

GLIDE 常用提示词:稳定扩散模型的深度解析

在现代计算机视觉领域,Stable Diffusion 已成为一个备受关注的技术。作为一种先进的文本到图像生成模型,Stable Diffusion 运用了潜在扩散模型(Latent Diffusion Models, LDMs),结合大规模的计算资源和数据集,能够实现高效的图像生成。本篇文章将深入探讨Stable Diffusion的应用代码及其实现原理,并提供相关图片链接和FAQ,帮助读者更好地理解和应用这一技术。
Stable Diffusion 是一种基于潜在扩散模型的文本到图像生成技术。通过在潜在空间中迭代去噪,该模型能够生成高质量的图像,并支持消费者级别 GPU 在短时间内完成图像生成。这一技术的实现得益于大规模数据集(如 LAION-5B)和计算资源的支持。Stable Diffusion 的核心在于其潜在空间表示以及结合文本特征的扩散过程,让我们从Latent Space开始探讨。
Latent Space(隐空间)是指经过降维处理后数据的紧凑表示。在Stable Diffusion中,Latent Space 是图像生成过程中至关重要的一环。通过对图像特征进行降维处理,模型能够在去除噪声的同时保留关键特征。解码器需要通过学习如何将这些特征重构为完整的图像。Latent Space 的优势在于它简化了计算过程,使得图像生成在资源消耗和时间效率上更加优化。
AutoEncoder 是一种神经网络结构,旨在通过 Encoder 压缩输入数据,再通过 Decoder 还原数据,使得输出尽量与输入相同。其核心在于压缩过程中保留重要信息,去除冗余特征。在Stable Diffusion中,AutoEncoder 主要用于初步的特征提取和数据降维,帮助模型更好地理解并重建图像。
变分自编码器(Variational AutoEncoder, VAE)是 AutoEncoder 的一种扩展,通过对输入数据的潜在表示进行概率建模,VAE 能够生成新数据。VAE 通过假设潜在变量服从某一已知分布(如标准高斯分布),并利用此分布进行采样和重建。在Stable Diffusion中,VAE 的角色是生成潜在特征并将其与文本特征结合用于图像生成。
在前向过程中,模型从初始图像生成噪声,并逐步迭代产生各时刻的潜在表示。每一步的生成都基于上一步的表示和随机噪声,具体过程如下:
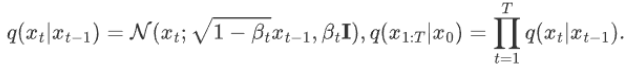
逆向过程的目标是从给定的噪声状态恢复到清晰的初始图像。利用贝叶斯公式,通过迭代地减少噪声,模型能够逐步得到更接近原图的表示。逆向过程的实现需要精确的噪声预测和去噪算法。

Unet 中引入 Cross Attention 机制,通过结合文本和图像的多模态信息,增强模型生成的准确性。在这一过程中,模型将文本特征和潜在图像特征进行交叉注意力处理,实现了不同模态之间的信息融合。
Stable Diffusion 的训练过程涉及多个阶段,核心包括以下几个步骤:
推理阶段,模型通过输入文本描述生成图像,过程如下:
在开始使用Stable Diffusion的代码之前,需要安装相关的Python包,如 transformers 和 diffusers:
!pip install --upgrade diffusers transformers确保安装的版本符合项目要求,以避免兼容性问题。
Stable Diffusion 的实现涉及多个模块,以下是关键代码段的解析:
import torch
from diffusers import UNet2DConditionModel, PNDMScheduler, AutoencoderKL
from transformers import CLIPTokenizer, CLIPTextModel
text_tokenizer = CLIPTokenizer.from_pretrained(model_path)
text_encoder = CLIPTextModel.from_pretrained(model_path)
unet = UNet2DConditionModel.from_pretrained(model_path)
vae = AutoencoderKL.from_pretrained(model_path)
text_inputs = text_tokenizer(prompt, return_tensors='pt')
text_embeddings = text_encoder(text_inputs.input_ids)[0]
scheduler = PNDMScheduler()
scheduler.set_timesteps(num_timesteps)
latents = torch.randn((batch_size, latent_dim), generator=generator)
for t in scheduler.timesteps:
latents = scheduler.step(latents, t, text_embeddings)
image = vae.decode(latents)在实际应用中,可以根据需要对模型和代码进行扩展和优化,如调整扩散步数、优化推理速度等。此外,通过结合其他视觉模型或增强技术,可以进一步提升生成效果。
Stable Diffusion 作为一种创新的文本到图像生成技术,展现了其在计算机视觉领域的巨大潜力。通过对其核心组件和实现过程的详细解析,我们可以更好地理解其工作原理,并应用于实际项目。本文提供的代码示例和FAQ也为读者在使用过程中提供了实用的指导。
问:Stable Diffusion 适用于哪些应用场景?
问:如何提高Stable Diffusion模型的生成质量?
问:Stable Diffusion 与其他生成模型有何不同?
问:是否需要高性能硬件来运行Stable Diffusion?
问:如何在Stable Diffusion中加入自定义的文本描述?







