

JSON 文件在线打开指南

HDF5(Hierarchical Data Format version 5)是一种用于存储和处理大容量科学数据的文件格式和相应的库文件。它最早由美国国家超级计算应用中心(NCSA)开发,目前在非营利组织 HDF 小组的维护下继续发展。该格式以其灵活性、通用性和高效的 I/O 性能著称,能够支持几乎无限量(高达 EB)的单文件存储。本文将详细介绍 HDF5 的特性、结构、使用方法及其在科学计算中的广泛应用。
HDF5 具有多种优异特性,使其成为存储和处理科学数据的理想选择。首先,它具有跨平台的通用性,能够在多种操作系统和硬件环境下使用。其次,HDF5 支持多种数据类型,包括整数、浮点数、字符串等,使其能够处理多样化的数据。此外,HDF5 提供了高效的数据压缩和扩展能力,允许用户根据需求调整数据存储的模式。最后,HDF5 的高效 I/O 性能使其特别适合处理大规模的数据集。
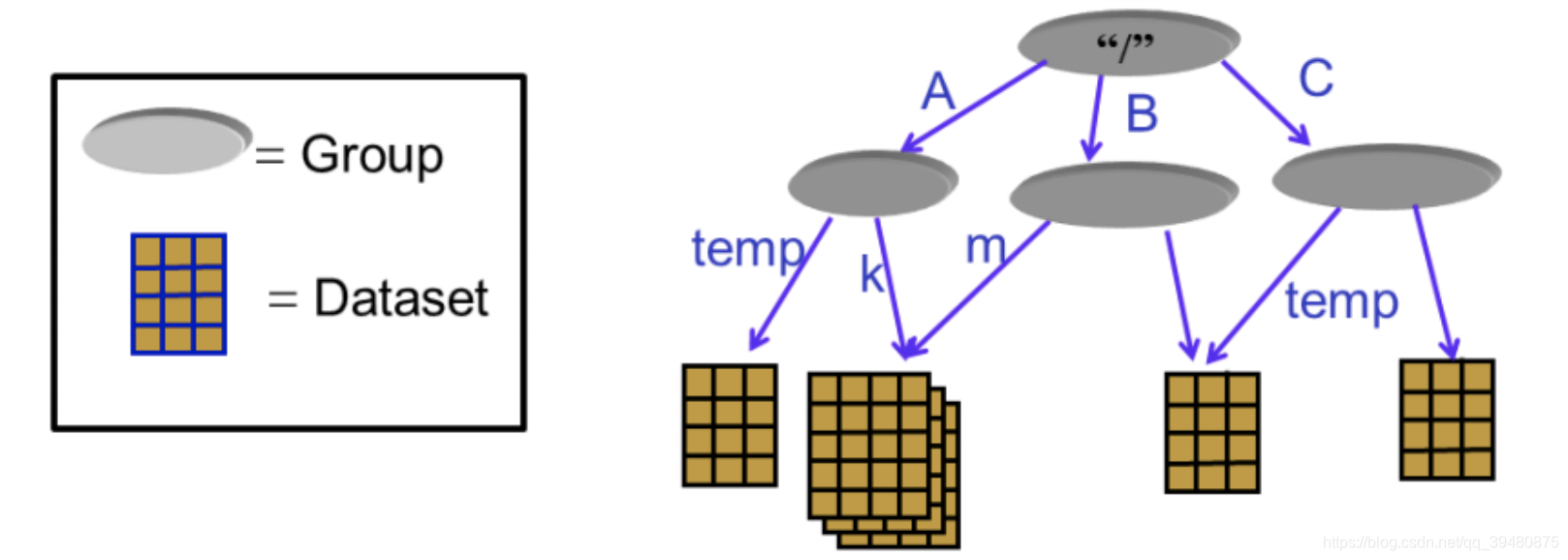
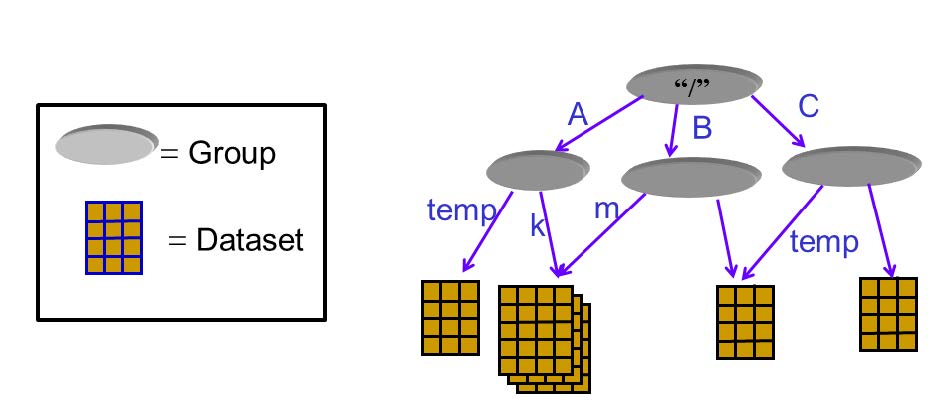
HDF5 的数据模型由两种主要对象类型组成:数据集(dataset)和组(group)。数据集是同一类型数据的多维数组,而组是一种容器结构,可以包含数据集和其他组。HDF5 的数据模型灵活而强大,允许用户根据需要自由地组织和管理数据。
HDF5 文件的操作可以通过多种编程语言实现,包括 C、C++、Fortran、Python 和 Java 等。下面以 Python 为例,介绍如何创建和操作 HDF5 文件。
import h5py
import numpy as np
f = h5py.File('myh5py.hdf5', 'w')
data = np.arange(20)
d1 = f.create_dataset('dset1', data=data)
group = f.create_group('my_group')
f.close()在上面的代码示例中,我们使用 h5py 库创建了一个名为 myh5py.hdf5 的 HDF5 文件,并在其中创建了一个数据集和一个组。创建数据集时,可以通过 data 参数直接赋值数据。
HDF5 支持多种数据集操作方法,允许用户对数据进行高效的存储和读取。以下是一些常用的操作:
在创建数据集时,可以选择直接通过现有的 NumPy 数组赋值,或者先定义数据集的形状和类型,之后再进行数据赋值。
arr = np.arange(100)
dataset = f.create_dataset('my_dataset', data=arr)
dataset = f.create_dataset('my_dataset', (100,), dtype='i8')
dataset[...] = np.arange(100)可以通过索引或切片语法读取 HDF5 数据集中的数据,这种方式与 NumPy 的数据操作非常相似。
data = dataset[:]
subset = dataset[10:20]删除数据集时,只是删除了数据集的链接,文件中申请的空间无法收回。
del f['my_dataset']在 Windows 系统上安装和配置 HDF5 需要进行一些步骤。以下是以 Windows 10 和 Visual Studio 2015 为例的安装指导。
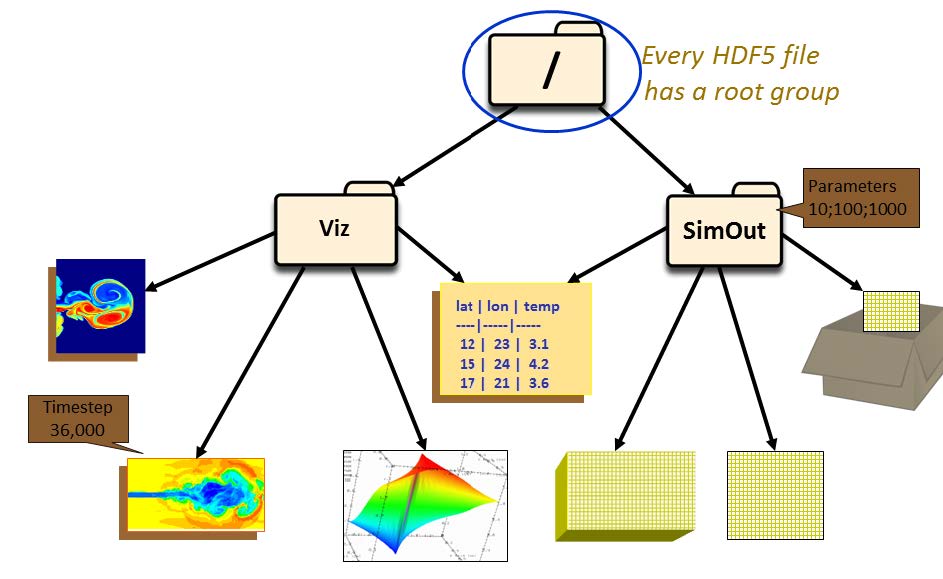
HDF5 文件通常以 .h5 或 .hdf5 为后缀名,其结构由根目录(root group)和多个子目录(group)构成。每个 group 可以包含多个数据集和其他 group。
HDF5 支持多种内置数据类型,包括整数、浮点数、字符串等。这些内置类型允许用户灵活定义数据的存储格式。
| C类型 | HDF5内存类型 | HDF5文件类型 |
|---|---|---|
| int | H5T_NATIVE_INT | H5T_STD_I32BE 或 LE |
| float | H5T_NATIVE_FLOAT | H5T_IEEE_F32BE 或 LE |
| double | H5T_NATIVE_DOUBLE | H5T_IEEE_F64BE 或 LE |
HDF5 在多个领域得到了广泛应用,包括科学研究、工程计算、数据分析等。以下是一些典型的应用场景:
HDF5 能够高效存储和处理大规模科学数据,因此被广泛应用于地球科学、天文学、气象学等领域。例如,NASA 的地球观测系统就采用 HDF5 作为标准数据格式。
在工程计算中,HDF5 的高效 I/O 性能和灵活的数据模型使其成为处理复杂数据的理想工具。工程师可以使用 HDF5 存储和分析大规模模拟数据。
HDF5 提供了强大的数据管理功能,适合用于大数据技术和 NoSQL 技术的应用。在金融、市场分析等领域,HDF5 可以帮助数据分析师高效地管理和分析数据。
以下是一个 Python 示例,展示如何使用 h5py 库创建和操作 HDF5 文件。
import h5py
import numpy as np
f = h5py.File('example.h5', 'w')
data = np.arange(100).reshape((10, 10))
dset = f.create_dataset('data', data=data)
dset.attrs['description'] = 'This is a 10x10 dataset'
print(dset[:])
f.close()pip install h5py。





