利用python语言调用腾讯混元大模型接口实战指南
作者:幂简科技 · 2024-06-17 · 阅读时间:18分钟
阅读本文,可以轻松了解并使用Python对接调用腾讯混元大模型API。
什么是混元大模型
“腾讯元器”是基于腾讯混元大模型的一站式智能体制作平台,支持通过下述能力对大模型进行增强:
- 提示词,包含详细设定(system prompt),开场白,建议引导问题。
- 插件(外部API),目前支持勾选多个插件。官方插件包含微信搜一搜、PDF摘要&解析、混元图片生成,也支持用户自定义插件。
- 知识库,当前版本支持doc和txt两种格式。
- 工作流,一种“流程图”式的低代码编辑工具,可以用来做一个“高级版”插件。在工作流里,可以任意编排插件、知识库、大模型节点的工作顺序和调用传参,从而精确控制智能体中部分任务的运行逻辑。
通过元器平台制作的智能体,目前支持32k token上下文长度(某次回答过程中的提示词+机器回答的token长度,一个token约为1.8个中文字符)。工作流的超时运行时间为5分钟。智能体的回复上限时间是90s。
什么是API接口
API是一个软件解决方案,作为中介,使两个应用程序能够相互交互。以下一些特征让API变得更加有用和有价值:
- 遵守REST和HTTP等易于访问、广泛理解和开发人员友好的标准。
- API不仅仅是几行代码;这些是为移动开发人员等特定受众创建的。
- 这些有清晰的文档和版本,以满足用户的期望。
- 更好的治理和安全性,以及监控以管理性能和可扩展性。
Python编写API接口的主要步骤如下:
登录并注册账号
可以通过 幂简集成-API HUB 快速找到大量AI技术相关API,心仪的API可以在登录后添加到个人书签,便于下次使用快速查找。
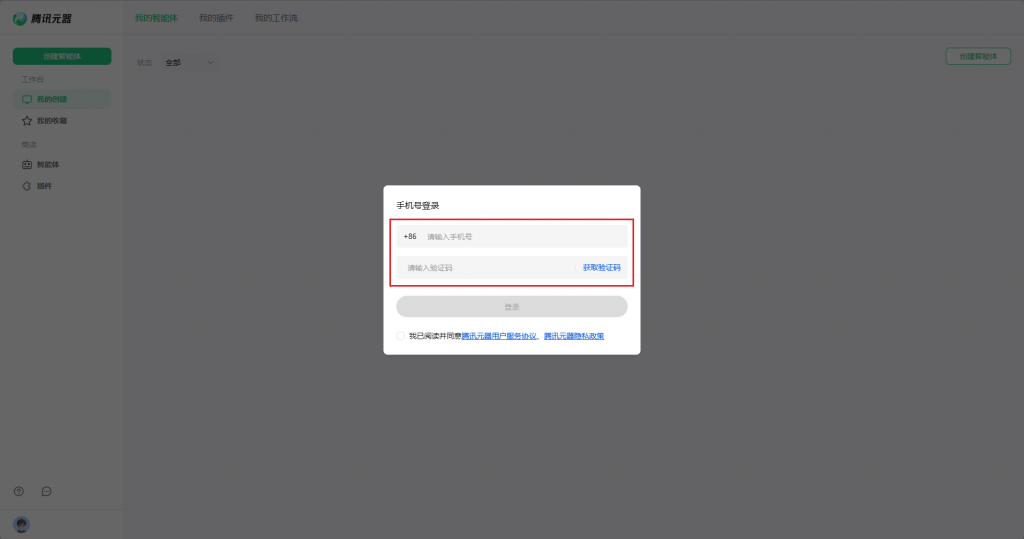
点击跳转 腾讯混元 官网,点击“腾讯元器”,输入手机号码并通过验证吗登录。
创建智能体
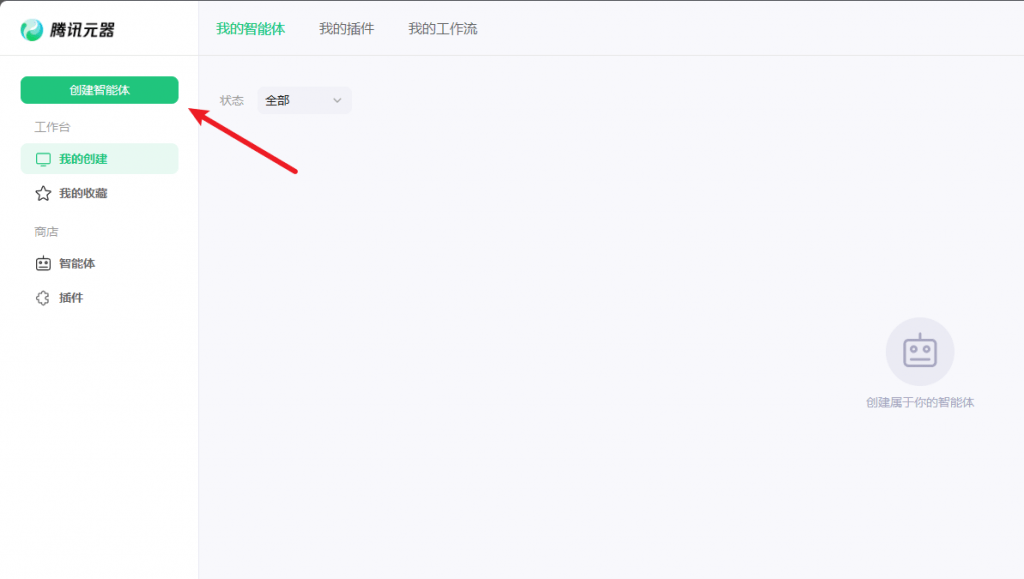
登录成功后,点击“创建智能体”
输入要创建智能体的名称、简介、头像(可以AI生成)、详细设定等相关信息~
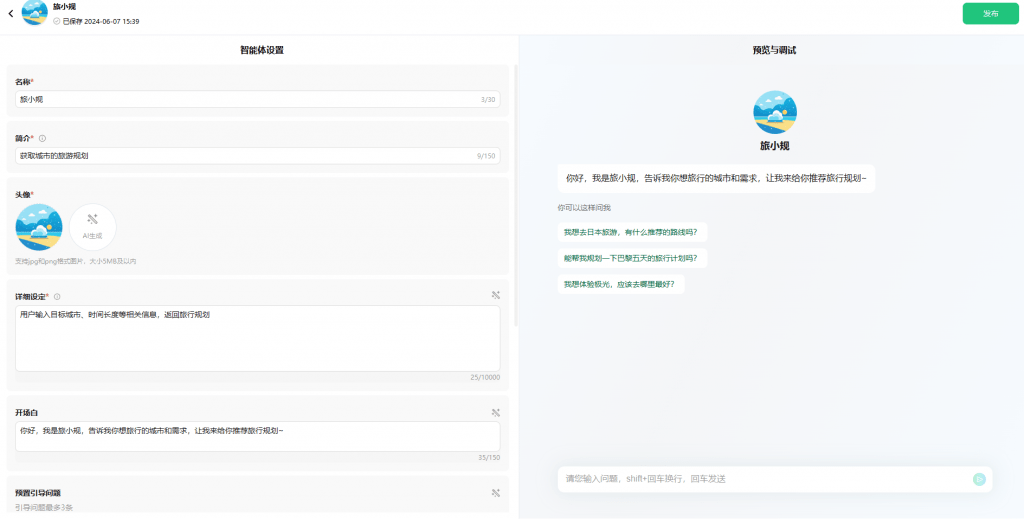
还可以添加丰富的插件、知识库、工作流等~

每一项表单的编辑后,右边会自动更新智能体的配置(预计有3-5s左右延迟),我们就可以即时查看智能体在配置更新后的效果~
发布智能体
调试没有问题后就可以发布智能体,并等待审核成功~
如果使用API调用的方式,不需要选择发布平台
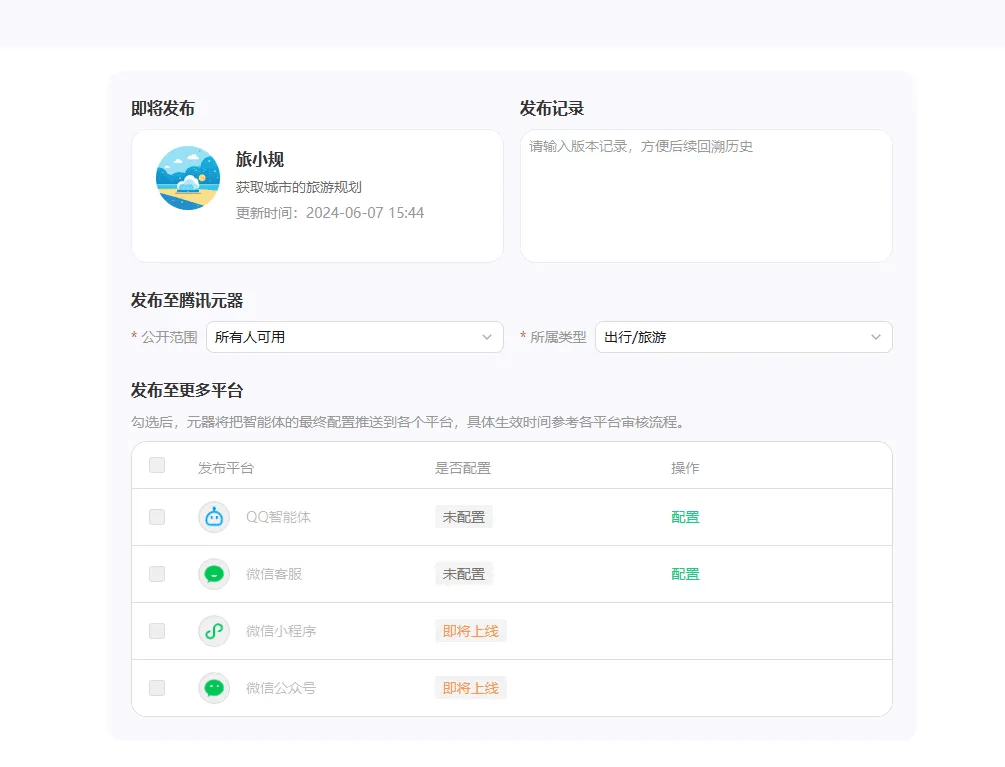
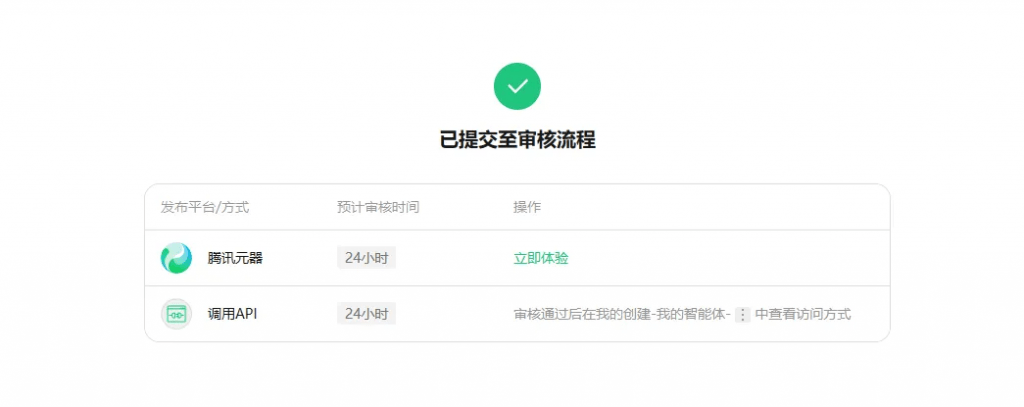
获取相关验证信息
审核通过后,到我的创建中找到创建的智能体
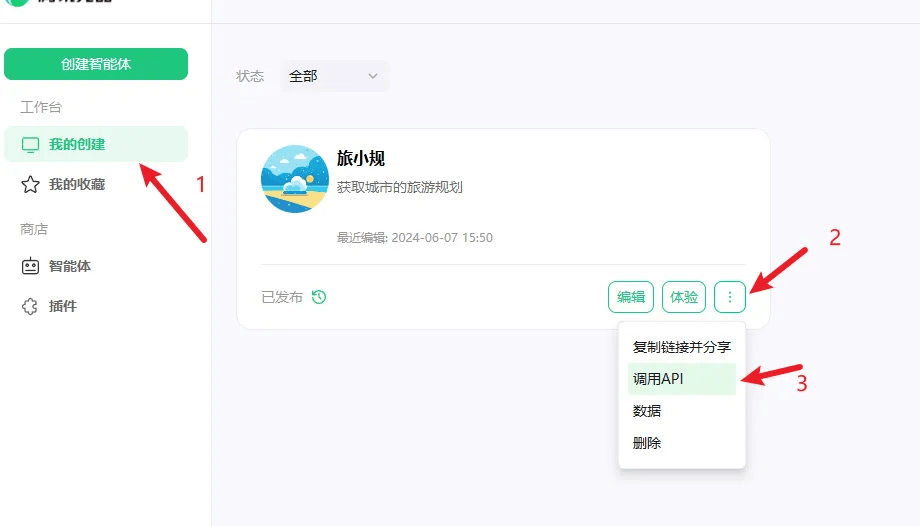
在弹窗中复制自己的智能体ID和Token(注意不要泄露,泄露后要及时重置)
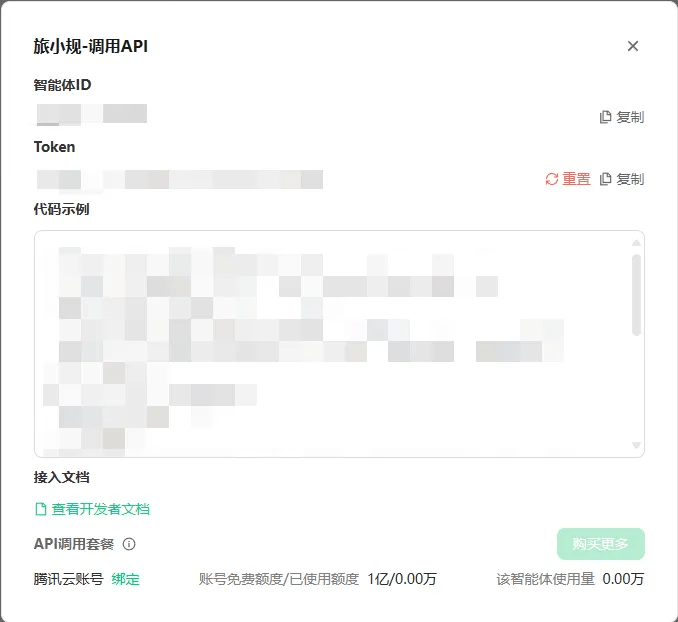
发送信息
API服务地址
请求参数
| 参数名 | 类型 | 是否必选 | 说明 |
| assistant_id | string | 是 | 助手ID |
| version | number | 否 | 助手版本 (仅对内部开放) |
| user_id | string | 是 | 用户ID,调用者业务侧的用户ID,会影响智能体的数据统计,建议按实际情况填写 |
| stream | bool | 否 | 是否以流式接口的形式返回数据,默认false |
| chat_type | string | 否 | 默认为published,传preview时,表示使用草稿态智能体 (仅对内部开放) |
| messages | list | 是 | 会话内容, 长度最多为40, 按对话时间从旧到新在数组中排列 |
| messages[n].role | string | 是 | 角色, ‘user’或者’assistant’, 在message中必须是user与assistant交替(一问一答) |
| messages[n].content | list | 是 | 可以传入多种类型的内容,如图片、文件或文本 |
| messages[n].content[m].type | string | 否 | 内容的类型,可选参数为’text’或’file_url’ |
| messages[n].content[m].text | string | 否 | 当type为text时使用,表示具体的文本内容 |
| messages[n].content[m].file_url | object | 否 | 当type为file_url时使用,表示具体的文件内容 |
| messages[n].content[m].file_url.type | string | 否 | 文件的类型,例如image/video/audio/pdf/doc/txt等 |
| messages[n].content[m].file_url.url | string | 否 | 文件的url |
响应参数
返回格式application/json,body参数如下:
| 参数名 | 类型 | 说明 |
| id | string | 此次请求的id |
| created | number | unix时间戳 |
| choices | list | 返回的回复, 当前仅有一个 |
| choices[n].index | number | 第几个回复 |
| choices[n].finish_reason | string | “stop”表示正常结束,”sensitive”表示审核不通过”tool_fail”表示调用工具失败 |
| choices[n].message | json | 返回的内容 |
| choices[n].message.role | string | 角色名称 |
| choices[n].message.content | string | 内容详情 |
| choices[n].message.steps | list | 助手的执行步骤 |
| choices[n].message.steps[m].role | string | 执行步骤中的角色名称,assistant表示模型,tool表示工具调用 |
| choices[n].message.steps[m].content | string | 执行步骤的结果,当角色为assistant时表示模型的输出内容,当角色为tool时表示工具的输出内容 |
| choices[n].message.steps[m].tool_call_id | string | 角色为tool时有效,内容为模型生成的工具调用中的唯一ID |
| choices[n].message.steps[m].tool_calls | list | 模型生成的工具调用 |
| choices[n].message.steps[m].tool_calls[i].id | string | 工具调用的唯一ID |
| choices[n].message.steps[m].tool_calls[i].type | string | 调用的工具类型,当前只支持function |
| choices[n].message.steps[m].tool_calls[i].function | object | 具体调用的function |
| choices[n].message.steps[m].tool_calls[i].function.name | string | function名称 |
| choices[n].message.steps[m].tool_calls[i].function.desc | string | function描述 |
| choices[n].message.steps[m].tool_calls[i].function.type | string | function类型,当前支持tool/knowledge/workflow |
| choices[n].message.steps[m].tool_calls[i].function.arguments | string | 调用function的参数,JSON格式 |
| choices[n].message.steps[m].usage | object | 当前执行步骤的token使用量 |
| choices[n].message.steps[m].usage.prompt_tokens | number | 问题token使用量 |
| choices[n].message.steps[m].usage.completion_tokens | number | 回答token使用量 |
| choices[n].message.steps[m].usage.total_tokens | number | token总使用量 |
| choices[n].message.steps[m].time_cost | number | 当前执行步骤的耗时 |
| choices[n].delta | json | 返回的内容(流式返回) |
| choices[n].delta.role | string | 角色名称,assistant表示模型,tool表示工具调用(流式返回) |
| choices[n].delta.content | string | 内容详情,当角色为assistant时表示模型的输出内容,当角色为tool时表示工具的输出内容(流式返回) |
| choices[n].delta.tool_call_id | string | 角色为tool时有效,内容为模型生成的工具调用中对应的tool_call ID (流式返回) |
| choices[n].delta.tool_calls | list | 模型生成的工具调用(流式返回) |
| choices[n].delta.tool_calls[m].id | string | 工具调用的唯一id(流式返回) |
| choices[n].delta.tool_calls[m].type | string | 调用的工具类型,当前只支持function(流式返回) |
| choices[n].delta.tool_calls[m].function | object | 具体调用的function(流式返回) |
| choices[n].delta.tool_calls[m].function.name | string | function名称(流式返回) |
| choices[n].delta.tool_calls[m].function.desc | string | function描述(流式返回) |
| choices[n].delta.tool_calls[m].function.type | string | function类型,当前支持tool/knowledge/workflow(流式返回) |
| choices[n].delta.tool_calls[m].function.arguments | string | 调用function的参数,JSON格式(流式返回) |
| choices[n].delta.time_cost | number | 当前执行步骤的耗时(流式返回) |
| assistant_id | string | 实际使用的助手id |
| usage | object | token使用量 |
| usage.prompt_tokens | number | 问题token使用量 |
| usage.completion_tokens | number | 回答token使用量 |
| usage.total_tokens | number | token总使用量 |
调用示例
import requests
import json
# 定义 API 的 URL
url = 'https://open.hunyuan.tencent.com/openapi/v1/agent/chat/completions'
# 定义请求头
headers = {
'X-Source': 'openapi',
'Content-Type': 'application/json',
'Authorization': 'Bearer <元器用户的token>'
}
# 定义请求体
data = {
"assistant_id": "I4aVQTHpsJro",
"user_id": "username",
"stream": False,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "生成去张家口旅行的计划"
}
]
}
]
}
# 将请求体转换为 JSON 格式的字符串
json_data = json.dumps(data)
# 发送 POST 请求
response = requests.post(url, headers=headers, json=data) # 使用 json 参数自动设置正确的 Content-Type
# 打印响应内容
print(response.text)调用成功:
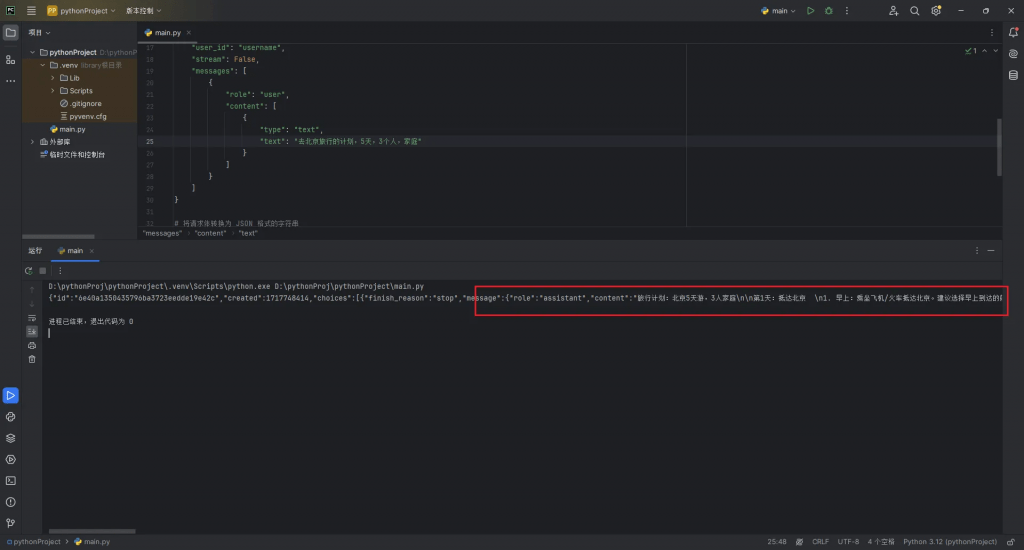
错误码
| 序号 | 错误码 | 解释 |
| 1 | 400 | 请求参数错误 |
| 待补充… |
计费说明
当前每个元器用户有100w的token体验使用额度,额度用完后,将无法调用。我们会尽快上线API付费能力,付费后,可以支持更多次调用。
最后
如果你想找到更多的大模型,欢迎到 幂简集成 找找看,找到自己中意的大模型。
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密