

Google语音识别技术详解与实践应用

Elasticsearch是一种基于Lucene的开源分布式搜索引擎,广泛应用于全文检索、日志分析、系统监控等领域。它以高性能、分布式存储和强大的搜索能力著称,支持多种数据类型并具备实时索引和分析功能。通过与Logstash和Kibana的组合(即ELK Stack),它提供了数据采集、存储、分析和可视化的一体化解决方案。
Elasticsearch 是一个开源的分布式搜索引擎,由 Elastic 公司开发。它能够实时地存储、搜索和分析大规模数据,并且可以水平扩展。

Elasticsearch 使用 RESTful API 进行交互,支持多种数据类型,包括结构化和非结构化数据。
Elasticsearch 的核心架构包括节点、集群、索引、文档和分片。每个集群由一个或多个节点组成,节点是运行着 Elasticsearch 实例的服务器。
# 示例代码:Elasticsearch节点配置
node.name: node-1
cluster.name: my-clusterElasticsearch 常用于日志分析、全文检索、数据分析和应用监控等场景。它支持复杂查询,并提供快速搜索能力,是现代数据应用的核心组件之一。
全文检索是一种可以在大量文本数据中快速查找信息的技术。它通过对文本进行分词和索引,使得搜索操作更加高效。
倒排索引是全文检索的基础。它将文档中的词条映射到包含该词条的文档列表,从而实现快速查询。
在 Elasticsearch 中,倒排索引的实现通过分词器分析字符串,将文档中的内容分解为词条,并建立索引。
# 示例代码:创建倒排索引
PUT /my_index
{
"mappings": {
"properties": {
"content": {
"type": "text"
}
}
}
}Elasticsearch 是面向文档的数据库系统,而传统数据库如 MySQL 是关系型数据库,采用表格形式存储数据。
Elasticsearch 使用 JSON 格式进行查询,而传统数据库使用 SQL 语句查询。前者更具灵活性,适用于复杂的搜索需求。
Elasticsearch 具有良好的水平扩展能力,可以通过增加节点来提升性能,而传统数据库需要通过垂直扩展,增加服务器资源。
Elasticsearch 是 ELK 栈的核心组件,负责数据的存储、索引和搜索。它与 Logstash 和 Kibana 紧密配合,共同提供数据处理和可视化功能。
Logstash 是一个数据收集引擎,支持从多种来源收集数据,并进行转换后存储到 Elasticsearch 中。
Kibana 是一个用于数据可视化的工具,提供了对 Elasticsearch 数据的图形化展示和查询功能。
Elasticsearch 可以在多个平台上运行,包括 Windows、Linux 和 macOS。用户可以从官网下载安装包进行安装。
# 示例代码:安装Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.2-linux-x86_64.tar.gz
tar -xzf elasticsearch-7.10.2-linux-x86_64.tar.gz安装后,需要对 Elasticsearch 进行基本配置,如设置集群名称、节点名称和网络绑定地址。
配置完成后,可以通过命令行启动 Elasticsearch 服务,并通过浏览器访问其 RESTful 接口。
创建索引是存储数据的第一步。通过 Elasticsearch 的 RESTful API,可以方便地创建和管理索引。
# 示例代码:创建索引
PUT /my_index
{
"mappings": {
"properties": {
"name": {
"type": "text"
}
}
}
}Elasticsearch 提供丰富的查询功能,支持多种查询条件和排序方式,满足不同的搜索需求。
通过 API 可以对索引中的文档进行更新和删除,保持数据的实时性和正确性。
Elasticsearch 支持分布式集群架构,能够将数据分布到多个节点上,提高数据的存储能力和查询性能。
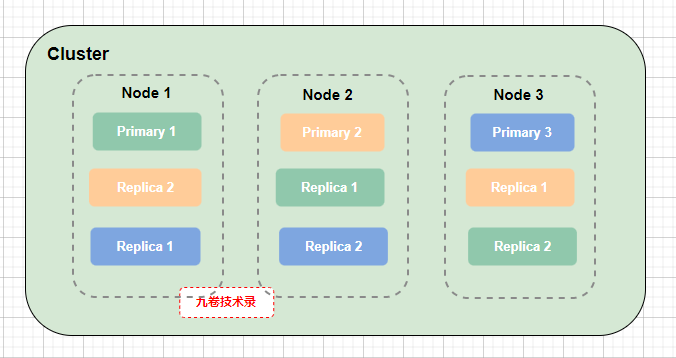
每个索引可以分为多个分片,以便数据可以在集群中分布存储,并支持并行查询。
副本是分片的冗余副本,用于提高数据的可用性和容错能力。即使主分片损坏,副本也能保证数据的完整性。
通过以上介绍,相信您对 Elasticsearch 是什么有了更深入的了解。






