

如何调用 Minimax 的 API

VideoLDM(Latent Diffusion Model)被认为是视频生成领域的革命性技术。通过在图像生成模型中引入时间维度,它能够生成高质量的长视频。其核心思想是利用潜在空间中的扩散模型,在保持计算成本低的同时生成连续且高分辨率的视频片段。通过微调图像生成模型以适应视频生成的需求,VideoLDM 展示了其在多种应用场景中的潜力。
VideoLDM 的应用不仅限于娱乐和创意领域,还包括自主驾驶和监控等需要高分辨率视频数据处理的行业。其生成高分辨率视频的能力,使其在模拟真实世界场景中尤为出色。
VideoLDM 是在图像生成领域的基础上发展而来的,其架构设计包括几个关键步骤。首先,通过预训练的潜在空间扩散模型(LDM)生成图像,然后通过引入时间层将其扩展为视频生成模型。第二步是将图像生成器转换为视频生成器,这需要在潜在空间中进行时间对齐,并通过微调实现长时间视频的生成。
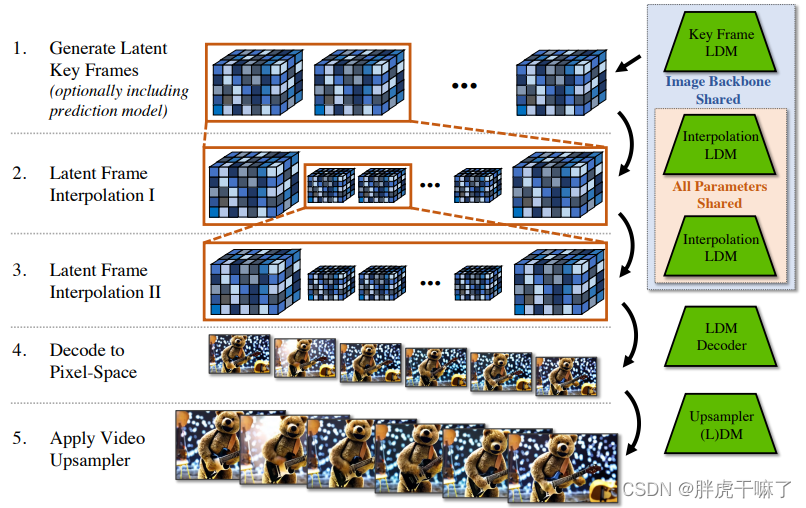
视频生成的过程分为如下几个步骤:
在 LDM 中,时间层的引入是实现图像生成器向视频生成器转变的关键。这一过程涉及在原有的空间层中加入时间层,以 3D 卷积和时间注意力层的形式实现。在此过程中,空间层的参数保持不变,而时间层的参数则通过视频数据进行微调。
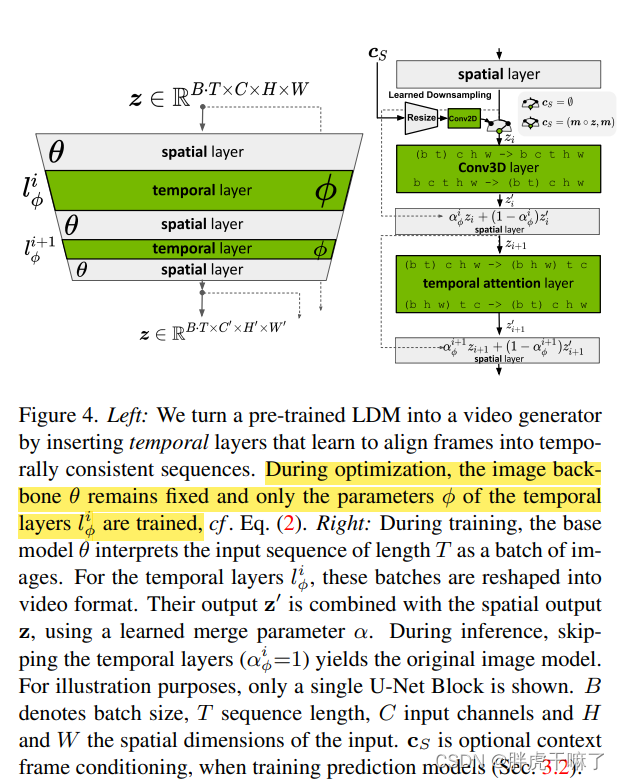
时间层的设计是为了对齐独立的图像帧,使得它们能够形成连续的视频序列。通过这种设计,VideoLDM 可以生成更多具有时间连贯性的帧序列,从而提高视频生成的质量。
直接将图像自编码器应用于视频生成会引发图像闪烁等问题。为了克服这一难题,VideoLDM 对自编码器进行了时序微调。通过对解码器进行微调,而保持编码器不变,模型能够更好地适应视频数据的时序特性。
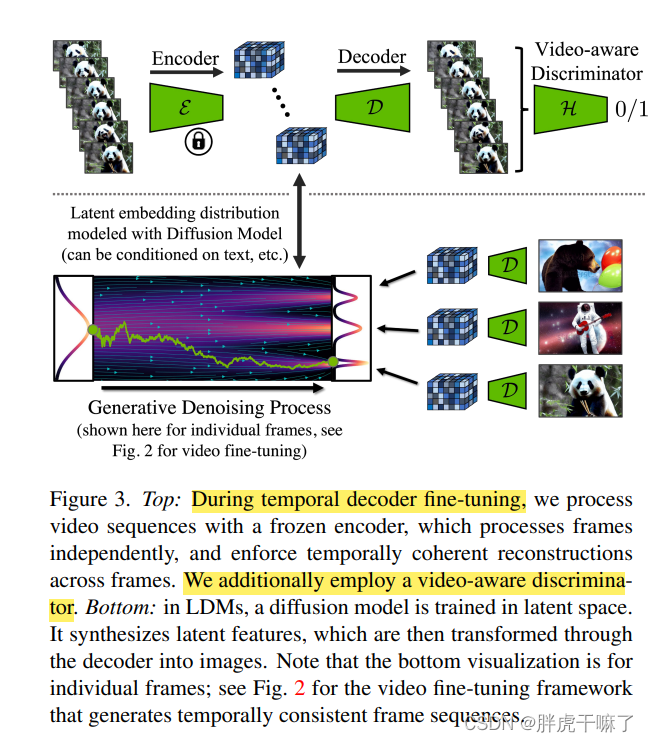
这种微调利用了 3D 卷积构建的时序判别器来确保帧与帧之间的连续性。微调通过调整解码器的参数,使其能够处理时序一致的潜向量,从而生成视觉上连贯的视频内容。
虽然 b 章节的方法适用于短视频生成,但对于长视频,VideoLDM 采用预测模型来扩展其生成长度。通过输入多个上下文帧进行训练,VideoLDM 能够预测未来的帧序列。此过程通过二进制掩码实现,掩盖住需要预测的帧,保留上下文帧。
推理阶段,利用生成的关键帧作为上下文帧,迭代地生成长视频。通过无分类器扩散引导,采样过程更加稳定。
为了增强视频的帧率和流畅性,VideoLDM 在关键帧之间采用时序插值策略。利用条件掩码机制,在关键帧之间生成插值帧。实验表明,单次插值可使视频长度增加数倍,经过多次迭代,可显著提升视频的帧率。
这种插值方法使得生成的视频在视觉上更加连贯,从而提升用户的观看体验。
为进一步提升视频清晰度,VideoLDM 在视频上采样过程中对超分辨率模型进行时序微调。通过将时间层拓展至上采样器,模型能够在提升分辨率的同时保持帧间一致性。
这种时序微调策略有效地结合了空间和时间信息,使得每一帧都能在高分辨率下保持一致的视觉效果。
通过本文的探讨,VideoLDM 显示了其在高分辨率视频生成中的强大能力。未来,随着技术的发展,VideoLDM 将在更多领域内展现其应用潜力,为视频生成带来更多创新。






