

如何使用 DeepSeek 构建 AI Agent:终极指南

ControlNet 1.1是什么?这是一款通过引入额外条件来控制扩散模型的神经网络结构,为图像生成带来了前所未有的控制水平。初级程序员、产品经理和技术小白用户都能从中受益,了解如何利用ControlNet 1.1进行图像生成与编辑,提升设计效率及创意表现力。
ControlNet是一个神经网络结构,通过添加额外的条件来控制扩散模型,是人工智能图像生成的游戏规则改变者。它为稳定扩散带来了前所未有的控制水平。ControlNet的革命性之处在于它对空间一致性问题的解决方案。以前根本没有有效的方法来告诉人工智能模型要保留输入图像的哪些部分,而ControlNet通过引入一种方法,使稳定扩散模型能够使用额外的输入条件,告诉模型到底要做什么,从而改变了这一现状。
ControlNet 1.1在1.0基础上增加模型至14个,采用“版本号+模型状态+Stable Diffusion版本+后缀”命名规则,如control_v11p_sd15_canny。v11为1.1版,p代表模型状态,模型状态总共有三种:p、e、u。
模型状态,p表示正式版(production),e表示实验版本(experimental),u表示未完成(unfinished)。
模型名称如SD15表示基于Stable Diffusion 1.5版本的模型。后缀为.pth,同时从1.1开始所有模型都需要搭配.yaml后缀的配置文件,下载模型时需要两个.pth和.yaml两个文件。

ControlNet 1.1与ControlNet 1.0具有完全相同的体系结构,ControlNet 1.1包括所有以前的模型,具有改进的稳健性和结果质量,且增加并细化了多个模型。
ControlNet 1.1的模型命名规则采用“版本号+模型状态+Stable Diffusion版本+后缀”的格式。例如,control_v11p_sd15_canny,其中v11表示1.1版本,p代表正式版(production),模型状态还包括e(实验版本)和u(未完成)。后缀.pth表示模型文件,同时需要搭配.yaml后缀的配置文件。
更多关于命名规则的信息可以访问ControlNet 1.1核心功能的信息.
ControlNet 1.1在1.0的基础上增加了模型数量至14个,每个模型都有其独特的功能和应用场景:
每个模型的详细介绍可以在ControlNet 1.1模型介绍中找到。
在安装ControlNet 1.1之前,需要先下载模型文件。所有模型文件以.pth结尾,而.yaml文件则由ControlNet插件自动下载并放置在extensions/sd-webui-controlnet/models目录中。
为了安装ControlNet 1.1模型文件,用户需要将下载的.pth文件放置在stable-diffusion-webui/extensions/sd-webui-controlnet/models目录中。
更多关于如何获取模型文件的信息,可以查看ControlNet 1.1的历史与发展。
ControlNet 1.1需要使用与模型文件相配套的.yaml配置文件。这些文件已经包含在最新的ControlNet插件中,因此用户无需手动下载。
在配置过程中,确保所有.yaml文件在extensions/sd-webui-controlnet/models目录中与相应的.pth模型文件放置在一起。这将确保插件在使用时能够正确加载模型。
如果在配置过程中遇到问题,可以参考ControlNet的安装与配置指南。
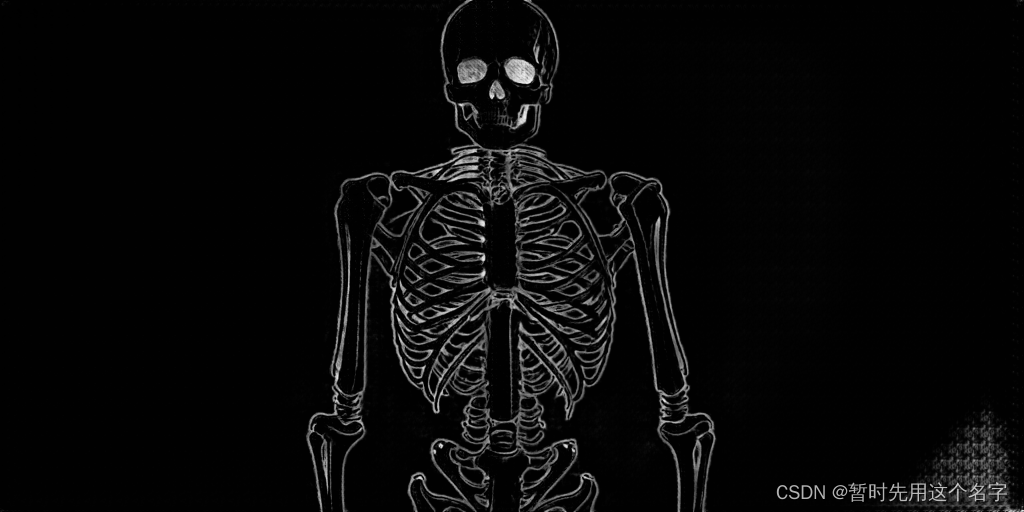
Depth深度图模型用于分析图像中的深度信息,判断不同物体的空间位置关系,例如人物与背景的前后位置、手臂在身前身后的位置等。该模型利用深度学习技术分析RGB图像中的立体要素,判断像素的深度差异,从而确定物体的空间布局,常用于人物换背景和调整手臂位置等创意设计。
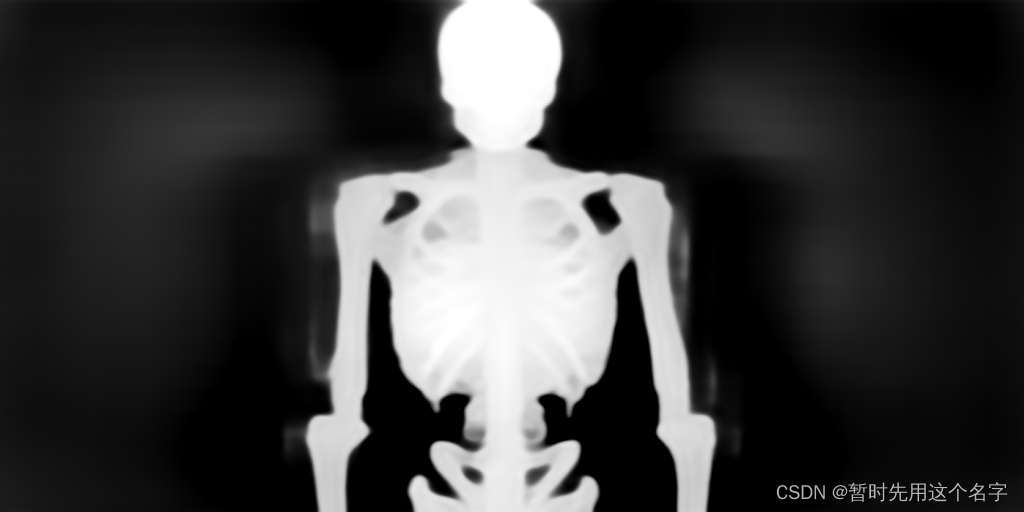
在这张示例图中,我们可以看到Depth模型如何解析图像的深度关系。更多关于Depth模型的信息可以访问ControlNet 1.1模型介绍。
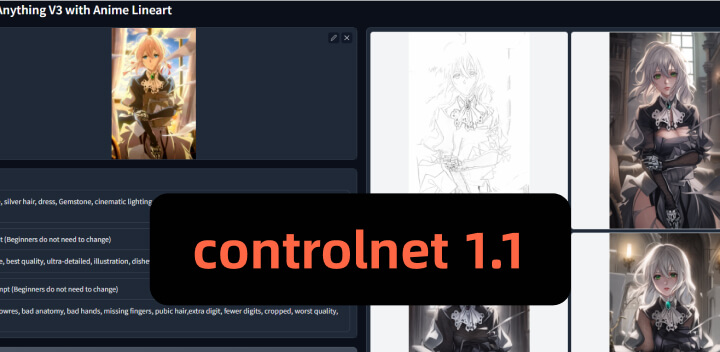
Lineart_anime模型专门用于动漫线稿的上色,它提供了自然流畅的上色效果。这个模型不支持猜测模式,需要一个基础模型如"anything-v3-full.safetensors"来运行,长提示的结果更好。
上图展示了使用Lineart_anime模型为线稿图上色的效果。更多关于Lineart_anime模型的信息可以参考ControlNet 1.1模型介绍。
在ControlNet 1.1中,启用像素完美模式可以显著提高图像的生成质量。此模式通过自动计算最佳的注释器分辨率,使每个像素都能完美地匹配稳定扩散,用户无需手动设置预处理器的分辨率。这对于需要精细图像生成的场景尤为重要。
通过启用像素完美模式,用户可以获得更高质量的图像输出,适合多种创意设计场景。了解更多关于ControlNet 1.1的历史与发展
Shuffle模型是ControlNet 1.1中的一种新型模型,专门用于图像风格迁移。它可以随机打乱图像的各个要素,包括颜色、形状和构图,并重新组合生成全新的风格化图像。这一特性使得Shuffle模型非常适合于创造性地转换图像风格,例如应用于艺术创作或广告设计。
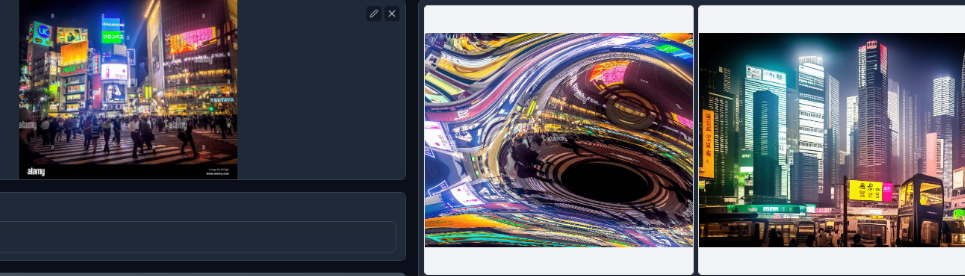
使用Shuffle模型,用户可将参考图像的风格特征迁移到源图像上,生成具有独特风格的输出图像。更多关于Shuffle模型的信息可以参考ControlNet 1.1模型介绍.







