

如何调用 Minimax 的 API

随着AI技术的不断进步,视频生成领域迎来了一场革命性的突破。由Picsart人工智能研究所、德克萨斯大学和SHI实验室联合推出的StreamingT2V模型,凭借其开创性的自回归技术,能够生成长达两分钟的高质量视频。这一创新的模型不仅打破了视频生成的时间限制,还提供了高度连贯的动态视频体验。
StreamingT2V在技术上具有显著的优势。首先,它突破了传统视频模型在生成长度上的限制,通过自回归框架实现了时间上的扩展。其次,利用条件注意力、外观保持和随机混合等模块,确保生成视频的动作连贯性和画质。最后,该模型的开源计划为更多研究者和开发者提供了探索与创新的机会。
条件注意力模块是StreamingT2V的重要组成部分。它通过注意力机制从前一个视频块中提取特征,并注入到当前视频块的生成中。这一机制不仅保证了视频块间的自然过渡,还使得高速运动特征得以保留。图像编码器对前一个视频块的最后几帧进行逐帧编码,得到特征表示,并通过深度编码网络进行进一步处理。
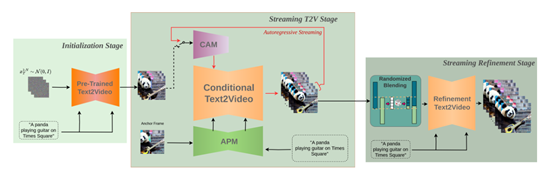
外观保持模块则是“长期记忆”的体现。通过从初始图像中提取高级场景和对象特征,并将其用于后续视频块的生成,外观保持模块确保视频的场景和对象特征在自回归生成过程中保持连续性。这种方法有效避免了生成视频中常见的场景不一致问题。

为了提升视频的分辨率和清晰度,StreamingT2V引入了随机混合模块。该模块通过自回归增强的方法,将低分辨率视频块提升至高分辨率。具体来说,研究人员将低分辨率视频划分为多个视频块,并利用高分辨率模型对其进行增强。

StreamingT2V的出现为视频生成应用打开了新的大门。其广泛的应用场景包括娱乐、教育和模拟等领域。在娱乐领域,StreamingT2V能够生成风格多样、内容丰富的视频作品,以满足用户的不同需求。在教育和培训场景中,该模型能够生成逼真的教学视频,提升学习体验和效率。
此外,StreamingT2V的开源计划将为研究者和开发者提供更多机会,在这一技术框架上进行创新和优化,推动AI视频生成技术的进一步发展。

在与其他视频生成模型的对比中,StreamingT2V表现出色。通过定量和定性评估,研究表明StreamingT2V在无缝视频块过渡和运动一致性方面优于其他方法。特别是在时间一致性和运动动态表现上,其MAWE分数比其他方法低50%以上。
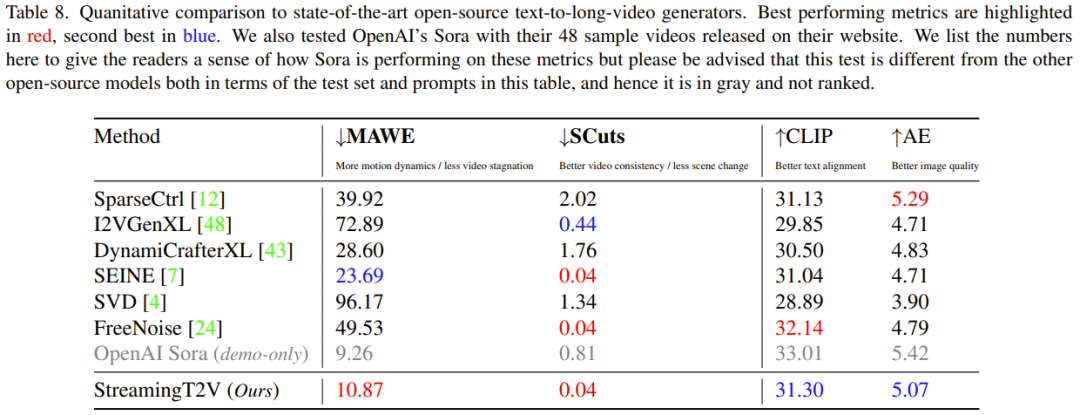
尽管StreamingT2V在视频生成领域取得了显著的成就,但仍面临着挑战。在视频质量和多元化方面,该模型还有待提升。同时,随着其他AI视频生成模型的不断涌现,StreamingT2V也需要不断创新以保持领先地位。
未来,随着技术的迭代和升级,AI生成的视频将更加生动自然,为用户带来更丰富的视觉体验。在这一过程中,StreamingT2V无疑将扮演重要角色。
问:StreamingT2V如何确保视频的时间连贯性?
问:StreamingT2V的开源计划对开发者有什么帮助?
问:StreamingT2V与传统视频生成方法相比有什么优势?
问:随机混合模块如何提升视频的清晰度?
问:在AI视频生成领域还有哪些其他模型值得关注?





