AI聊天无敏感词:技术原理与应用实践

本文深入探讨了Transformer架构和GPT系列模型的发展历史,分析了它们在人工智能领域中的重要地位和技术创新。通过详细的时间轴和图片链接,读者可以直观地理解GPT系列模型的演进和对现代AI技术的影响。
Transformer模型由Google在2017年推出,其独特的架构设计在性能上具有显著优势,迅速成为NLP领域的明星架构。Transformer模型的核心在于自注意力机制,它使得模型能够并行处理序列数据,有效捕捉序列中的长距离依赖关系。
自注意力机制是Transformer模型中的关键创新之一。它允许模型在序列的任意位置间直接建立依赖关系,不受距离限制。这种机制使得模型在处理长序列时更加高效和准确。
由于自注意力机制的引入,Transformer模型能够实现并行处理,极大地提高了模型的训练效率。这对于大规模数据集和复杂模型尤为重要。
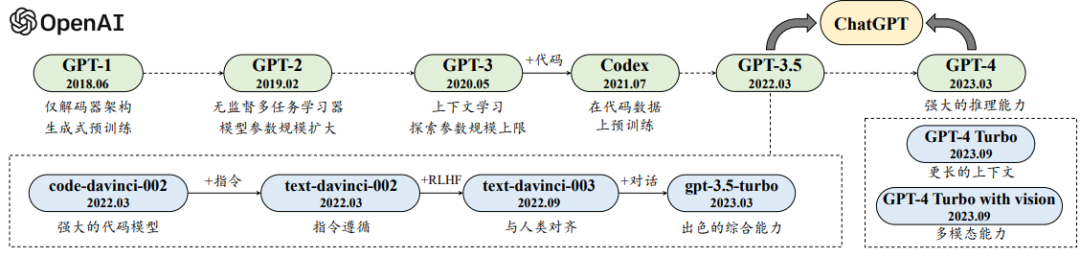
GPT系列模型由OpenAI团队开发,从GPT-1到GPT-4o,每个版本的发布都标志着AI技术的重大进步。
2018年,OpenAI发布了GPT-1模型,这是首次将Transformer架构应用于生成式预训练模型。GPT-1采用了仅有解码器的Transformer模型,专注于预测下一个词元。
GPT-2模型将参数规模扩大到15亿,使用大规模网页数据集WebText进行预训练。GPT-2的研究重点在于多任务学习,通过一种通用的概率形式来刻画不同任务的输出预测。
2020年,OpenAI推出了具有里程碑意义的GPT-3模型,其模型参数规模扩展到了175B,相较于GPT-2提升了100余倍。GPT-3首次提出了“上下文学习”概念,允许大语言模型通过少样本学习解决各种任务。
GPT-4模型首次将输入模态从单一文本扩展到图文双模态,显著增强了模型的视觉能力和安全性。GPT-4在解决复杂任务方面的能力显著强于GPT-3.5。
GPT-4o是一个多模态大模型,支持文本、音频和图像的任意组合输入,并能生成文本、音频和图像的任意组合输出。GPT-4o在视觉和音频理解方面尤其出色,展现了AI技术的全新发展方向。
大模型技术如自然语言处理和图像识别正在推动人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术。
学习大模型课程能够极大地促进个人在人工智能领域的专业发展。大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力。
整个学习分为7个阶段,从基础理论到实战案例,涵盖AI大模型的各个方面。

从入门到进阶,跟着老师学习事半功倍。