

文心一言写代码:代码生成力的探索

零一万物公司推出的AI模型系列引起了业界的广泛关注。本文将深入分析其中的三款主要模型,并着重探讨Yi-Large模型的常用提示词和应用技巧。
Yi-Large是零一万物公司推出的旗舰级AI模型,主要对标早期版本的GPT-4。它在指令遵从能力方面表现出色,综合性能优秀,然而在代码生成能力上仍有提升空间。该模型适合需要高精度语言生成的应用场景,如技术文档编写、复杂问题解答等。
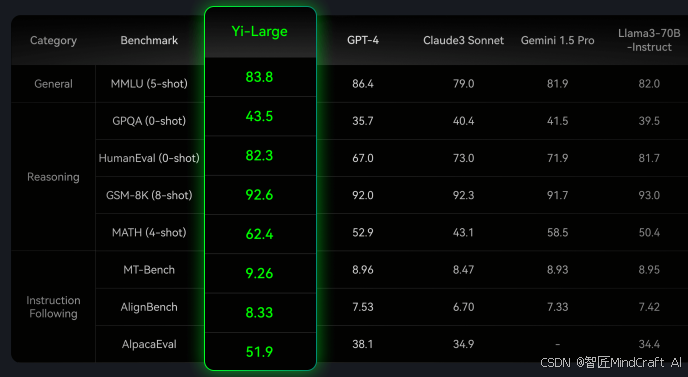
Yi-Large模型不仅在语言理解上表现卓越,还具备一定的创新能力。以下是其主要技术特点:
Yi-Spark是零一万物公司推出的经济型模型,以其极具竞争力的价格优势著称,每百万tokens仅需1元。这使得它成为预算有限的用户在基础问答任务中的可靠选择。与市场上的其他模型相比,Yi-Spark在性能上优于免费模型,略逊于doubao-pro,与deepseek和GLM4-Air存在明显差距。
Yi-Spark的应用场景广泛,包括但不限于:
Yi-Vision是零一万物公司推出的视觉语言模型,结合了低成本和高性能的特点。每百万tokens的成本为6元,同时在性能上与GLM4V相当,并超越了qwen-vl。
为了使用Yi LLM的集成,我们首先需要安装相关的包:
%pip install -qU langchain-community在继续之前,请确保您拥有API密钥。在灵犀万物官网申请API密钥,并明确使用场景(国内或国际)。
首先,将您的API密钥配置到环境变量中:
import os
os.environ["YI_API_KEY"] = "YOUR_API_KEY"然后,使用Langchain社区提供的包加载Yi LLM:
from langchain_community.llms import YiLLM
llm = YiLLM(model="yi-large")在与AI模型交互时,提示词起着至关重要的作用。它不仅决定模型的输出质量,还影响模型的响应速度和准确性。好的提示词应具备清晰性、简洁性和相关性。
代码块在AI模型的集成和应用中起着关键作用。以下是一些常见的代码块示例:
res = llm.invoke("What's your name?")
print(res)通过流式处理方法可以提高效率:
for chunk in llm.stream("Describe the key features of the Yi language model series."):
print(chunk, end="", flush=True)异步流式处理也可行:
import asyncio
async def run_aio_stream():
async for chunk in llm.astream(
"Write a brief on the future of AI according to Dr. Kai-Fu Lee's vision."
):
print(chunk, end="", flush=True)
asyncio.run(run_aio_stream())问:Yi-Large模型适合什么样的应用场景?
问:如何提高Yi-Large模型的输出质量?
问:Yi-Spark模型的主要优势是什么?
问:Yi-Vision模型在处理视觉语言任务时表现如何?
问:如何申请Yi LLM的API密钥?
通过本文的详细分析和介绍,希望您能更好地理解零一万物公司的AI模型系列,并有效地应用Yi-Large模型的常用提示词和技巧来提升工作效率和质量。






