

GraphQL API渗透测试指南
可能很多小伙伴都不知道这个是什么,其实直译就可以了:面向python的ArcGIS相关功能接口。在Pro的Python管理器中查看是这样的:
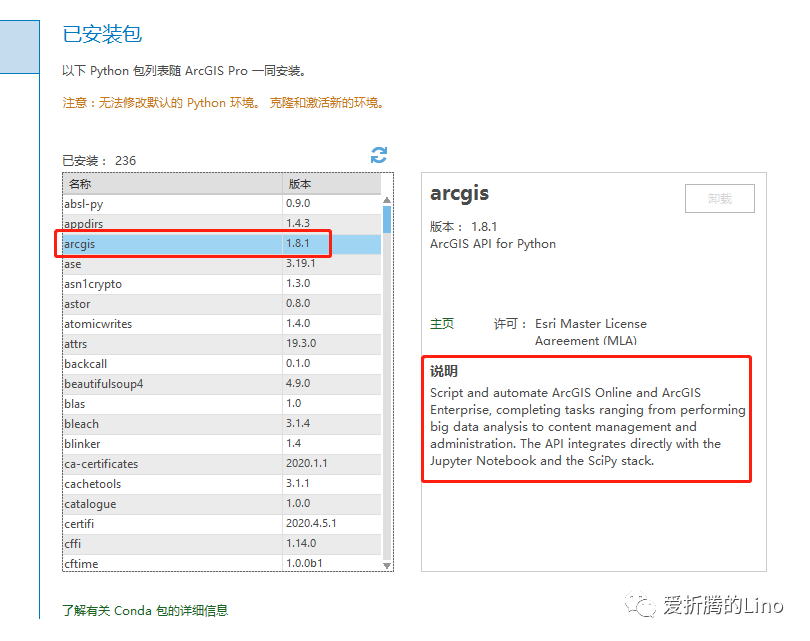
从说明里面能到到,它主要是服务于Online以及Enterprise,其实就是server、portal那一套。空口说无凭证,我们直接从接口文档里面看功能。
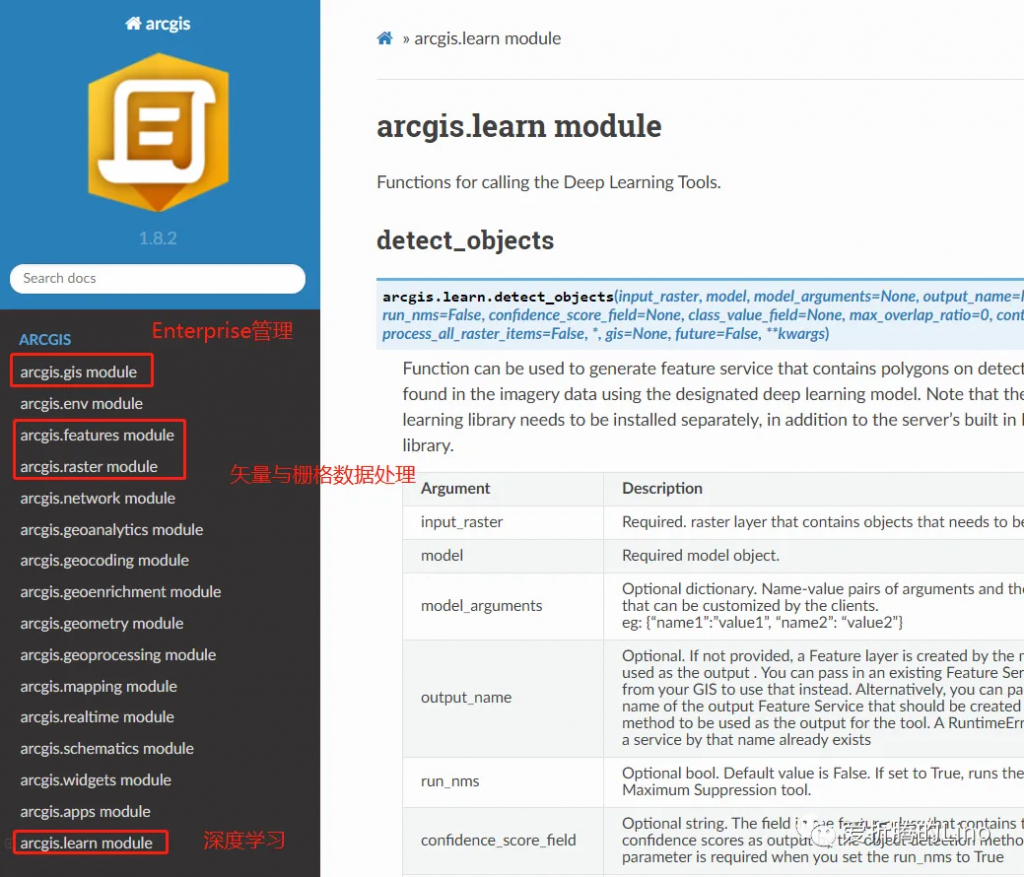
上图中跟我们有关的是arcgis.learn(深度学习)模块,其余的部分在本文中不会提到。如果想学习的话,可以参考官网的教程以及示例笔记本(notebook),里面很详细的。
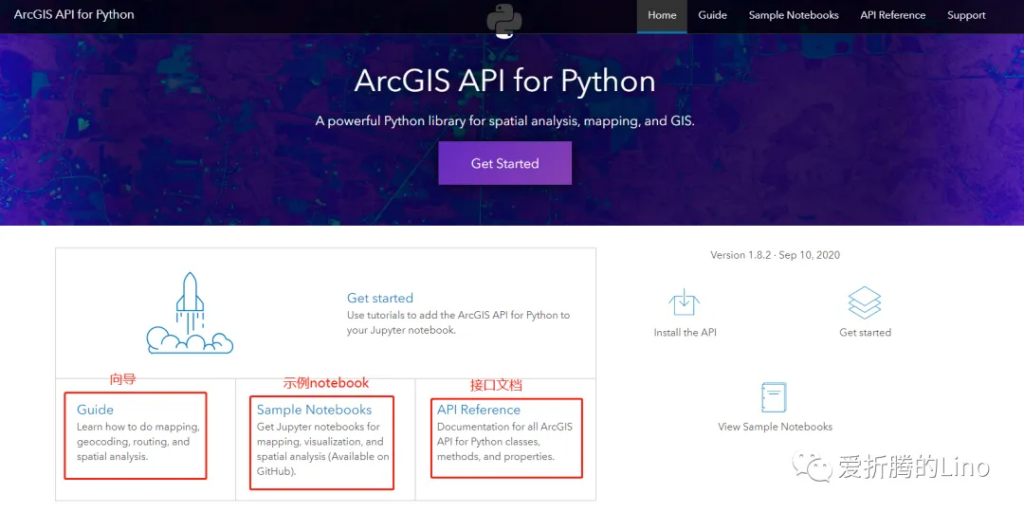
其中最重要的是需要看Sample Notebooks,里面讲的很全很详细(墙裂推荐)。这个部分,可以根据自己需求选择性的去看某一部分。
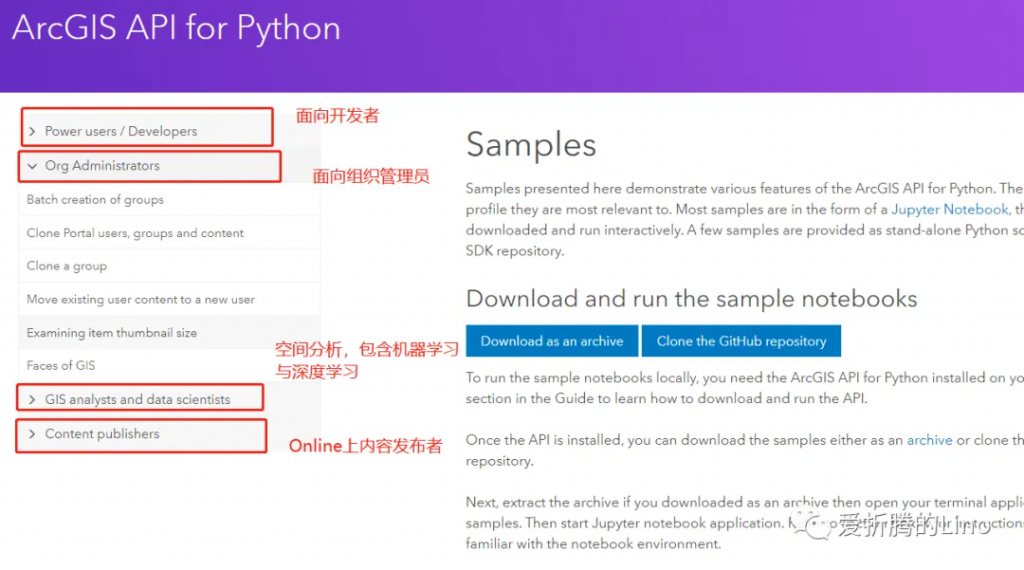
那咱们主要是深度学习,就看上图中的第三部分就好了(友情提示,第三部分很多示例笔记本)。随便点一个深度学习相关的,比如说之前公众号中写过的《利用深度学习检测路面损坏情况》:
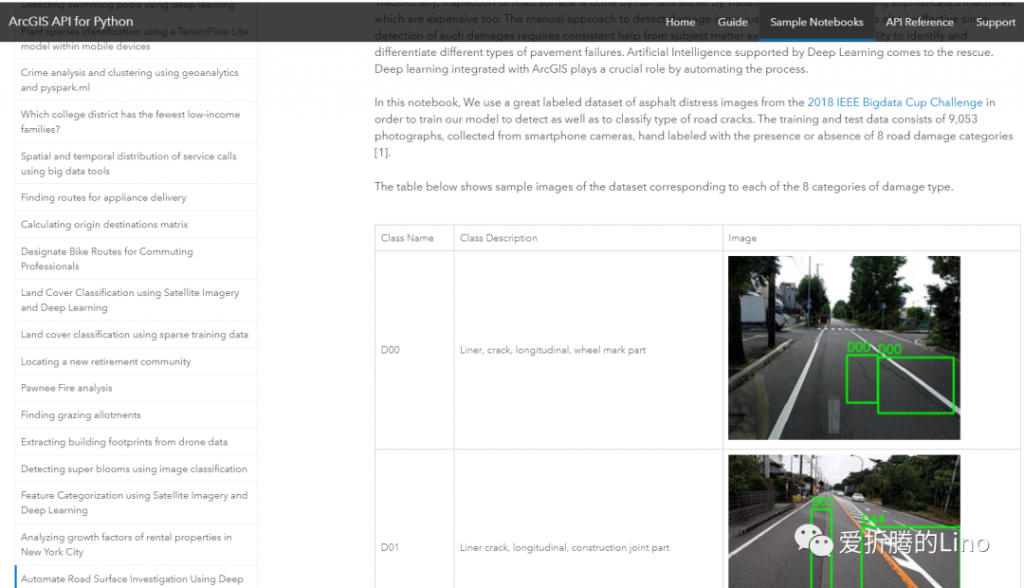
还有很多机器学习相关、空间分析相关的,大家可以自己深入看一下,但是要深入看的的话需要Python基础以及ArcGIS相关基础。
在深度学习工作流中,老三步:样本制作 -> 模型训练 -> 推理。其中使用ArcGIS API for Python的是模型训练环节,其实推理阶段倒不是不能使用API去做,只是你需要一个Image Server,当然如果有多个的话,还是很推荐你使用集群去做推理的。
让我们来看一下arcgis.learn模块的东西:
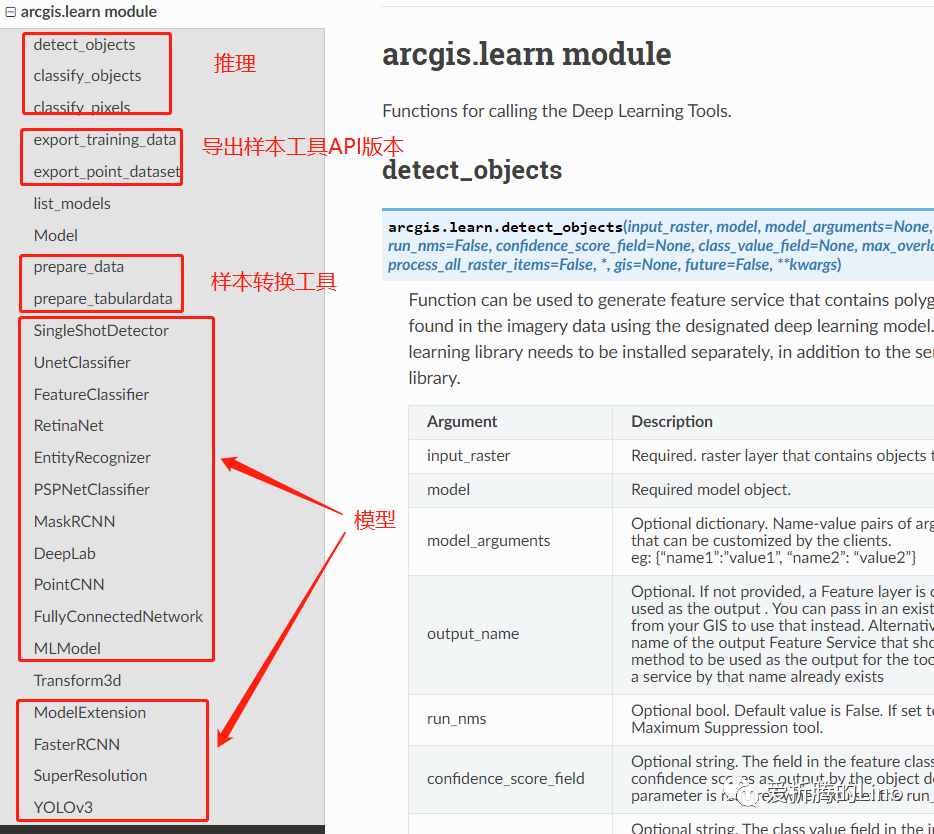
可能会有人问,样本转换工具是干啥的?如果你之前没有接触过编程,(敲黑板)那得特意留意一下我下面讲的内容:
首先,我们使用ArcGIS Pro导出样本之后,是这个样子的:
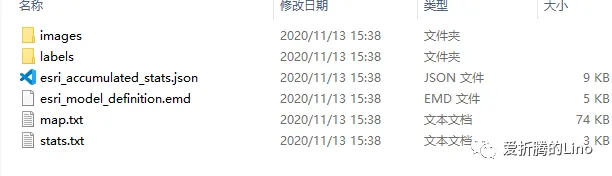
然后,这个文件夹里面存储着很多图片,是没办法直接使用的,因为他们是存储在计算机磁盘空间中的。因此,要使用这些图片、标签等等,就需要做转化,将样本文件从磁盘空间中加载到计算机内存中。这个时候就需要用到样本转换工具,在Pro中工具(下图中的训练深度学习模型工具)内部其实也封装了这个过程。
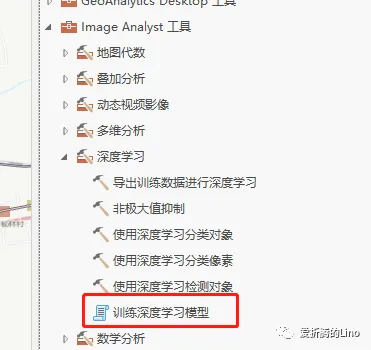
通过使用API会让你看到更多工具内部看不到的过程,可能第一次会有所疑惑,用多了就懂了。
关于模型那块是干嘛的就不用我说啦吧,但是其实你发现,ArcGIS API for Python的模型比ArcGIS Pro中的要多很多。所以强烈推荐你们使用API做训练,因为有更多模型,而且不管是ArcGIS Pro训练深度学习模型工具中有没有的模型,都可以使用Pro去做推理。唯一一个需要注意的是API与Pro的版本对应关系,所以建议你们使用最新版本Pro。
另外,API是完全开源的,有兴趣的话可以去github上查看更多源码。
好了,看完上面之后下面可以愉快的coding了。真的很简单,你们信我。而且简单的同时你可以训练出世界顶级模型(这句话可不是我说的,是fastai作者说的)。因为arcgis.learn模块内部其实封装的是fastai框架,这个框架的作者在kaggle上很出名的,感兴趣的可以查一下。
不说那么多其他的,那就,来吧,展示:
首先打开notebook,没有用过的可以参考我之前的文章:《为什么选择在Jupyter Notebook中编写代码》,然后导包:
from arcgis.learn import prepare_data,UnetClassifier其中prepare_data是样本转换工具,UnetClassifer是模型,在本场景中使用的是像素分类,小麦提取。你可以按照自己需求去导入模型,代码上差异并不是很大。
另外不同场景的模型在之前的文章中有总结过:《ArcGIS API for Python:深度学习模块概览》,不熟悉的可以点击查看。
然后使用`prepare_data`将样本加载到内存中:
# path是样本文件夹路径
path = r'E:\deeplearning\data\dongxiaomai\xiaomai_samplearea_tra30'
data = prepare_data(path,batch_size=16,val_split_pct=0.2)
data
prepare_data方法有几个参数需要注意一下:
path:样本文件夹,必填。
chip_size:样本切片大小。
val_split_pct:验证集划分比重。
bach_size:批大小。
除了一个path是必填的之外,其余的都可以根据实际情况选填。除了上面几个参数之外,接口文档中还有更详细的说明: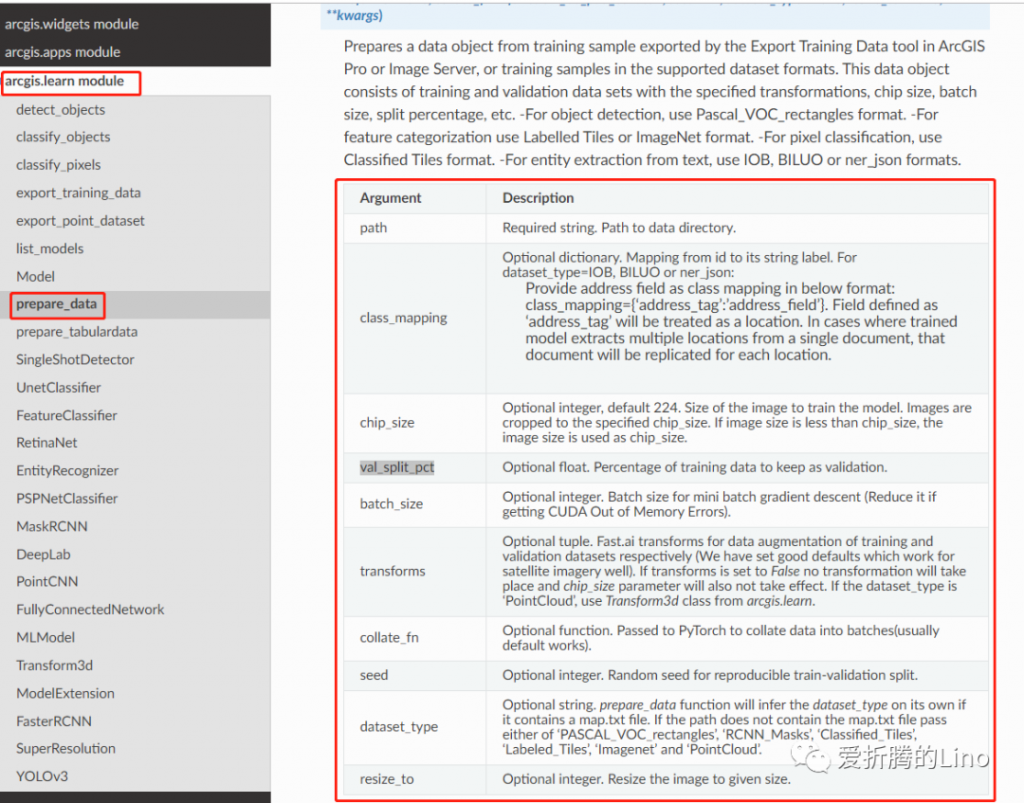
一定要学会从接口文档中查看参数信息
在加载完数据值后,还可以查看一下我们的样本数据大概都是啥样的:
data.show_batch()上图中红色半透明部分是我标注的样本,在data.show_batch方法里,会将样本叠在原始影像上,从而很方便的查看一个batch中的数据是啥样的。你可以多运行几次这行代码看看。
数据加载完成后,便可以实例化我们的模型:
model = UnetClassifier(data)这一步就很简单了,直接模型括号里面填上上一部中加载的样本对象。然后使用model.lr_find()函数查找学习率:
lr = model.lr_find()
lr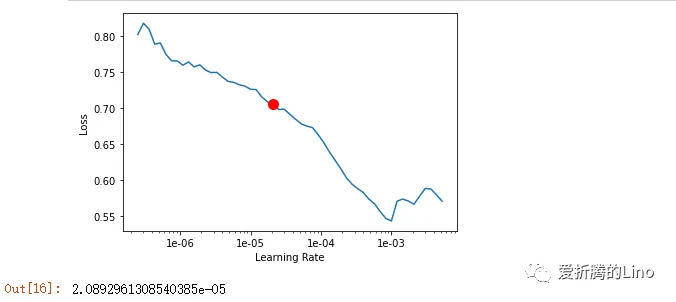
这一步是固定写法,就是查找最合适的学习率。学习率查找完成后,便可以训练模型了:
model.fit(200,lr)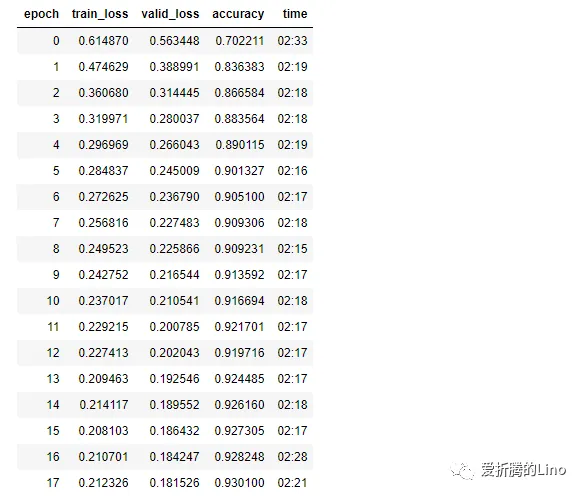
训练模型中有几个参数注意一下:
在接口文档中,此部分要找到对应的模型下面,查接口参数:
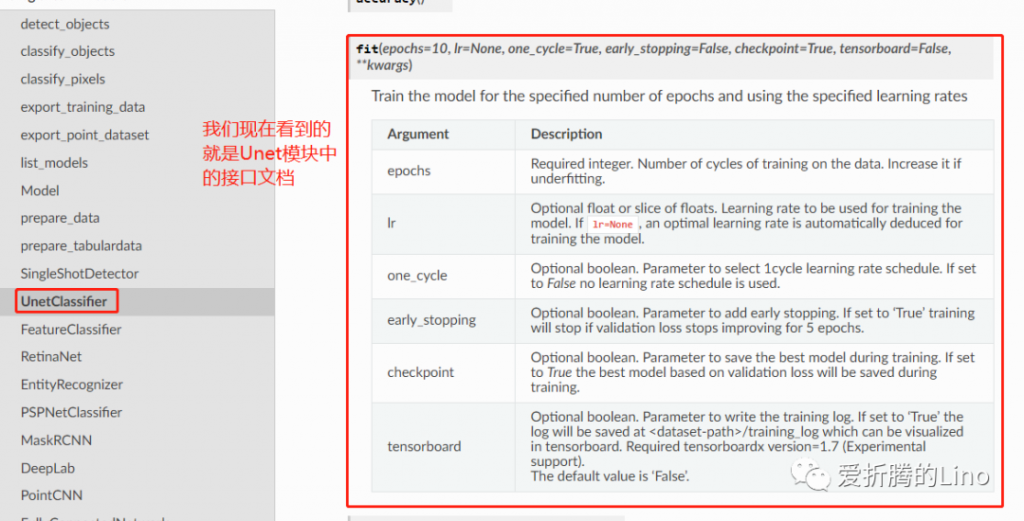
训练完成之后,可以查看一下损失曲线:
model.plot_losses()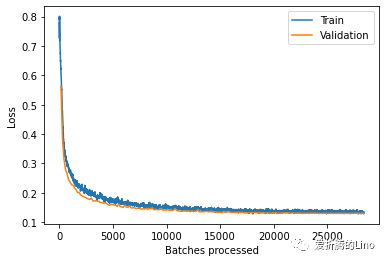
固定写法,不需要改动。
还可以使用model.show_results方法查看当前模型在验证集上的表现情况:
model.show_results()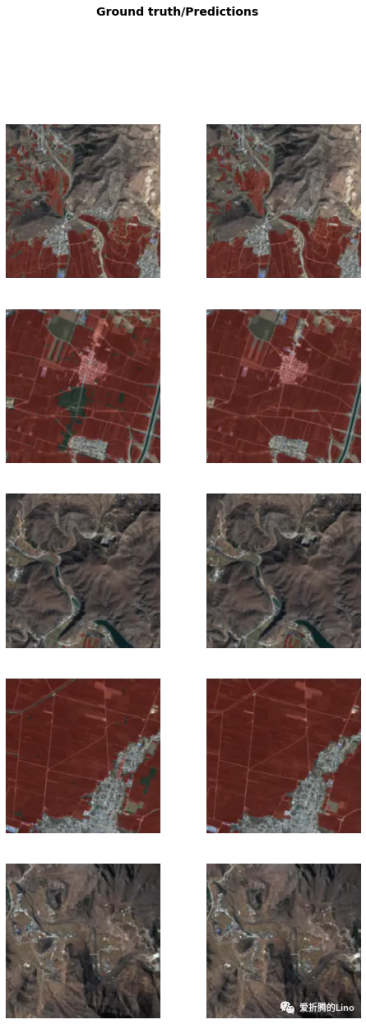
左边为真实标签,右边为当前模型推理所得。这种方法可以很直观的看到模型的表现如何。另外除了此种方法之外,还有其他精度指标可查看:
model.mIOU()
因为是图像分割,所以比较在意mIOU,其他的模型视情况选择精度指标查看。接口文档中都可以查到,比如说本文中用到的mIOU指标,在接口文档中查看:
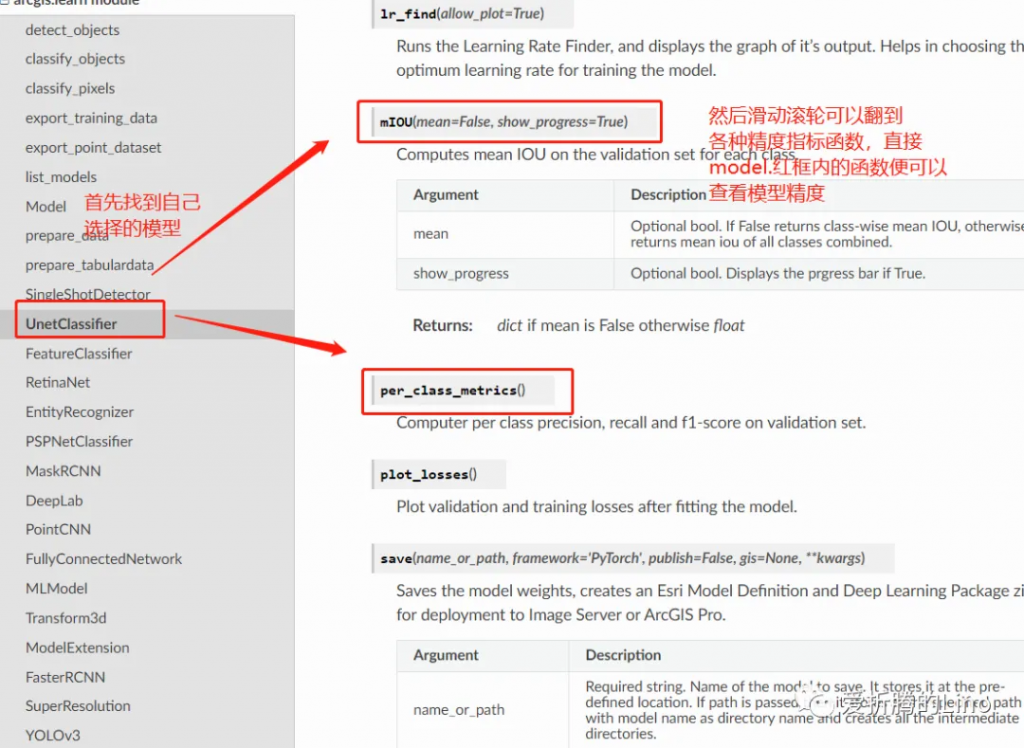
如果说,你对模型满意的话,便可以使用model.save方法保存模型了:
model.save(r'E:\deeplearning\model\dongxiaomai\unet_batchsize16_chipsize224_acc86')固定写法,替换掉文件夹路径即可。到文件夹中查看如下:
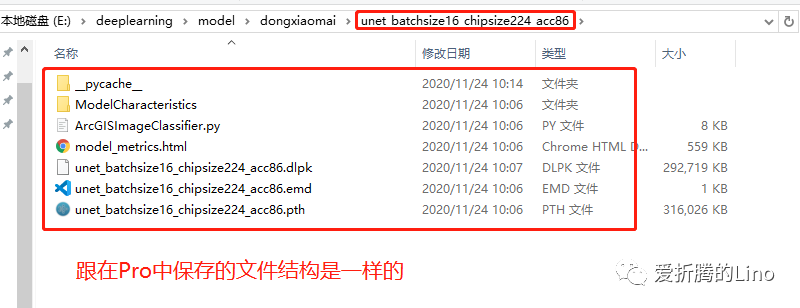
然后便可以使用ArcGIS Pro进行推理了。推理阶段在此处就不讲了。
肯定有人看完上面,觉得还不是很清晰,不会咋办。那你来打我,其实改动的地方很少的,我们来看一下去掉每一行运行结果后的完整代码:
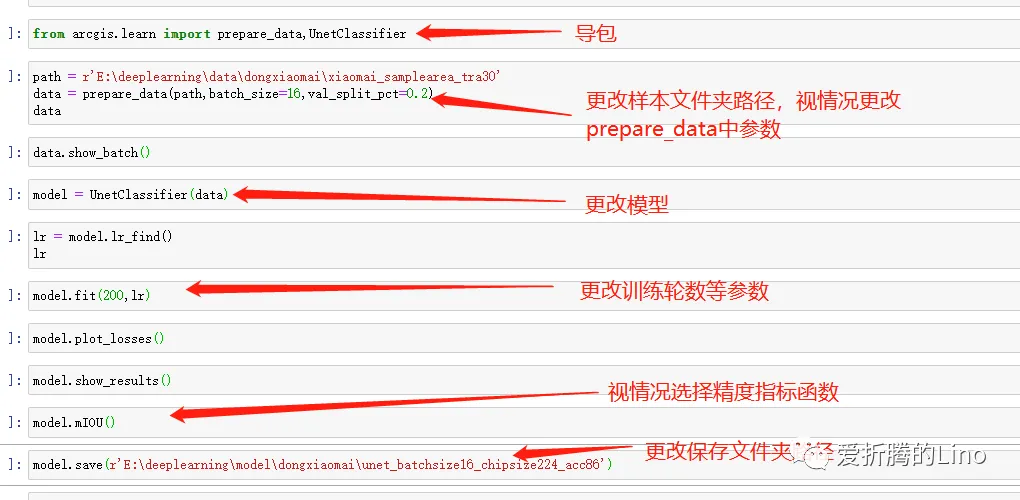
其中小部分都是固定写法,大部分都是固定格式,小部分需要根据模型不同更改写法。
这么短几行代码,你去写一个月,还不会,那你来打我。会不会python影响的已经不大了,折腾吧。不得不吹一下,把深度学习封装成如此简洁易用,确实很厉害。
文章转自微信公众号@数读城事
GraphQL API渗透测试指南
Python + BaiduTransAPI :快速检索千篇英文文献(附源码)

掌握ChatGPT API集成的方便指南
node.js + express + docker + mysql + jwt 实现用户管理restful api
nodejs + mongodb 编写 restful 风格博客 api
表格插件wpDataTables-将 WordPress 表与 Google Sheets API 连接
手把手教你用Python和Flask创建REST API
使用 Django 和 Django REST 框架构建 RESTful API:实现 CRUD 操作
ASP.NET Web API快速入门介绍