

如何调用 Minimax 的 API
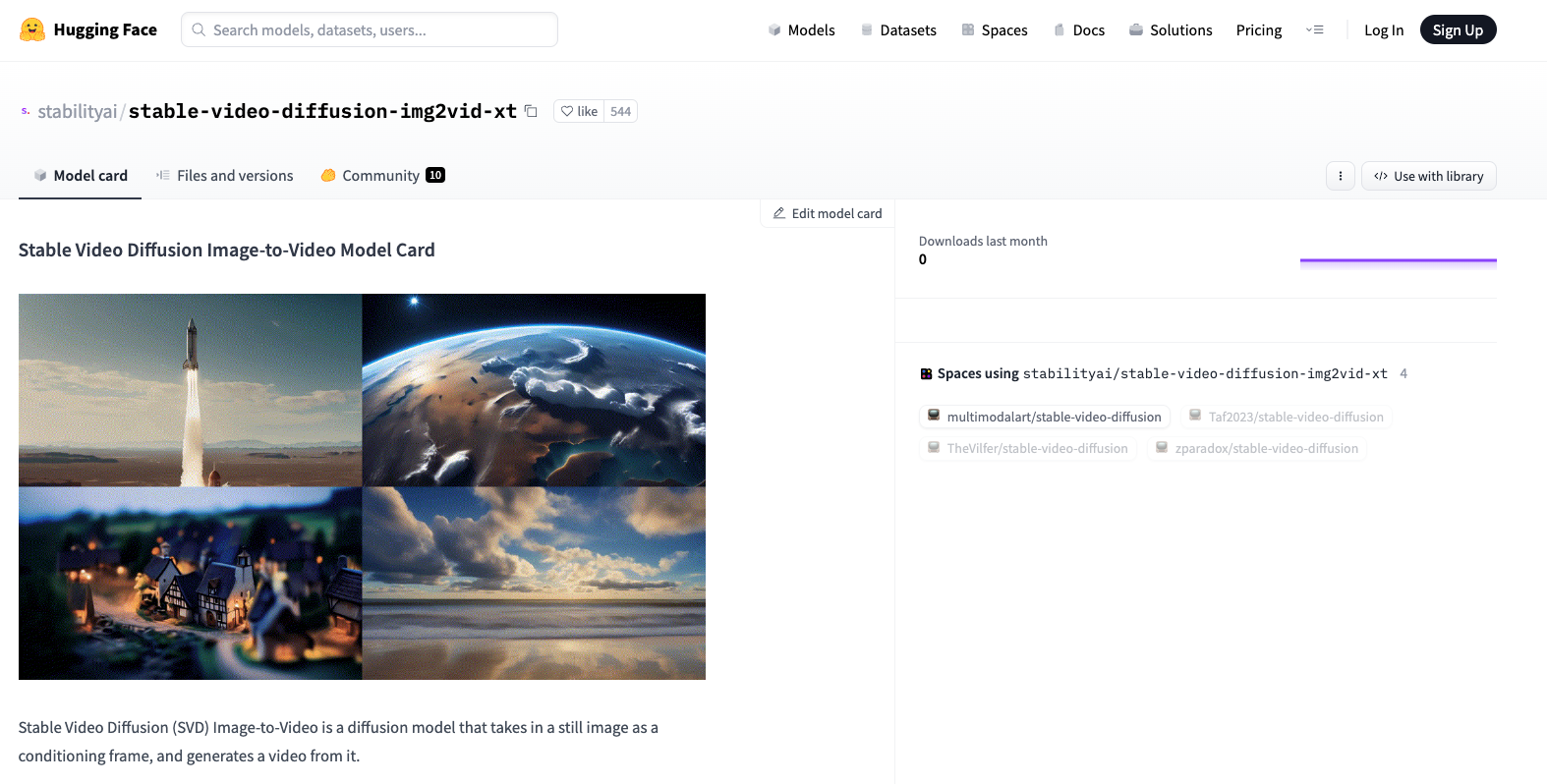
Stable Video Diffusion 是 Stability AI 推出的首个基于图像模型 Stable Diffusion 的生成式视频基础模型。自 2023 年 11 月问世以来,该工具在 GitHub 上开源,并在 Hugging Face 上发布了模型运行所需的权重。这一模型的诞生标志着视频生成技术的又一次飞跃,为各类媒体应用提供了全新的可能性。

Stability AI 的这一开创性工作不仅为开发者提供了灵活的开发环境,还计划围绕该基础模型建立一个完整的生态系统,使其能够适应多种下游任务。根据外部评估,Stable Video Diffusion 的模型 SVD 和 SVD-XT 在用户偏好研究中表现优于其他同类产品。
Stable Video Diffusion 依赖于扩散模型(DMs)和无分类器引导,并结合专门设计的视频生成基础模型架构。这一复杂的技术架构使得模型能够将文本和图像输入转化为生动的视频场景。
扩散模型在生成过程中起到关键作用,通过逐步改进和细化输入数据,使得输出视频更加自然和逼真。该模型能够生成 14 帧和 25 帧的视频,帧速率在 3 到 30 帧每秒之间可调。
无分类器引导是另一项关键技术,它通过避免使用分类器来减少可能的偏差,从而提高生成视频的质量和一致性。

Stable Video Diffusion 可广泛应用于媒体、娱乐、教育和营销等领域。其核心功能包括:
这些功能使得用户能够快速生成高质量的短视频,满足各种应用场景的需求。
在媒体和娱乐领域,Stable Video Diffusion 可以用于生成动画短片、影视特效等,提高创作效率和作品质量。
在教育和营销领域,该模型可以用于制作生动的教学视频和广告片段,提升信息传达的效果和用户体验。
虽然 Stable Video Diffusion 提供了许多创新功能,但在使用过程中仍存在一些局限性。Stability AI 强调,目前该模型还不适用于实际或商业应用,且网页体验尚未向所有人开放。
该模型的推出主要是为了研究目的,以便在不断的实践中改进和优化其性能。
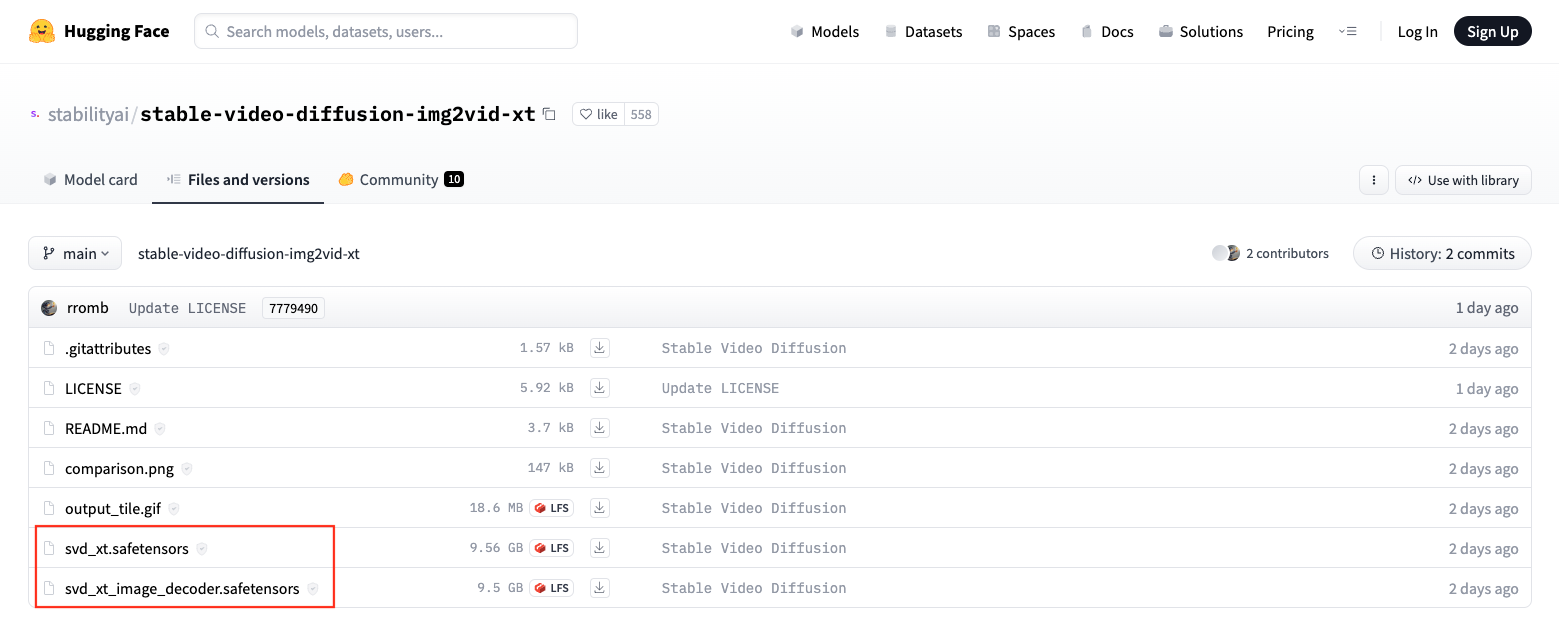
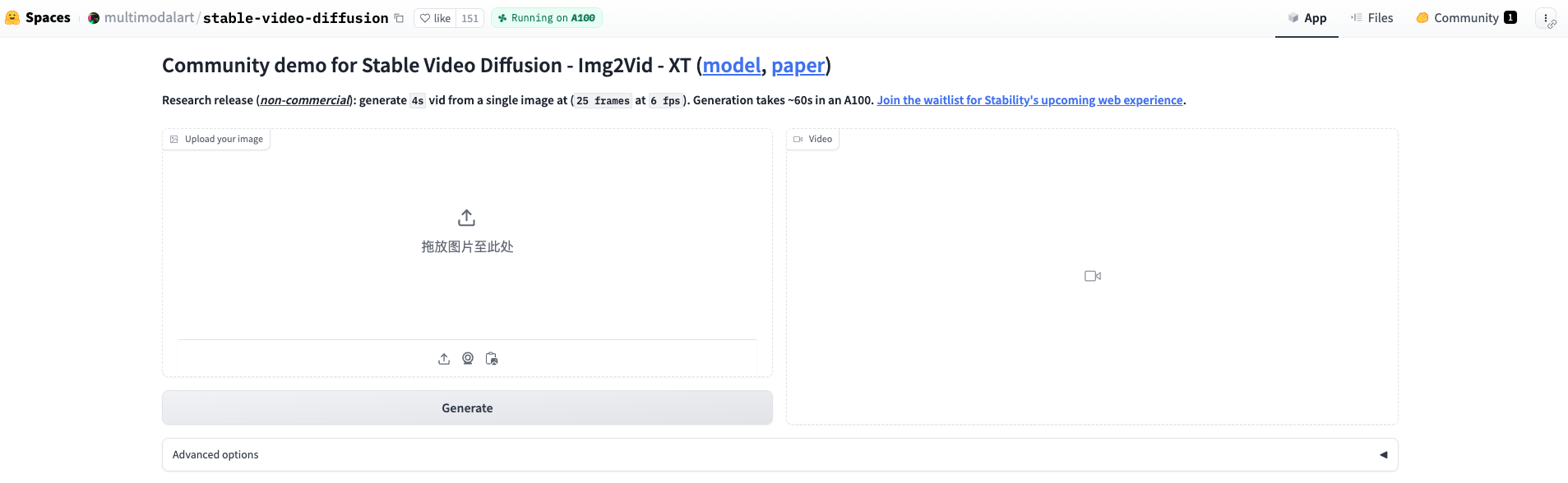
用户可以通过 Hugging Face 的体验链接访问 Stable Video Diffusion。虽然目前访问存在一些限制,但感兴趣的用户仍可通过申请候补来体验该模型。
随着技术的进步,Stable Video Diffusion 未来可能会在以下几个方面进行改进:
通过不断优化模型架构和算法,提升视频质量和生成速度。
开发更多应用场景,使其在商业广告、影视制作等领域发挥更大作用。
访问以下链接了解更多 Stable Video Diffusion 的相关信息和技术细节:
问:Stable Video Diffusion 可以用于商业项目吗?
问:如何提高生成视频的质量?
问:Stable Video Diffusion 的视频生成速度如何?
通过这篇文章,希望读者对 Stable Video Diffusion 的开源版本有一个全面的了解,并对其在不同领域的应用潜力有更深入的认识。





