

PixVerse V3 API Key 获取:全面指南与实践

Sora架构的引入为视频生成领域带来了革命性的变化。通过采用先进的架构设计,Sora有效地将空间和时间解耦合,实现了高效的视频生成。尤其是在处理长时间视频生成时,Sora展示了其卓越的性能和灵活性。通过集成空间-时间扩散Transformer(STDiT),Sora能够在保持高质量的同时,加速训练过程。

在Sora架构中,Token化方法是实现高效视频生成的关键。通过将视频数据转换为Token,系统能够更高效地处理视频数据的空间和时间信息。这种方法不仅提高了模型的处理速度,还增强了生成视频的质量。Token化方法的引入使得Sora能够更好地适应多样化的视频生成需求。
数据集的质量直接影响模型的训练效果。Sora在数据集的选择和预处理上投入了大量精力。所使用的数据集包括Webvid-10M、Panda-70M、HD-VG-130M等,确保了模型训练的多样性和质量。此外,通过建立完整的数据处理pipeline,Sora能够将原始视频数据无缝转换为可用于训练的高质量视频-文本对。
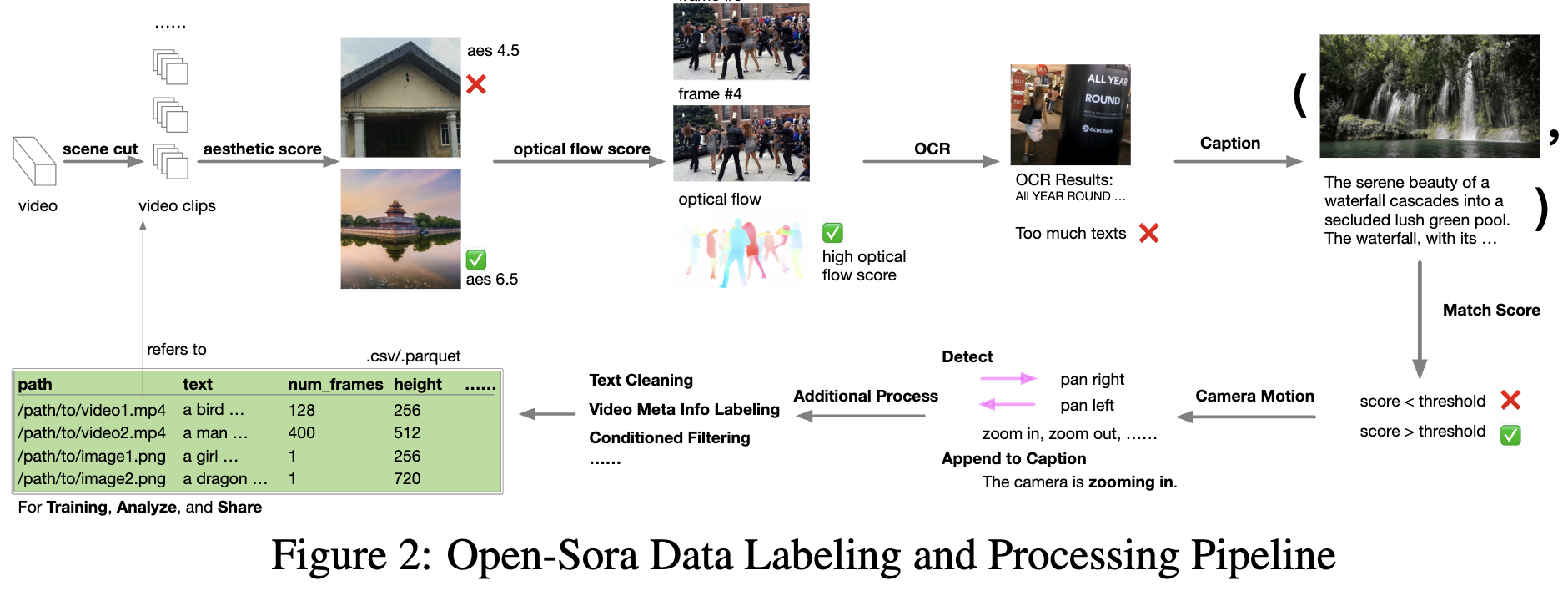
Sora的数据预处理过程包括场景检测与视频剪辑、高质量视频过滤和视频字幕生成等步骤。通过使用PySceneCut进行场景检测,Sora能够有效地将视频分割为多个片段。这一过程结合了美学评分、光流评分和OCR过滤,确保了训练数据的高质量。
Sora的模型架构基于PixArt,是一种图像扩散Transformer。通过引入空间-时间注意力机制,Sora能够高效处理视频的空间和时间信息。这种创新的架构设计替代了传统的完全注意力机制,使得模型在性能和效率上都有显著提升。
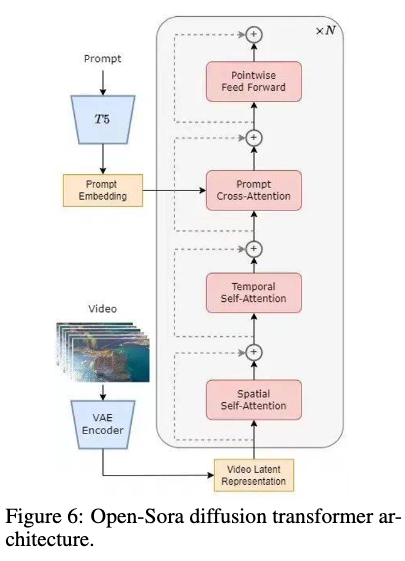
在Sora中,3D自编码器用于视频的空间压缩。通过结合2D VAE的知识,Sora能够在时间维度上实现4倍压缩。这种方法不仅降低了计算成本,还提高了视频生成的流畅性和质量。
为了实现高效的视频生成,Sora采用了多阶段训练策略。通过流匹配和多分辨率训练,Sora在保持高质量视频生成的同时,显著降低了训练成本。整个训练过程包含68k步,使用了35,000 H100 GPU小时。
Sora通过分桶方法支持多分辨率和多长宽比的视频生成。每个桶由分辨率、帧数和长宽比定义,确保了样本的均衡分布。这种策略不仅提高了训练效率,还增强了模型的灵活性。
尽管文本到视频生成具有高度的多样性,Sora通过引入图像和视频输入的遮罩策略,实现了精确的条件控制。这种方法使模型能够对条件输入有更细致的理解,从而提高了生成视频的质量和一致性。

随机遮罩策略是Sora实现条件控制的关键之一。通过对50%的训练样本应用mask策略,Sora能够有效学习图像和视频的条件控制能力。这种策略不仅提升了模型的适应性,还优化了生成效果。
Sora代表了视频生成技术的前沿,通过创新的架构设计和高效的训练策略,Sora实现了高质量、灵活的视频生成。其开源的特性和全面的框架使得Sora在社区中得到了广泛应用和认可。
问:什么是Sora架构的核心优势?
问:Sora如何保证数据集质量?
问:如何应用Sora的条件控制策略?
问:Sora支持哪些分辨率的视频生成?
问:Sora的开源对社区有何贡献?





