

如何调用 Minimax 的 API

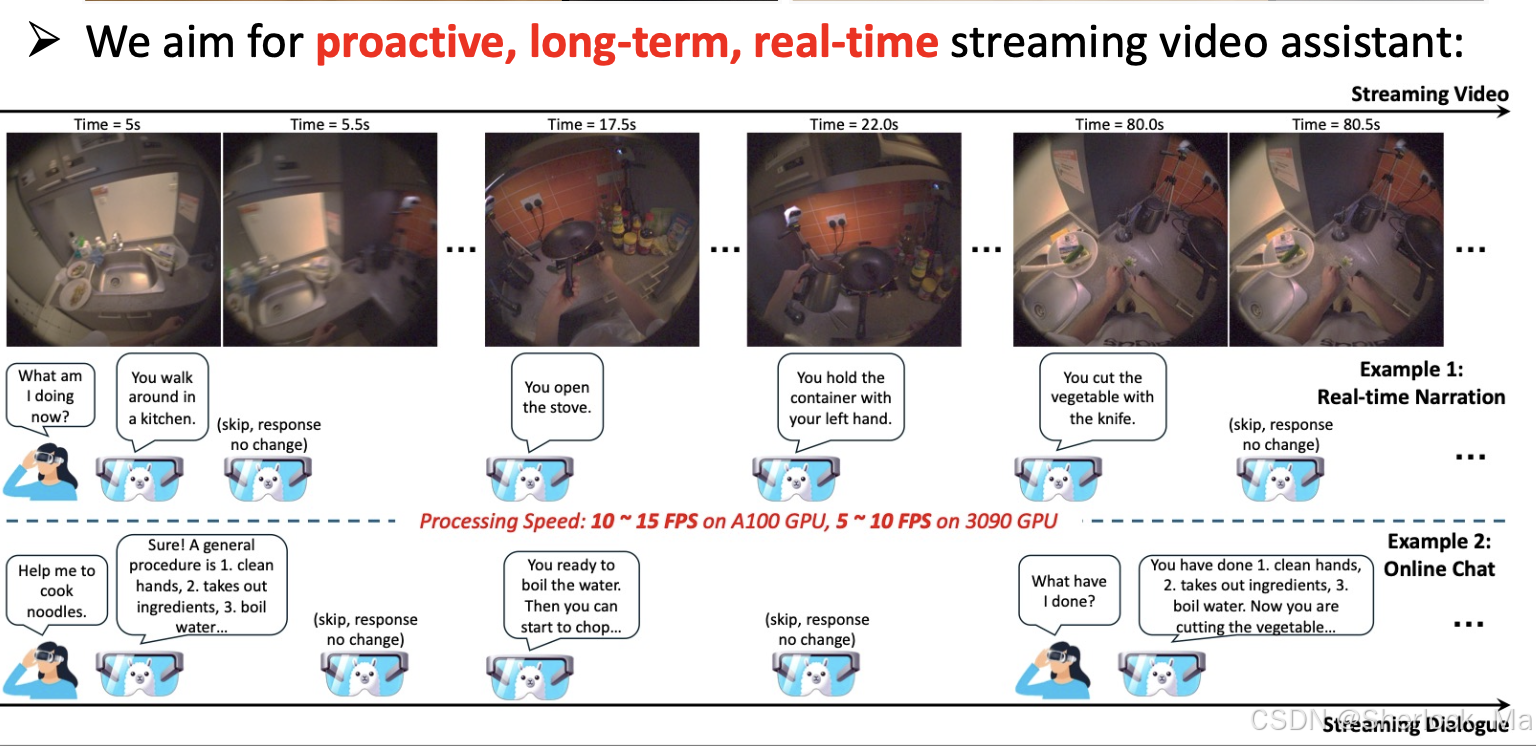
VideoLDM 是一种专为流媒体视频实时对话设计的创新模型。其主要功能是通过实时生成视频内容的叙述,识别视频中的人物活动,并回答与视频内容相关的问题。该模型不仅能够在流媒体视频中展现出色的性能,还可以作为智能助手与用户进行互动,提供即时反馈。例如,在A100 GPU上处理Ego4D的5分钟视频片段时,VideoLDM 能够以超过10 FPS的速度运行,并在离线视频基准测试中表现优异。这使得VideoLDM 成为构建上下文相关AI助手的重要步骤。
VideoLDM 的源码结构复杂且严谨,主要分为视频处理、数据输入输出、模型训练与推理等模块。源码详细记录了如何将视频流数据转化为模型可理解的输入,并通过精确的时间戳同步实现实时响应。以下是部分代码示例,展示了视频流的处理过程:
liveinfer = LiveInfer()
liveinfer.load_video('path_to_video')
frame_data = liveinfer.input_video_stream(current_time)从源码中可以看出,VideoLDM 在数据处理方面具有高效的机制,能够快速解析视频帧并生成相应的文本描述。
VideoLDM 在数据处理上采用了先进的技术,能够有效地将视频数据转化为模型输入。其关键在于对视频帧的高效编码和时序信息的精确管理。模型通过CLIP ViT-L 编码器提取视频帧的特征嵌入,并将其与语言模型的输入相结合,实现多模态信息的融合。
在输入输出机制上,VideoLDM 采用了以下策略:
ffmpeg_once(src_video_path, dst_video_path, fps=2, resolution=720)
frame_embeds = model.visual_embed(video_tensor)VideoLDM 的架构设计紧凑,主要包括图像编码器、MLP 和语言模型三大组件。每个组件在模型的整体运作中扮演着至关重要的角色。
图像编码器负责从视频中提取视觉特征。VideoLDM 使用CLIP ViT-L 编码器,这是一个经过大规模数据预训练的模型,能够高效地从视频帧中提取丰富的视觉信息。
MLP 投影仪将提取的帧嵌入转换为帧令牌,这些令牌与语言模型的输入相结合,形成多模态信息的输入序列。
语言模型使用的是Llama-2-7B-Chat,并结合LoRA进行调优,以提高模型的生成能力和效率。语言模型负责将多模态输入转化为自然语言输出,生成对视频内容的描述和回答。
VideoLDM 的训练过程复杂而精细,涉及多种优化策略来提升模型的性能。其训练方法主要包括以下几个方面:
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
for batch in dataloader:
optimizer.zero_grad()
outputs = model(batch['inputs'])
loss = loss_fn(outputs, batch['targets'])
loss.backward()
optimizer.step()在推理过程中,VideoLDM 通过优化的KV Cache和并行处理技术实现了高效的实时响应。模型能够根据视频帧的输入,动态生成与上下文相关的描述和回答。
为了提高推理精度,VideoLDM 在预测EOS(对话结束)时引入了阈值校正机制,确保模型仅在必要时终止对话。
KV Cache 是一种缓存机制,能够有效地存储和重用过去的计算结果,从而加速后续的推理过程。
outputs = model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=past_key_values)VideoLDM 在多项基准测试中表现出色,其在速度、准确性和内存效率方面均优于现有模型。具体评估结果显示,VideoLDM 在处理复杂视频场景时,能够保持稳定的性能,并提供高质量的实时描述。
答:VideoLDM 通过结合图像编码器、MLP 和语言模型,实时处理视频帧并生成描述。
答:可以通过调整学习率、优化模型参数以及使用更高效的数据处理机制来提升性能。
答:VideoLDM 适用于流媒体视频分析、智能监控和实时互动等场景。
答:可以通过优化KV Cache 和并行处理技术来减少推理延迟。
答:VideoLDM 的源码可在GitHub上获取,具体地址为 VideoLDM 源码。






