些模型包括但不限于基于Llama2架构的中文增强版本、ERNIE系列的旗舰级模型以及其他由百度自研或基于开源框架优化的高性能模型。千帆平台上的大模型不仅支持中英双语,覆盖广泛的应用场景如对话问答、创作生成、代码生成等,而且部分模型针对特定需求进行了优化,如压缩加速、指令微调等,以适应不同资源条件下的部署和使用需求。用户可以通过千帆大模型平台进行模型的选择、训练调优及部署调用,以实现对复杂任务的支持和高效处理。
"百度智能云千帆大模型"是百度智能云平台上提供的一个大模型服务体系,它集成了多种先进的预训练语言模型和AI技术,旨在为企业和个人开发者提供强大的人工智能解决方案。这些模型包括但不限于基于Llama2架构的中文增强版本、ERNIE系列的旗舰级模型以及其他由百度自研或基于开源框架优化的高性能模型。千帆平台上的大模型不仅支持中英双语,覆盖广泛的应用场景如对话问答、创作生成、代码生成等,而且部分模型针对特定需求进行了优化,如压缩加速、指令微调等,以适应不同资源条件下的部署和使用需求。用户可以通过千帆大模型平台进行模型的选择、训练调优及部署调用,以实现对复杂任务的支持和高效处理。
什么是API
API是一个软件解决方案,作为中介,使两个应用程序能够相互交互。以下一些特征让API变得更加有用和有价值:
- 遵守REST和HTTP等易于访问、广泛理解和开发人员友好的标准。
- API不仅仅是几行代码;这些是为移动开发人员等特定受众创建的。
- 这些有清晰的文档和版本,以满足用户的期望。
- 更好的治理和安全性,以及监控以管理性能和可扩展性。
一、核心功能介绍
1.模型相关
对话Chat:支持创建chat,用于发起一次对话。
续写Completions:支持创建completion,用于发起一次续写请求,不支持多轮会话等。
自定义模型:平台支持HuggingFace Transformer架构的自定义大模型导入,将自定义模型发布为服务,并支持通过相关API调用该服务。
图像Images:提供图像相关API能力。
Token计算,根据输入计算token数。
2.模型服务:提供创建服务、获取服务详情等API能力。
3.模型管理:提供获取模型、模型版本详情,获取用户/预置模型及将训练任务发布为模型等API能力。
4.模型调优:提供创建训练任务、任务运行、停止任务运行及获取任务运行详情等API能力。
5.数据管理:提供创建数据集等数据集管理、导入导出数据集任务、数据清洗任务管理等API能力。
6.Prompt工程:提供模板管理、Prompt优化任务、评估等API能力。
7.插件应用:提供知识库、智慧图问、天气等API能力。
二、如何申请千帆大模型API Key和Secret Key
进入百度智能云 千帆大模型平台。
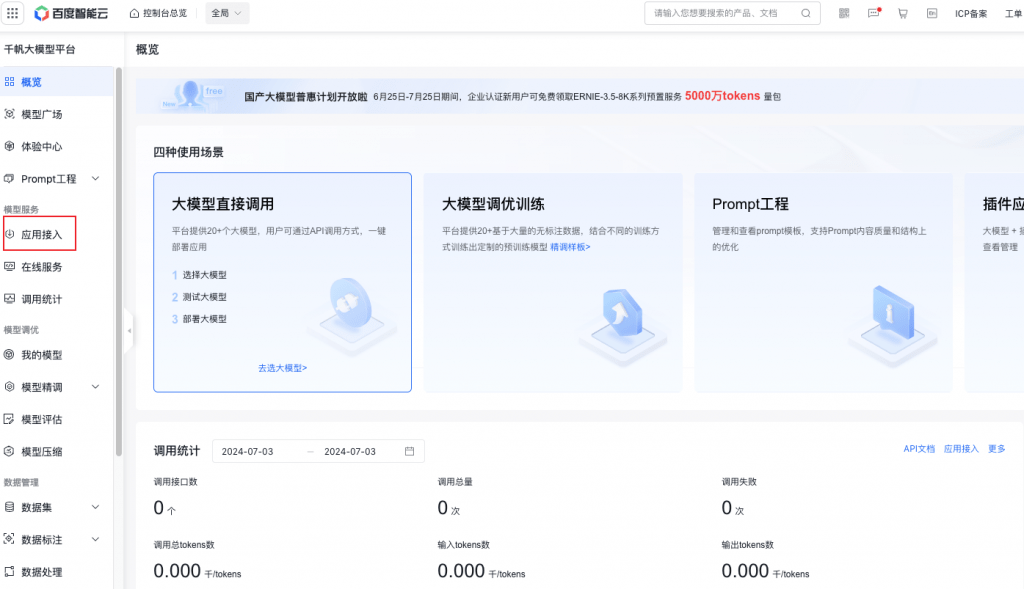 点击应用接入,进入应用列表
点击应用接入,进入应用列表
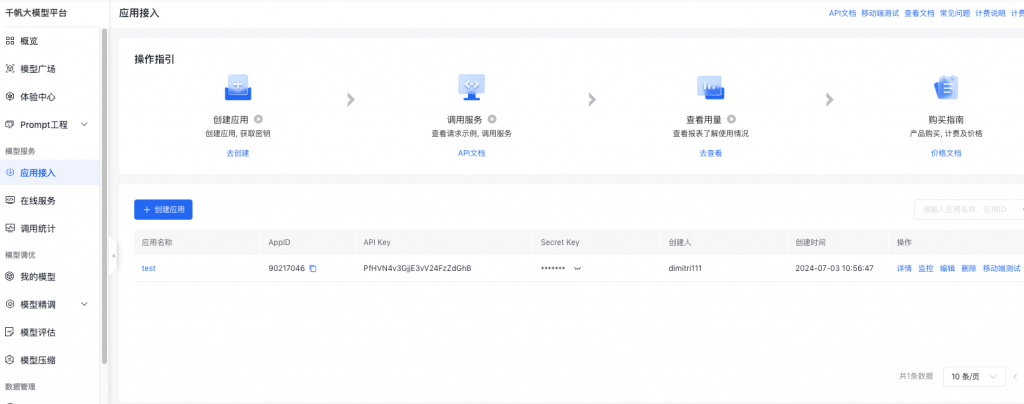 点击创建应用
点击创建应用
 先记录下这个秘钥后面调用需要用到
先记录下这个秘钥后面调用需要用到

三、Python调用千帆大模型接口的主要步骤如下
接口文档 地址:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/klqx7b1xf
基本信息
请求地址: https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie_speed
请求方式: POST
根据不同鉴权方式,查看对应 Header 参数。
- 访问凭证 access_token 鉴权
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| Content-Type | string | 是 | 固定值 application/json |
- 基于安全认证 AK/SK 进行签名计算鉴权
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| Content-Type | string | 是 | 固定值 application/json |
| x-bce-date | string | 否 | 当前时间,遵循 ISO8601 规范,格式如 2016-04-06T08:23:49Z |
| Authorization | string | 是 | 用于验证请求合法性的认证信息。更多内容请参考简介 – 相关参考Reference |
Query 参数
只有访问凭证 access_token 鉴权方式,需使用 Query 参数。
- 访问凭证 access_token 鉴权
| 名称 | 类型 | 必填 | 描述 | |
|---|---|---|---|---|
| access_token | string | 是 | 通过 API Key 和 Secret Key 获取的 access_token,参考 获取access_token – 千帆大模型平台 | 百度智能云文档 |
Body 参数
| 名称 | 类型 | 必填 | 描述 |
|---|---|---|---|
| messages | List(message) | 是 | 聊天上下文信息。 • messages 成员不能为空,1 个成员表示单轮对话,多个成员表示多轮对话 • 最后一个 message 为当前请求的信息,前面的 message 为历史对话信息 • 必须为奇数个成员,成员中 message 的 role 必须依次为 user、assistant • message 中的 content 总长度和 system 字段总内容不能超过 24000 个字符,且不能超过 6144 tokens |
| stream | bool | 否 | 是否以流式接口的形式返回数据,默认 false |
| temperature | float | 否 | 较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定。默认 0.95,范围 (0, 1.0],不能为 0 |
| top_p | float | 否 | 影响输出文本的多样性,取值越大,生成文本的多样性越强。默认 0.7,取值范围 [0, 1.0] |
| penalty_score | float | 否 | 通过对已生成的 token 增加惩罚,减少重复生成的现象。值越大表示惩罚越大。默认 1.0,取值范围:[1.0, 2.0] |
| system | string | 否 | 模型人设,主要用于人设设定。长度限制:message 中的 content 总长度和 system 字段总内容不能超过 24000 个字符,且不能超过 6144 tokens |
| stop | List(string) | 否 | 生成停止标识,当模型生成结果以 stop 中某个元素结尾时,停止文本生成。每个元素长度不超过 20 字符,最多 4 个元素 |
| max_output_tokens | int | 否 | 指定模型最大输出 token 数。如果设置此参数,范围 [2, 2048]。如果不设置此参数,最大输出 token 数为 1024 |
| frequency_penalty | float | 否 | 正值根据迄今为止文本中的现有频率对新 token 进行惩罚,从而降低模型逐字重复同一行的可能性;默认 0.1,取值范围 [-2.0, 2.0] |
| presence_penalty | float | 否 | 正值根据 token 记目前是否出现在文本中来对其进行惩罚,从而增加模型谈论新主题的可能性;默认 0.0,取值范围 [-2.0, 2.0] |
| user_id | string | 否 | 表示最终用户的唯一标识符 |
message 说明
| 名称 | 类型 | 描述 |
|---|---|---|
| role | string | 当前支持以下:• user: 表示用户• assistant: 表示对话助手 |
| content | string | 对话内容,不能为空 |
响应说明
部分参数如下。
| 名称 | 描述 |
|---|---|
| X-Ratelimit-Limit-Requests | 一分钟内允许的最大请求次数 |
| X-Ratelimit-Limit-Tokens | 一分钟内允许的最大 tokens 消耗,包含输入 tokens 和输出 tokens |
| X-Ratelimit-Remaining-Requests | 达到 RPM 速率限制前,剩余可发送的请求数配额,如果配额用完,将会在 0-60s 后刷新 |
| X-Ratelimit-Remaining-Tokens | 达到 TPM 速率限制前,剩余可消耗的 tokens 数配额,如果配额用完,将会在 0-60s 后刷新 |
响应体参数
| 名称 | 类型 | 描述 |
|---|---|---|
| id | string | 本轮对话的 id |
| object | string | 回包类型• chat.completion:多轮对话返回 |
| created | int | 时间戳 |
| sentence_id | int | 表示当前子句的序号。只有在流式接口模式下会返回该字段 |
| is_end | bool | 表示当前子句是否是最后一句。只有在流式接口模式下会返回该字段 |
| is_truncated | bool | 当前生成的结果是否被截断 |
| result | string | 对话返回结果 |
| need_clear_history | bool | 表示用户输入是否存在安全风险,是否关闭当前会话,清理历史会话信息。• true:是,表示用户输入存在安全风险,建议关闭当前会话,清理历史会话信息。• false:否,表示用户输入无安全风险 |
| ban_round | int | 当 need_clear_history 为 true 时,此字段会告知第几轮对话有敏感信息,如果是当前问题,ban_round=-1 |
| usage | usage | token 统计信息 |
usage 说明
| 名称 | 类型 | 描述 |
|---|---|---|
| prompt_tokens | int | 问题 tokens 数 |
| completion_tokens | int | 回答 tokens 数 |
| total_tokens | int | tokens 总数 |
注意 :同步模式和流式模式,响应参数返回不同,详细内容参考示例描述。
- 同步模式下,响应参数为以上字段的完整 json 包。
- 流式模式下,各字段的响应参数为 data: {响应参数}。
代码如下:
1 import requests
2 import json
3 import datetime
4
5 class QIANFAN:
6
7 _api_url = "https://aip.baidubce.com"
8
9 def __init__(self, api_key, secret_key):
10 self.API_KEY = api_key
11 self.SECRET_KEY = secret_key
12
13 url = self._api_url + "/oauth/2.0/token"
14 params = {"grant_type": "client_credentials", "client_id": self.API_KEY, "client_secret": self.SECRET_KEY}
15 result = self.http_request_v2(url, method="POST", params=params)
16 if 'access_token' in result:
17 self.access_token = result["access_token"]
18 else:
19 print(result)
20 exit()
21
22
23 def chat(self, model="ernie-lite-8k", message=None, **kwargs):
24 url = f"{self._api_url}/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/{model}?access_token={self.access_token}"
25
26 payload = json.dumps({
27 "messages": [{"role": "user", "content": message}],
28 "temperature": 0.95,
29 "penalty_score": 1
30 })
31
32 for key, value in kwargs.items():
33 payload[key] = value
34
35 print(payload)
36 response = self.http_request_v2(url, method="POST", params=payload)
37 return response
38
39
# 生成headers头
40 def headers(self, params=None):
41 headers = {}
42 headers['Content-Type'] = 'application/json'
43 return headers
44
45 def http_request_v2(self, url, method="GET", headers={}, params=None):
46 headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
47 if method == "GET":
48 response = requests.get(url)
49 elif method == "POST":
50 # data = bytes(json.dumps(params), 'utf-8')
51 response = requests.post(url, data= params)
52 elif method == "DELETE":
53 response = requests.delete(url, data= data)
54
55 result = response.json()
56 return result调用方法如下:
示例
API_KEY = "PfHVN4v3GjjE3vV24FzZdGhB"
SECRET_KEY = "***chat_client = QIANFAN(API_KEY, SECRET_KEY)
print(vars(chat_client))
result = chat_client.chat(model='ernie_speed', message="1加1为什么等于2?")
print(result["result"])
以上就是使用Python语言调用千帆大模型的全部过程和代码示例。