

LLM的预训练任务有哪些


BERT,全称为Bidirectional Encoder Representations from Transformers,是由Google开发的一种预训练语言模型。作为自然语言处理(NLP)领域的革命性框架,BERT刷新了多个任务的记录,为NLP研究和应用带来了巨大的影响。尽管BERT在算法上并非完全创新,但它将前人的优点集于一身,通过适当的改进,形成了如今无与伦比的强大能力。
BERT的设计核心在于其双向编码能力,这种能力使模型能够从两个方向理解上下文,从而在处理多义词、语境理解等方面表现出色。其预训练过程涉及大规模无监督数据集,如Wikipedia和书籍语料库,这种预训练使得BERT在各种下游任务中能够快速适应和微调。
预训练思想的集成:BERT借鉴了计算机视觉领域的预训练思想,在语言模型中首次引入双向编码。
双向编码的实现:BERT采用了完形填空任务的思想,即Masked Language Model(MLM),结合了Word2Vec的CBOW思想,由此增强了模型对上下文的理解能力。
特征提取的变革:不同于传统的RNN模型,BERT使用Transformer作为特征提取器,充分发挥了注意力机制的作用。
模型结构的优化:在CBOW思想之上增加了语言掩码模型(MLM),并通过减少训练和推理阶段的不匹配,避免过拟合。
句子间语义关系的捕捉:BERT通过下句预测(Next Sentence Prediction,NSP)来学习句子间的语义联系,这也是BERT的重要创新之一。

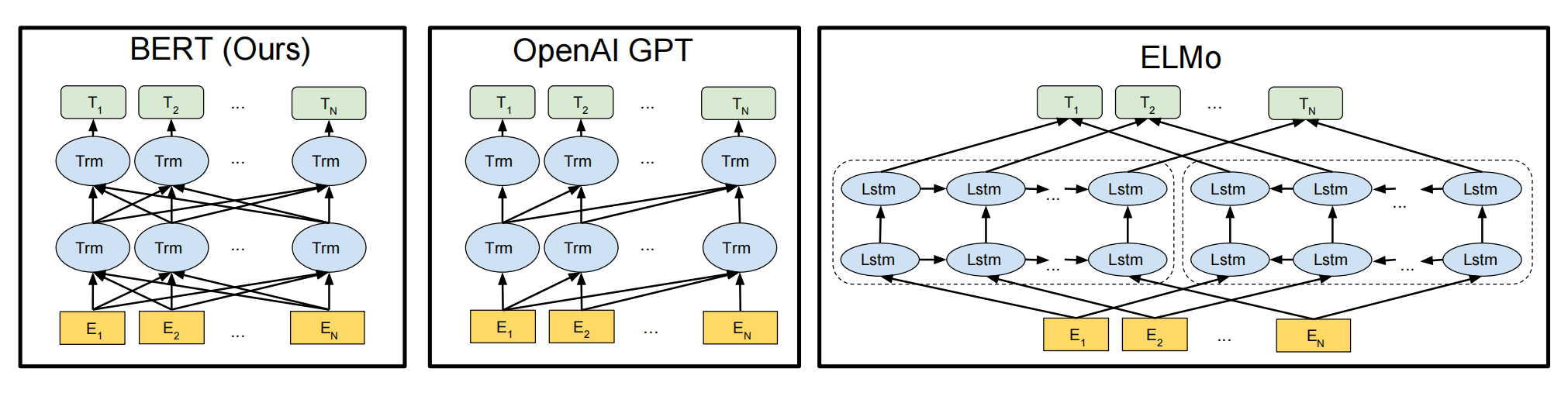
在语言模型领域,BERT与ELMo和GPT有显著的区别和优势。ELMo采用自左向右和自右向左的双向LSTM网络进行编码,虽然实现了双向编码,但本质上仍是两个单向编码的结合。GPT则使用Transformer Decoder进行单向编码,适用于生成任务。
BERT的优势主要体现在以下方面:
双向编码:BERT通过Transformer Encoder实现了真正的双向编码,增强了语义理解能力。
广泛的适用性:BERT作为预训练模型,泛化能力强,不需要大量语料训练即可应用于特定场景。
简单的端到端模型:无需调整网络结构,只需在最后添加适用于不同任务的输出层。
快速并行和性能提升:基于Transformer的架构,BERT可以快速并行处理,同时提高模型的准确率。
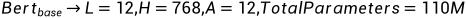
BERT有两种主要版本:BERT Base和BERT Large。BERT Base由12层Transformer组成,拥有12个注意力头和1.1亿个参数。BERT Large则拥有24层Transformer、16个注意力头和3.4亿个参数。尽管参数量巨大,但BERT可以通过并行计算和深度学习技术有效处理。
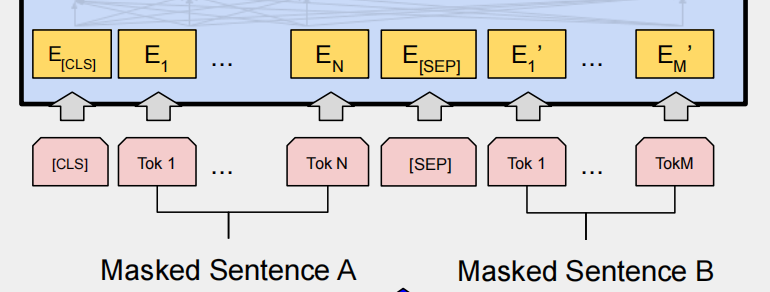
BERT的输入是每个token的表征,使用WordPiece算法构建的词典。输入序列的开头插入特定的分类token [CLS],用于聚集序列信息,句子间用[SEP]分隔。每个token的表征由token、segment和position三个embeddings相加组成。
Token Embeddings:每个词转换为固定维度向量,BERT中为768维。
Segment Embeddings:区分token所属的句子。
Position Embeddings:编码序列顺序信息,帮助BERT理解语序。
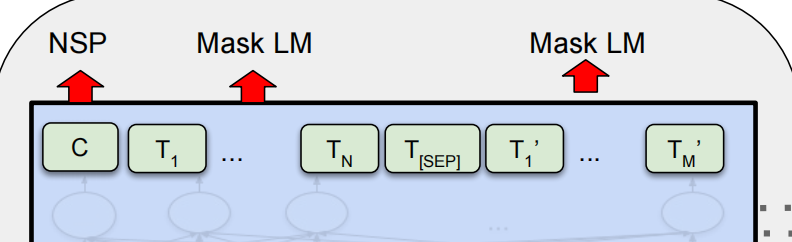
BERT的输出是句子中每个token的768维向量,首位置的[CLS]用于句子级任务,其它token用于token级任务。通过这种设计,BERT能够适应不同的下游任务。
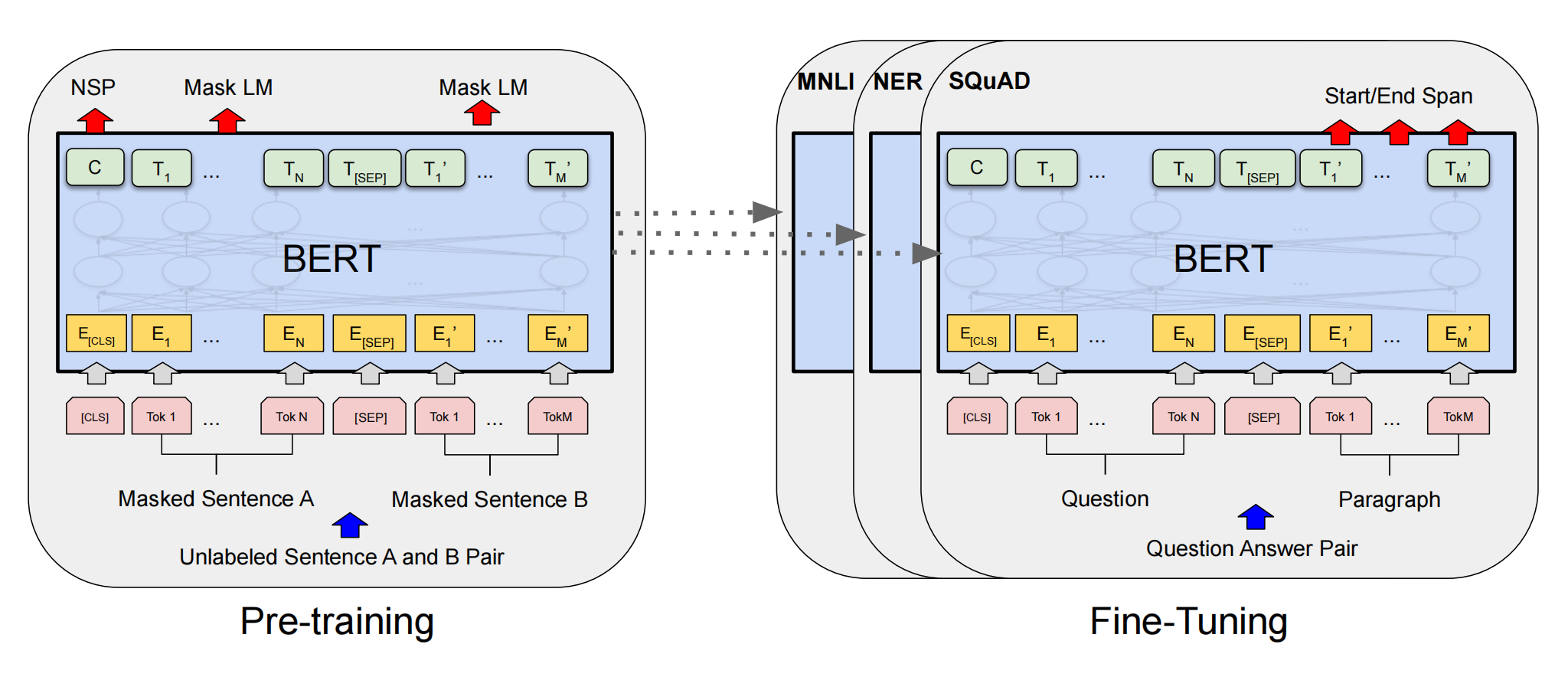
BERT的预训练包含两个任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
MLM通过随机掩盖句子中15%的词,训练模型根据上下文预测被掩盖的词。这一过程提升了模型对上下文的理解。
NSP用于训练模型理解句子间关系,50%的样本中句子B紧接句子A,另50%为随机句子。这一任务增强了模型的句子级别理解能力。
BERT的出现标志着NLP领域的一次重大跨越,不仅提升了模型的性能,还为后续研究提供了新的思路和方向。







