梯度消失:神经网络中的隐患与解决方案
梯度消失:神经网络中的隐患与解决方案
在神经网络的训练过程中,梯度消失问题是一个常见的挑战,特别是在深层神经网络的结构中。梯度消失指的是在反向传播过程中,梯度逐渐减小,导致前几层的参数几乎不更新。这不仅阻碍了网络的学习能力,还可能导致模型的最终表现不佳。本文将深入探讨梯度消失的概念、产生原因及其解决方案。
1. 什么是梯度消失?
梯度消失是指在深度神经网络中,随着网络层数的增加,反向传播时计算的梯度逐渐趋近于零。由于梯度是用来调整权重以减少误差的,所以当梯度消失时,权重的更新变得微乎其微,导致网络无法有效学习。举个例子,当使用sigmoid激活函数时,梯度的值域在(0,1)之间,多个小于1的数相乘会导致梯度迅速减小。
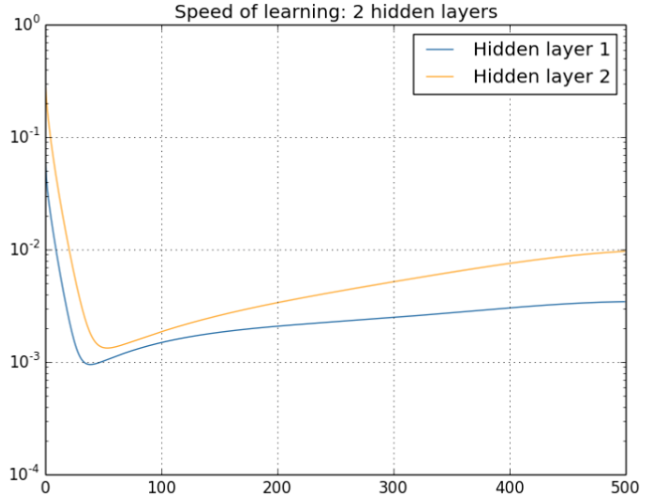
2. 梯度消失的产生原因
(1) 激活函数的选择
激活函数对梯度的大小有直接影响。sigmoid和tanh等激活函数在极端输入值时会趋向于0或1,其导数接近于0,这使得梯度在传播过程中迅速减小。ReLU等激活函数由于其在正数区域的导数为1,能够有效缓解梯度消失的问题。
(2) 网络层数过深
随着网络层数的增加,梯度在层与层之间的传递过程中不断被乘以小于1的数,导致梯度迅速衰减。尤其是在多层感知器和循环神经网络中,梯度消失问题尤为突出。
3. 梯度消失的影响
梯度消失导致神经网络在训练过程中,特别是前几层的权重更新非常缓慢,甚至不更新。这会使模型无法从训练数据中学习有效的特征,导致模型的预测能力下降,最终影响模型的整体表现。
4. 梯度消失的解决方案
(1) 使用更合适的激活函数
采用ReLU、Leaky ReLU、PReLU等激活函数,这些函数在正数区域的导数为1,有效避免了梯度的消失。ReLU的负区间为0,但可以通过使用Leaky ReLU等进行改进。
import torch
import torch.nn as nn
class CustomReLU(nn.Module):
def __init__(self):
super(CustomReLU, self).__init__() def forward(self, x):
return torch.max(0.1*x, x)(2) 批规范化(Batch Normalization)
通过在每一层的输出上进行批规范化,将输出调整到均值为0、方差为1的范围内,这有助于保持梯度的稳定性,避免梯度消失。
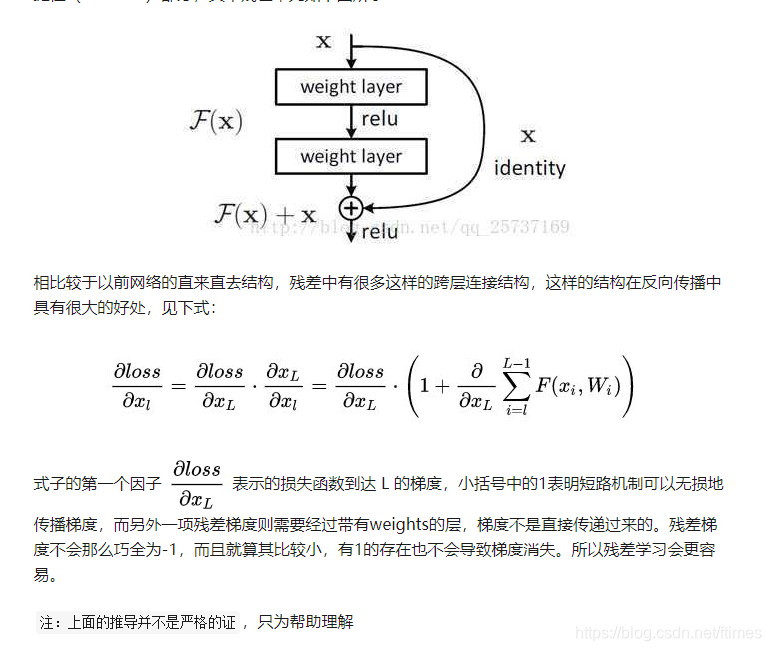
(3) 残差网络(Residual Networks)
通过引入残差连接,允许梯度流直接通过网络层,这样即使在非常深的网络中,梯度也能有效地传播到输入层。这是ResNet成功的关键之一。
(4) 使用LSTM等结构
LSTM是长短期记忆网络,具有特殊的门结构,可以有效“记住”长时间的梯度信息,避免梯度消失的问题。
5. 梯度爆炸:与梯度消失相对的问题
梯度爆炸是与梯度消失相反的问题,指的是梯度在反向传播过程中不断增大,导致权重更新过大,模型变得不稳定。解决梯度爆炸的方法包括权重剪切、调整学习率等。
6. 梯度消失与梯度爆炸的共同点
两者都与网络层数和激活函数的选择有关,通常在深度网络和不当的权重初始化下容易出现。解决这两个问题的关键在于选择合适的激活函数、使用批规范化以及设计合理的网络结构。
7. 结论
解决梯度消失和爆炸问题对于深度神经网络的稳定训练至关重要。通过选择合适的激活函数、使用批规范化和残差网络等方法,可以有效地缓解这些问题,提高网络的训练效率和性能。
FAQ
-
为什么梯度消失在深层网络中更常见?
- 因为深层网络中的梯度在传播过程中会被多次缩小,尤其是在多层感知器中,激活函数的选择会进一步加剧这一问题。
-
批规范化如何帮助解决梯度消失问题?
- 批规范化通过将每一层的输出调整到均值为0、方差为1的范围内,保持了梯度的稳定性,避免了梯度消失。
-
LSTM如何避免梯度消失?
- LSTM通过其独特的门机制,可以在长时间内保留梯度信息,从而避免梯度消失。
-
使用ReLU激活函数就能完全避免梯度消失吗?
- ReLU在大部分情况下可以缓解梯度消失,但在负区间仍然存在0梯度问题,可以使用Leaky ReLU等进行改进。
-
如何选择适合的激活函数?
- 选择激活函数时应考虑网络的深度、数据的特性以及梯度稳定性,通常ReLU及其变体是较好的选择。