

使用 Flask App Builder 进行 API 查询的完整指南

预训练是指通过自监督学习从大规模数据中获得与具体任务无关的预训练模型的过程,最终产出为预训练模型(Pretrained Model)。在自然语言处理(NLP)领域,预训练模型的应用非常广泛,常见的模型类型包括编码器模型、自编码模型、解码器模型、自回归模型等。这些模型被广泛用于文本分类、命名实体识别、文本生成、机器翻译等任务。
在预训练模型中,最常用的包括编码器模型、自编码模型、解码器模型和编码器解码器模型。编码器模型,如ALBERT、BERT、DistilBERT、RoBERTa,通常用于文本分类、命名实体识别和阅读理解。解码器模型,如GPT、GPT-2、Bloom、LLaMA,主要用于文本生成。编码器解码器模型,如BART、T5、Marian、mBART,则被广泛用于文本摘要和机器翻译。

预训练任务主要分为三大类:掩码语言模型、自编码模型,因果语言模型、自回归模型,和序列到序列模型、前缀语言模型。
掩码语言模型是一种自编码模型,其主要任务是将输入文本中的一些token替换为特殊的[MASK]字符,并预测这些被替换的字符。模型只计算掩码部分的loss,其余部分不计算loss。这种模型有助于模型理解上下文,从而提高对未见过词汇的预测能力。
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForMaskedLM.from_pretrained('bert-base-uncased')
input_text = "Hello, my name is [MASK]"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model(input_ids)
因果语言模型,也称为自回归模型,接收完整的序列输入,并基于上文的token预测当前的token。在这种模型中,输入序列的结束位置通常有一个特殊token,称为eos_token。这种模型的代表是GPT系列模型。
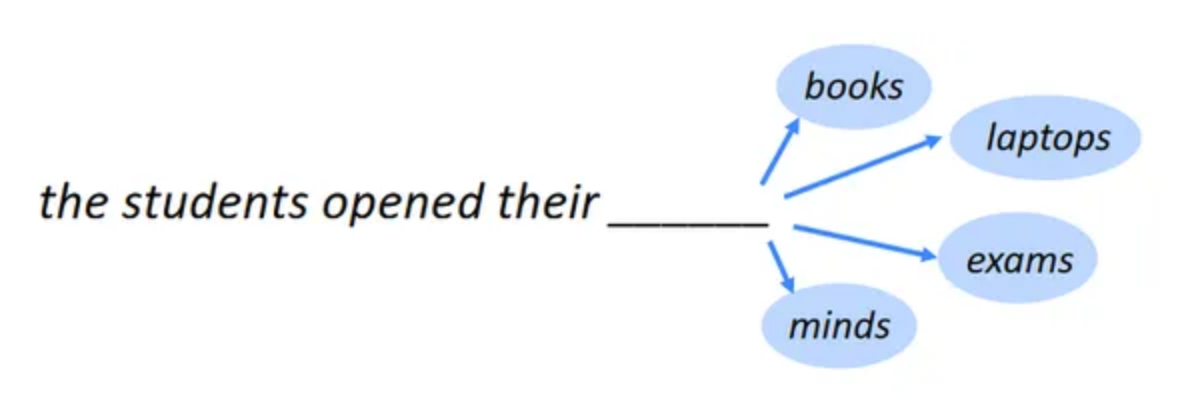
序列到序列模型,又称为前缀语言模型,采用编码器解码器的方式实现。任务较为多样化,通常用于文本摘要和机器翻译。这种模型的核心是通过解码器对输入进行转换,并计算解码器部分的loss。
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5ForConditionalGeneration.from_pretrained('t5-small')
input_text = "translate English to French: How are you?"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
outputs = model.generate(input_ids)
在实际应用中,预训练模型的实现需要进行数据集的准备、模型的加载以及训练参数的设置。以下是一个掩码语言模型的完整代码示例。
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForMaskedLM, Trainer, TrainingArguments
dataset = load_dataset('wikitext', 'wikitext-2-raw-v1', split='train')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForMaskedLM.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my name is [MASK]", return_tensors='pt')
outputs = model(**inputs)
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=16,
save_steps=10,
save_total_limit=2,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()预训练模型需要大量的数据来进行训练。数据集的规模和质量直接影响模型的效果。在选择数据集时,需要考虑数据的多样性和覆盖面。此外,数据的清洗和预处理也是非常重要的步骤,以确保数据的质量。
预训练模型的训练通常需要大量的计算资源,尤其是在大规模数据集上训练时。模型的参数量和计算复杂度也对资源的需求产生影响。因此,选择合适的硬件设备和优化计算资源的使用是非常关键的。
预训练模型的优化和调参是提高模型性能的关键环节。常见的优化策略包括学习率的调整、梯度剪裁、正则化等。此外,模型的参数初始化和训练策略也需要根据具体任务进行调整。
在文本分类任务中,预训练模型可以通过微调来适应特定的分类任务。常见的文本分类任务包括情感分析、主题分类、垃圾邮件检测等。通过微调,预训练模型能够更准确地捕捉文本的特征,从而提高分类的准确性。
命名实体识别是自然语言处理中一项重要的任务,旨在识别文本中的实体,如人名、地名、组织名等。预训练模型可以通过微调来提高实体识别的准确性和召回率。
在文本生成任务中,如对话系统、故事生成等,预训练模型通过自回归的方式生成连贯的文本。模型通过学习大量的文本数据,能够生成自然流畅的文本内容。
预训练模型在自然语言处理领域的应用广泛且效果显著。通过不同类型的预训练任务,模型能够捕捉文本的深层次特征,并在多种任务中表现出色。然而,预训练模型的训练需要大量的数据和计算资源,因此在实际应用中需要根据具体情况进行权衡和选择。未来,随着技术的进步和资源的优化,预训练模型有望在更多领域取得突破。
问:预训练模型的优点是什么?
问:预训练模型的缺点有哪些?
问:如何选择合适的预训练模型?
问:预训练模型如何进行微调?
问:预训练模型在实际应用中有哪些挑战?







