

API是什么?深入解析API及其应用

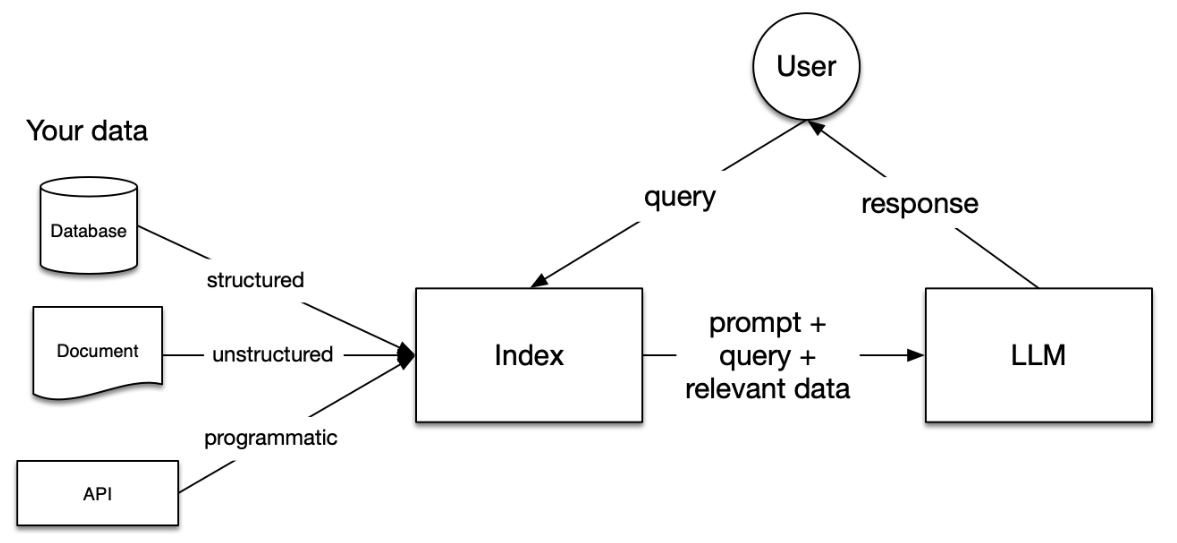
LlamaIndex,也被称为GPT Index,是一个为大语言模型(LLM)设计的数据框架,于2023年1月29日正式发布。LlamaIndex的出现为LLM应用程序提供了一个强大的平台,通过连接到不同的数据源,帮助用户摄取、构建和访问私有或特定领域的数据。LlamaIndex在Python和Typescript中均可使用,为用户提供了一种自然语言与数据交互的方式。虽然LLM已经在大量公开数据上进行了预训练,但LlamaIndex通过将用户的私有数据与现有的LLM相结合,实现了数据的增强处理和索引管理。
LlamaIndex为用户提供了多个关键工具:
通过这些工具,LlamaIndex不仅简化了数据处理流程,还提升了LLM的适用性和效率。
LlamaIndex的核心在于通过索引和搜索的方式实现数据的高效查询和处理。首先,它为外部数据库建立索引,然后在用户提问时从这些数据库中搜索相关信息,最后利用AI的语义理解能力生成答案。在索引和搜索阶段,可以使用OpenAI的嵌入接口,也可以选择其他大语言模型的嵌入方法。LlamaIndex的独特之处在于,它不仅限于文本索引,还支持将图片转换为文本进行索引,实现多模态功能。
安装LlamaIndex非常简单,只需使用Pip命令即可完成安装:
pip install llama-index
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple llama-index
pip install -i https://mirrors.aliyun.com/pypi/simple llama-index llama-index-core
pip install -i https://mirrors.aliyun.com/pypi/simple -qU llama-index llama-index-core这些命令可以帮助用户在不同的Python环境下快速安装LlamaIndex及其核心组件。
在Python中使用LlamaIndex有两种主要方式:
LlamaIndex提供了丰富的集成选项,用户可以根据应用需求选择合适的插件和集成包。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)上述代码展示了如何使用OpenAI的API密钥构建一个简单的向量存储索引,便于后续的数据查询和处理。
import os
os.environ["REPLICATE_API_TOKEN"] = "YOUR_REPLICATE_API_TOKEN"
from llama_index.core import Settings, VectorStoreIndex, SimpleDirectoryReader
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.replicate import Replicate
from transformers import AutoTokenizer
llama2_7b_chat = "meta/llama-2-7b-chat:8e6975e5ed6174911a6ff3d60540dfd4844201974602551e10e9e87ab143d81e"
Settings.llm = Replicate(
model=llama2_7b_chat,
temperature=0.01,
additional_kwargs={"top_p": 1, "max_new_tokens": 300},
)
Settings.tokenizer = AutoTokenizer.from_pretrained(
"NousResearch/Llama-2-7b-chat-hf"
)
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(
documents,
)
query_engine = index.as_query_engine()
query_engine.query("YOUR_QUESTION")
index.storage_context.persist()以上代码演示了如何使用托管在Replicate上的Llama 2构建索引。
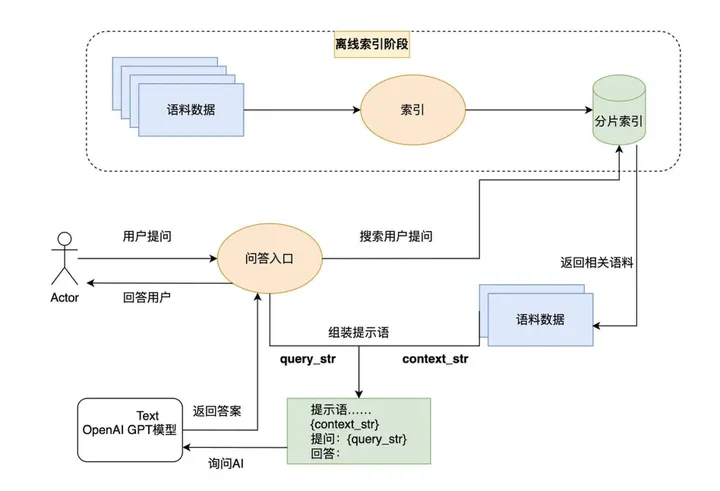
第一步,下载数据:从指定网址下载Paul Graham的文本,并将其保存到数据文件夹中。
第二步,设置您的OpenAI API密钥:将API密钥设置为环境变量,以便代码访问。
第三步,加载数据并构建索引:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()
response = query_engine.query("作者在成长过程中做了什么?")
print(response)import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))index.storage_context.persist()LlamaIndex不仅适用于简单的查询,还支持复杂的本地索引构建和查询,通过与ChatGPT接口结合,用户可以设计出功能强大的RAG系统,实现对本地文档的高效索引和查询。
问:LlamaIndex是什么?
问:如何安装LlamaIndex?
pip install llama-index。问:LlamaIndex的核心功能是什么?
问:LlamaIndex支持哪些编程语言?
问:LlamaIndex与OpenAI接口如何结合使用?






