

如何调用 Minimax 的 API

在AI生成内容(AIGC)的技术浪潮中,视频生成技术的进步尤为引人注目。传统视频生成模型在生成长视频时面临着诸多挑战,例如视频内容的一致性和生成速度的瓶颈。为了应对这些挑战,Picsart人工智能研究所、德克萨斯大学和SHI实验室的研究人员联合开发了StreamingT2V模型。这一模型通过一种创新的自回归技术框架,能够生成长达数分钟的高质量视频,标志着AI视频生成领域的重大突破。

StreamingT2V模型的核心在于其自回归技术框架,该框架主要由三个模块组成:条件注意力模块(CAM)、外观保持模块(APM)和随机混合模块。这些模块共同作用,确保了生成视频的时间一致性和质量。
条件注意力模块作为“短期记忆”,通过注意力机制从前一个视频块中提取特征,并注入到当前视频块的生成中。这种机制不仅保证了视频块之间的流畅过渡,还保留了视频中的高速运动特征。例如,在生成一段蜜蜂在花丛中飞舞的视频时,CAM能够捕捉蜜蜂的运动轨迹并将其自然地连接在一起。
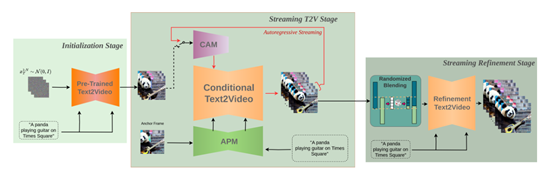
外观保持模块则作为“长期记忆”,从初始图像(锚定帧)中提取全局场景和对象特征。这些特征贯穿于所有视频块的生成流程中,确保生成视频的全局场景和外观一致性。例如,在生成一段长时间的风景视频时,APM可以确保山川、河流等元素在整个视频中的位置和形态保持一致。

随机混合模块进一步优化了视频的分辨率和时间连贯性。通过自回归增强的方法,随机混合模块能够有效地提高视频的清晰度,并使视频块之间的过渡更加自然。实验表明,这种方法在生成高分辨率长视频时表现尤为出色。

StreamingT2V模型在多个领域展现出了广泛的应用潜力。在娱乐和创意内容生成方面,StreamingT2V能够轻松生成各种风格的视频作品,满足用户多样化的需求。同时,在教育、培训和模拟等领域,StreamingT2V通过生成逼真的教学视频和模拟场景,为学习者提供更加直观、生动的体验。

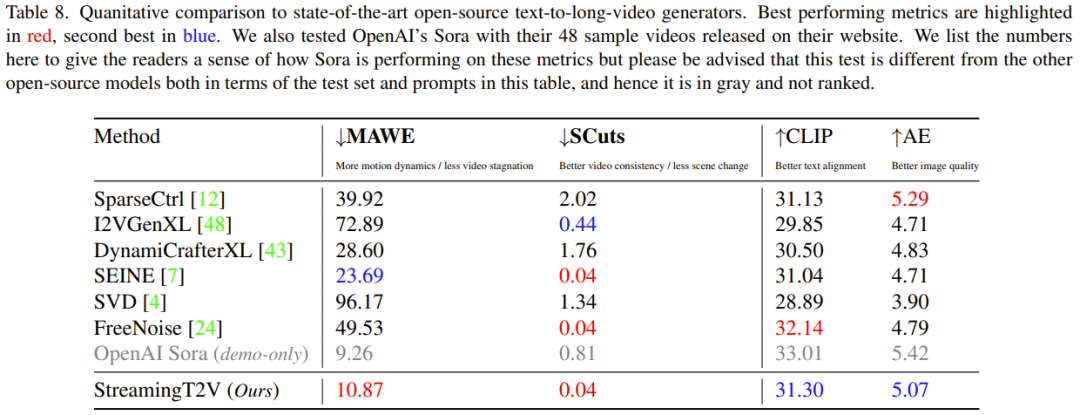
在实验阶段,研究团队使用了多种评估指标来验证StreamingT2V的性能。这些指标包括时间一致性的SCuts分数、运动感知扭变误差(MAWE)、文本图像相似度分数(CLIP)以及美学分数(AE)。结果显示,StreamingT2V在视频质量、时间一致性和文本对齐方面均优于现有的基线模型。

通过与其他视频生成模型的对比研究,StreamingT2V在无缝视频块过渡和运动一致性方面表现最佳。与使用自回归方法的图像到视频方法如I2VGen-XL、SVD、DynamiCrafter-XL等模型相比,StreamingT2V的综合性能更为出色。
尽管StreamingT2V已经在长视频生成领域取得了显著的进展,但在视频质量和多元化方面仍有提升空间。随着技术的不断进步和其他AI视频生成模型的竞争,StreamingT2V需要不断创新和升级,以保持其在市场中的领先地位。

StreamingT2V的推出标志着AI视频生成技术进入了一个新的发展阶段。通过其创新的自回归框架,StreamingT2V不仅实现了高质量长视频的生成,还为视频生成技术的研究和应用开发提供了坚实的基础。随着这一技术的不断迭代,AI生成的视频将逐渐渗透到我们的日常生活中,为我们带来更加丰富多彩的视觉体验。
问:StreamingT2V的核心技术是什么?
问:StreamingT2V在实际应用中有哪些优势?
问:如何评估StreamingT2V的性能?
问:StreamingT2V与其他视频生成模型相比有哪些优势?
问:未来StreamingT2V的发展方向是什么?





