

Phenaki API 价格:探索最新技术与市场趋势

随着数据技术的迅猛发展,Text2SQL 系统越来越受到关注。这种系统能够将自然语言查询自动转换为 SQL 查询,大大简化了数据库查询过程。然而,Text2SQL 的准确率仍是一个亟待解决的问题。本文将深入探讨如何通过微调大模型和结合用户交互来提高 Text2SQL 系统的准确率。
DB-GPT-Hub 是一个专注于 Text-to-SQL 微调的项目,旨在通过使用大规模预训练语言模型(LLM)来提升 SQL 生成的准确率。项目采用了 CodeLlama 作为基础大模型,并通过微调来优化在特定数据集上的表现。特别是在 Spider 评估集上,DB-GPT-Hub 实现了 0.789 的执行准确率,超过了第三方评估的 GPT-4 的 0.762。
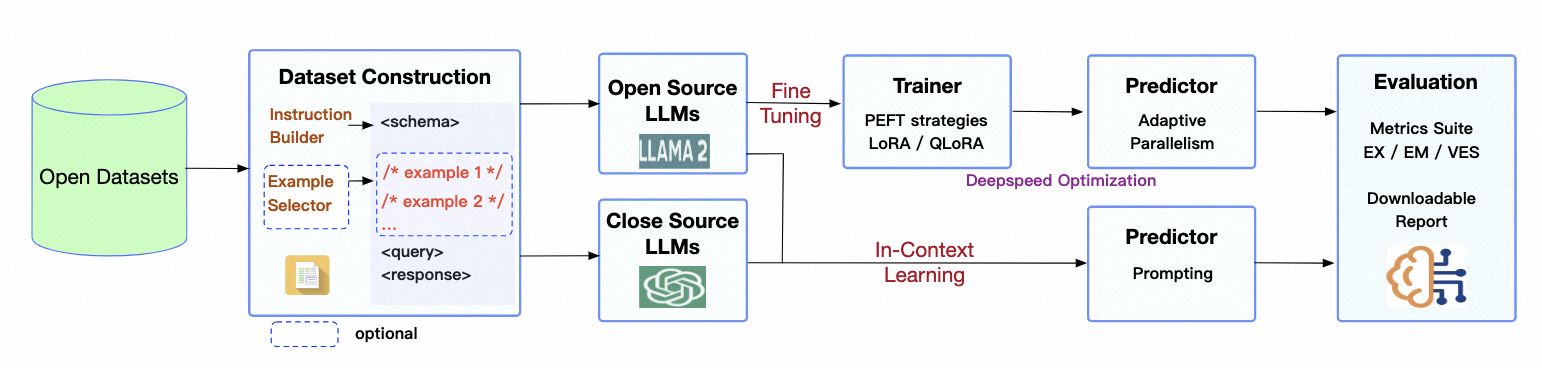
Spider 数据集是 Text2SQL 领域的基准,它包含了多个数据库和复杂 SQL 查询,是评估 Text2SQL 系统性能的关键。DB-GPT-Hub 项目通过对 Spider 数据集的处理,将复杂的 SQL 查询任务分成多个难度等级,以便更好地训练和评估模型。
在微调过程中,DB-GPT-Hub 采用了 LoRA(Low-Rank Adaptation)和 QLoRA(量化 + LoRA)技术。这些技术通过引入少量额外的网络层参数来优化模型,而不需要全量训练所有参数,从而降低训练成本。
from transformers import GPT2Model
model = GPT2Model.from_pretrained('codellama')
model.train_lora(rank=64, alpha=32)通过用户交互来提高 Text2SQL 系统的准确率是一种有效的方法。用户可以通过反馈机制帮助系统更好地理解查询意图,并在不确定的情况下提供额外信息。
主动学习策略允许系统在不确定的情况下请求用户澄清或提供更多信息。这有助于系统更快地适应新领域或术语,提高复杂查询的转换准确率。
预测和评估是验证模型效果的重要阶段。在 DB-GPT-Hub 项目中,通过对生成的 SQL 语句进行 EX(execution accuracy)和 EM(Exact Match)的评估,可以有效衡量模型的实际性能。

实验表明,经过微调的模型在处理简单 SQL 查询时表现更为突出,而在复杂 SQL 查询上仍有提升空间。针对不同难度级别的任务,微调后的模型均表现出性能提升。
LoRA 和 QLoRA 技术在提升模型性能方面效果相似,但 QLoRA 由于量化机制,收敛时间更长,占用的 GPU 内存更少。





