

如何调用 Minimax 的 API

论文地址:https://arxiv.org/pdf/2403.10517
VideoLDM Agent 是一个创新的基于代理的视频理解系统,采用大规模语言模型作为核心,以识别重要信息并用于回答问题和编辑视频。该系统通过在 EgoSchema 和 NExT-QA 基准上进行评估,展现了其高效的零镜头准确率,分别为 54.1% 和 71.3%。
处理长视频需要模型具备处理复杂信息和推理长序列的能力。现有的大规模语言模型虽然在处理长语境方面表现出色,但在视觉信息处理上略显不足。VideoLDM Agent 通过模仿人类的视频理解过程,强调推理能力而非单纯处理长视觉输入,成为长视频理解领域的重要突破。
传统视频处理方法主要包括选择性处理和压缩处理。选择性压缩方法通过对视频进行子采样来优化处理性能,而代理技术则利用大规模语言模型来进行决策和执行。这些技术的结合为视频理解过程提供了一种全新的视角,即将其视为一个决策过程。
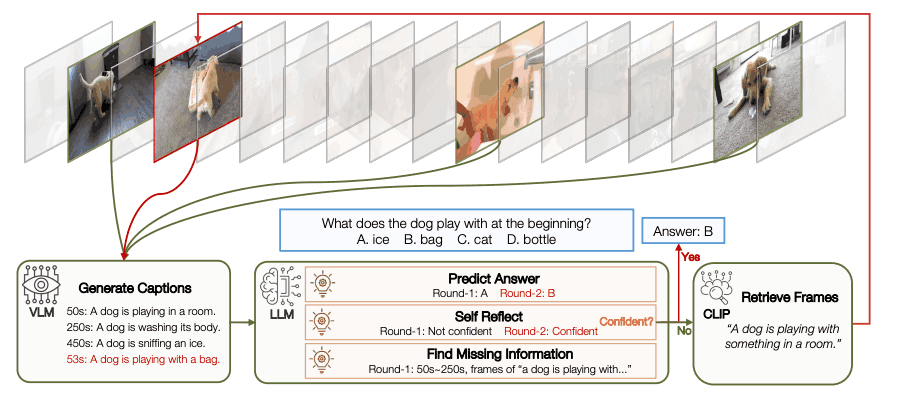
VideoLDM Agent 通过向大规模语言模型展示视频中的均匀采样帧,帮助其熟悉视频上下文。视觉语言模型用于将视觉信息转化为语言描述,初始状态记录了视频的内容和意义。
在当前状态下,大规模语言模型需要决定一个行动:回答问题或搜索新信息。这需要对问题和现有信息进行反思,并根据置信度选择最合适的行动。
当需要新信息时,系统会使用工具来检索必要的数据。通过在分段级别收集信息,增强时间推理功能,以更新当前状态的信息。
在收集新观察结果后,视觉语言模型将为每一帧生成标题,并请求大规模语言模型生成下一轮预测。与传统方法相比,这种方法通过适应性选择策略有效地降低了信息收集成本。
EgoSchema 数据集包含以自我为中心的视频,共 5000 个问题;而 NExT-QA 数据集则包含以物体互动为特色的自然视频,共 48000 个问题。这些数据集用于评估 VideoLDM Agent 的性能。
所有视频以 1 帧/秒的速度解码,并通过余弦相似度分析从视觉描述和帧特征中检索最相关的帧。在实验中,LaViLa 用于 EgoSchema,CogAgent 用于 NExT-QA,GPT-4 则作为大规模语言模型使用。
VideoLDM Agent 在 EgoSchema 和 NExT-QA 数据集上均取得了领先的结果,显著优于此前的方法。它在完整的 EgoSchema 数据集上实现了 54.1% 的准确率,在 500 个问题的子集上达到 60.2%。
VideoLDM Agent 的迭代帧选择是其关键组件之一。该过程通过动态检索和汇总信息,直到收集足以回答问题的数据。实验显示,该过程的灵活性和效率使其能够适应不同难度的问题。
在对大规模语言模型的消融研究中,GPT-4 表现优异,尤其在结构化预测方面。视觉语言模型中,CogAgent 和 LaViLa 表现相近,而 BLIP-2 较差。在对比语言图像模型(CLIP)的评估中,各版本的 CLIP 性能相当,且在检索任务中表现出色。
通过对 NExT-QA 实例的解析,展示了视频代理如何识别缺失信息、确定补充信息并使用 CLIP 检索细节。如下图所示,VideoLDM Agent 能够正确解析长达一小时的 YouTube 视频,并提供精准的帧来回答问题。

VideoLDM Agent 展示了其在长视频理解方面的卓越效果和效率。未来的工作将集中于改进和整合模型、扩展至实时应用、应用于多领域以及改进用户界面。这些改进将进一步扩大 VideoLDM Agent 的应用范围。

VideoLDM Agent 通过大规模语言模型和视觉语言模型的结合,提高了视频理解和处理的效率。它可以高效识别关键信息并做出准确的推理。
该系统主要应用于需要高效视频理解的场景,如视频编辑、自动字幕生成和复杂视频分析等领域。
相比传统方法,VideoLDM Agent 在信息检索和处理效率上具有明显优势,尤其在长视频的理解上表现卓越。
虽然目前主要用于离线分析,未来的改进将使 VideoLDM Agent 适应实时应用,使其在实时视频处理任务中表现更佳。
随着技术的不断进步和优化,VideoLDM Agent 的应用前景广阔,可能在更多领域中发挥作用,如智能监控和实时视频分析。





