全网最详细的Spring入门教程

本文详细回顾了从感知机到Transformer的机器学习模型发展历程,介绍了Transformer在深度学习中的核心地位及其在自然语言处理和计算机视觉领域的广泛应用。通过对关键技术如注意力机制、自注意力等深入分析,本文展示了Transformer机器学习模型如何推动生成对抗网络、大规模语言模型和视觉Transformer等突破性进展。
感知机是由弗兰克·罗森布拉特在1958年发明的一种简单的机器学习模型,用于实现二元分类。它通过单位阶跃激活函数来确定输入属于某一个类别。这种模型是现代智能机器的奠基石。
在单层感知机之后,多层感知机(MLP)被提出以解决更复杂的分类问题。通过在网络中添加多个隐藏层,MLP可以处理非线性关系,从而增强了模型的学习能力。
感知机最初被设计为一种机器,称为Mark I感知机。这台机器有400个光电管,权重由电位器编码,通过电动机进行更新。

RNN是一种处理序列数据的神经网络,具有内在的反馈回路,能够记住每个时间步的信息状态。RNN在对文本等序列数据建模方面显示出潜力。
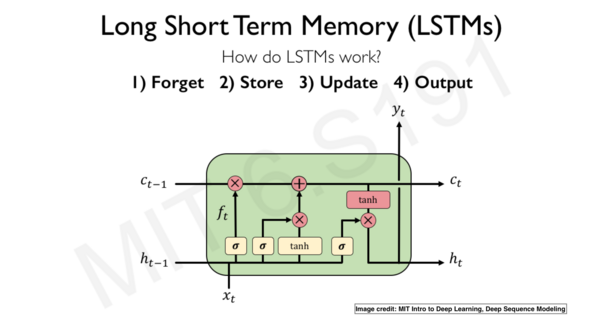
LSTM是一种可以处理长序列数据的RNN变体,通过门机制控制信息流的方式来解决梯度不稳定的问题。LSTM在文本分类、情感分析和语音识别等任务中表现优异。
尽管LSTM功能强大,但其计算成本较高。GRU(门控循环单元)通过减少参数的方式,提供了一个计算更高效的选择。
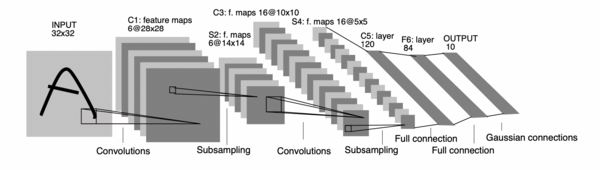
LeNet-5是1998年由Yann LeCun提出的卷积神经网络架构,首创用于文档识别,包含卷积层、池化层和全连接层。
随着AlexNet在2012年ImageNet挑战赛中取得的成功,卷积神经网络开始在计算机视觉领域被广泛应用,推动了图像分类的发展。
现代卷积网络,如VGG、GoogLeNet和ResNet,通过增加网络深度和复杂性,显著提高了视觉识别任务的准确性。
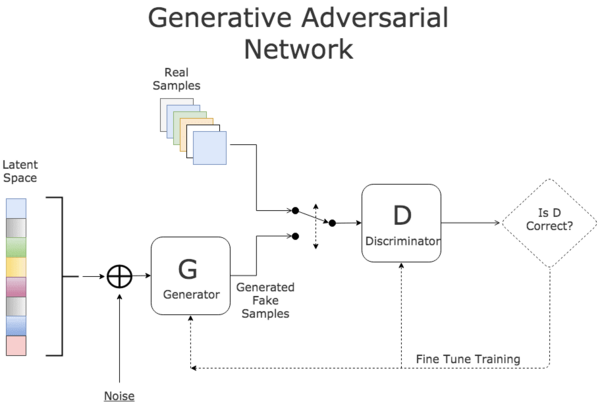
GAN由Ian Goodfellow在2014年引入,由生成器和判别器组成,用于生成逼真样本。GAN在图像生成和Deepfake等领域有着显著贡献。
除了GAN,生成模型还包括变分自编码器(VAE)和自编码器等,它们在图像合成和数据生成方面展现了强大的能力。
GAN被广泛应用于生成图像、音乐等多种数据类型,其生成的高质量样本在艺术创作和数据增强中极具价值。
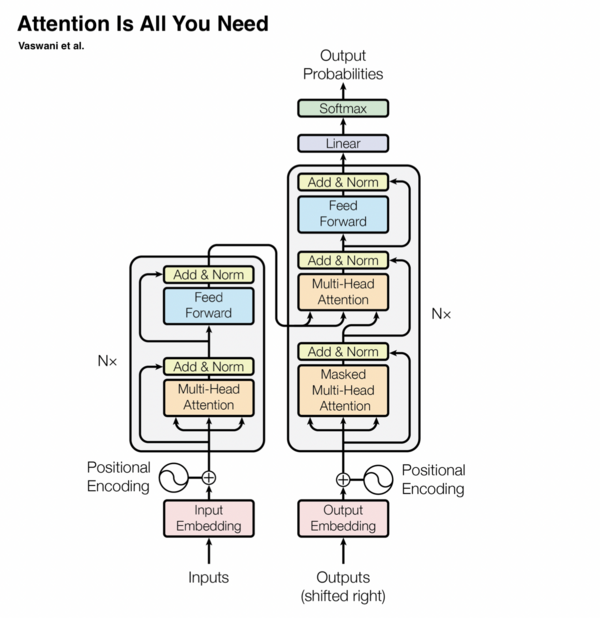
Transformer是一种基于注意力机制的深度学习模型,不依赖于循环网络或卷积。它主要由多头注意力、残差连接和层归一化等组件构成。
注意力机制允许模型在不依赖序列顺序的情况下处理数据,极大提升了计算效率,并在NLP领域引入了革命性的变化。
Transformer在机器翻译、文本摘要和语音识别等任务中表现出色,成为NLP领域的核心技术。
GPT(Generative Pre-trained Transformer)系列是大规模语言模型的典范,展现了在自然语言生成和理解中的强大能力。
基于Transformer的代码生成模型如OpenAI的Codex,可以生成和编辑程序代码,极大提升了软件开发的效率。
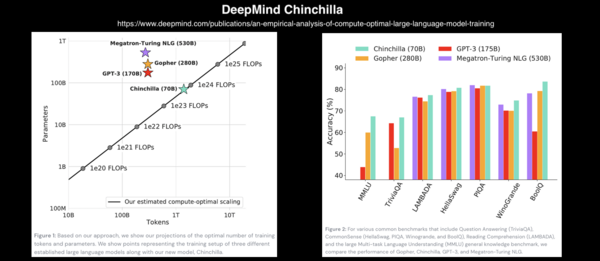
随着模型参数的不断增长,如GPT-3的1750亿参数,对计算资源的需求也在不断增加,推动了硬件和软件的共同发展。
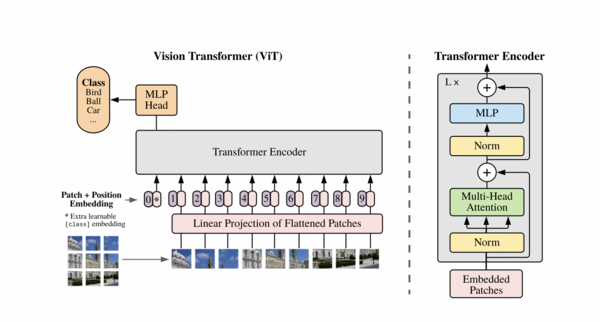
Vision Transformer(ViT)将Transformer架构应用于计算机视觉,通过图像块的处理实现了优异的图像分类性能。
多模态模型结合视觉和语言的能力,例如DALL·E 2,在文本到图像生成和图像字幕等任务中展现出色。
Swin Transformer通过使用移位窗口机制,增强了Transformer在目标检测和图像分割等下游任务中的表现。