对多模态大模型的检索增强策略与应用
本文探讨了多模态大模型在检索增强生成中的应用,重点介绍了Wiki-LLaVA架构,它通过将外部知识检索与多模态大模型结合,显著提升了视觉问答性能。通过对多模态检索策略的深入分析,展示了如何利用多模态信息提升大模型在处理复杂任务中的能力。
引言
多模态大模型的趋势
多模态大模型是现代人工智能发展的必然趋势。随着技术的进步,单一模态的模型已经无法满足日益复杂的任务需求。多模态大模型通过结合文本、图像等多种数据类型,提升了模型的性能和应用广度。检索增强生成(RAG)是目前提升模型适应性的关键。
Wiki-LLaVA的出现
为了应对模型在处理视觉问答任务时的不足,Wiki-LLaVA架构应运而生。它结合了外部知识检索和多模态大模型(MLLMs),显著提升了视觉问答性能。
文本与视觉的结合
Wiki-LLaVA不仅增强了生成能力,还保持了泛化性能。通过将外部知识与视觉特征结合,模型在复杂任务中的表现得到了大幅提升。
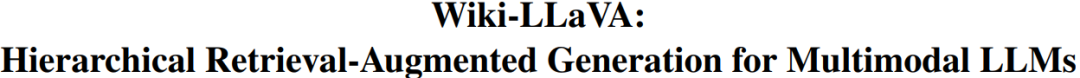
背景介绍
大模型的发展
大模型的发展始于其对多种任务的处理能力。通过微调模型,AI可以吸收外部指令,实现强大的泛化能力。计算机视觉领域也开始探索多模态模型的潜力。
多模态模型的优势
多模态模型通过视觉到语言的适配器,将视觉特征融合进语言模型(LLM),显著提升了视觉任务的性能。在复杂视觉描述任务中,表现尤为出色。
挑战与解决方案
尽管多模态模型功能强大,但在面对特定用户需求和组合推理时仍有局限性。为此,引入了新的基准测试来评估模型处理外部数据的能力,而Wiki-LLaVA正是这一挑战的解决方案。
WikiLLaVA模型解析
网络架构
Wiki-LLaVA的架构包括视觉编码器、知识库和分层检索模块。视觉编码器提取输入图像的特征,知识库则提供丰富的信息支持。
视觉编码器的作用
视觉编码器在Wiki-LLaVA中扮演着关键角色。它通过CLIP技术提取图像特征,为检索模块提供了精确的查询基础。
分层检索模块
分层检索模块通过分层方式检索知识库中的相关信息,帮助模型在回答问题时注入外部知识,提升回答准确性。
实验结果分析
实验数据集
Wiki-LLaVA在Encyclopedic-VQA和InfoSeek数据集上进行了测试。这些数据集为评估模型在复杂视觉问答任务中的表现提供了基础。
性能对比
实验结果显示,Wiki-LLaVA在提供准确答案方面具有显著优势。与LLaVA-1.5模型相比,Wiki-LLaVA在多个基准测试中的表现更为优越。
失败案例分析
虽然Wiki-LLaVA表现出色,但仍存在一些失败案例。这些案例为进一步优化多模态大模型提供了研究方向。

多模态RAG概念详解
标准RAG的原理
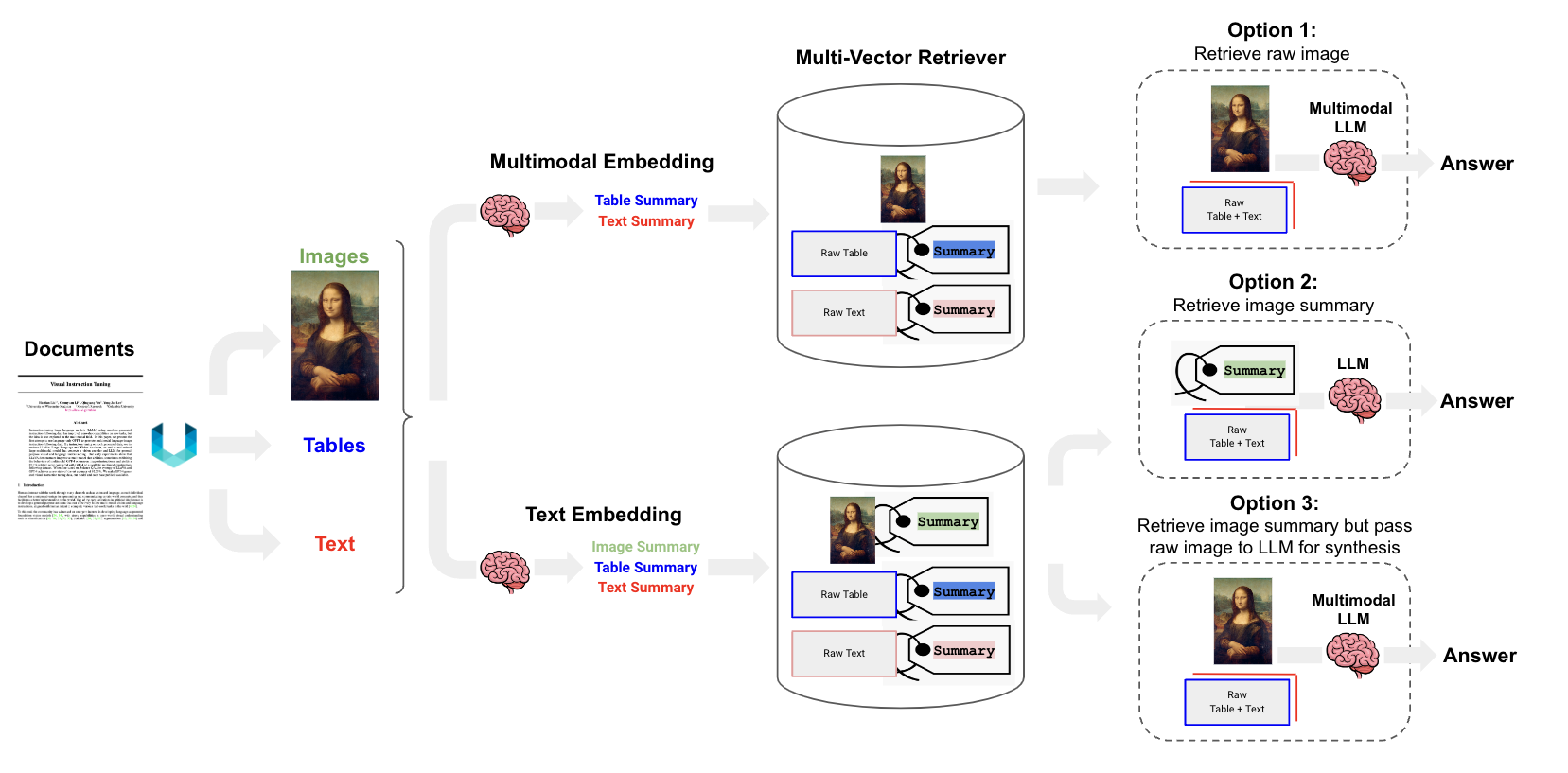
标准RAG通过检索相关信息并将其注入到Prompt中,提升了LLM的回答能力。多模态RAG则通过引入多种数据类型,进一步增强了模型的性能。
多模态的定义
多模态指的是多种数据类型的结合,如文本、图像、音频等。多模态模型利用联合Embedding策略,实现了对不同数据类型的统一理解。
多模态RAG的实现
多模态RAG允许系统通过对多种模态信息的检索,提升模型的回答能力,从而实现对复杂问题的更准确回答。
多模态检索策略对比
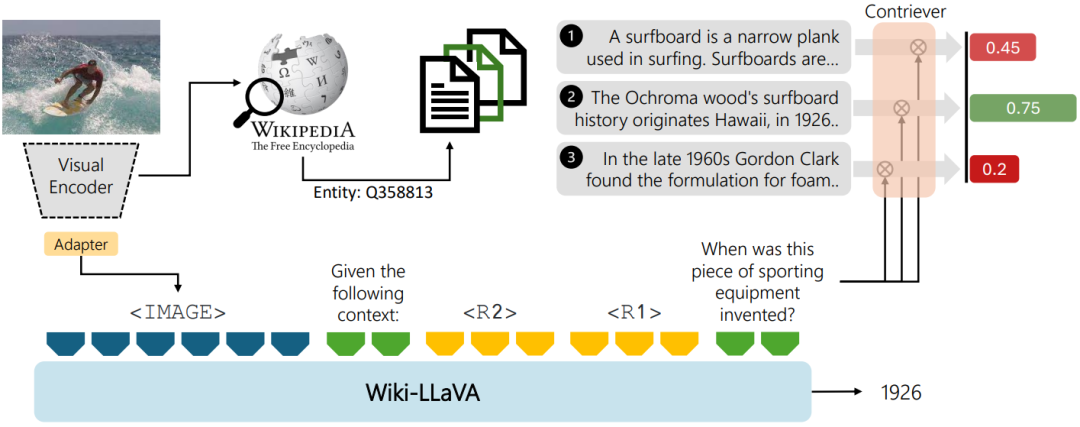
Option 1:文本与图像嵌入
通过多模态LLM对文本和图像进行embedding,实现相似检索,进而提升模型的回答精确度。
Option 2:文本摘要生成
利用多模态LLM生成文本摘要,再通过embedding进行检索,增强模型的回答能力。
Option 3:图片与文本结合
结合文本摘要与原始图片,利用多模态LLM获取更为准确的回答,是多模态RAG的另一种实现策略。
开源Demo推荐与应用
kotaemon
kotaemon提供了一种支持多模态的高性能Demo,支持图片、URL、PDF等多种文件格式的处理,适用于广泛的应用场景。
clip_blip_embedding_rag
该系统基于CLIP/BLIP模型,提供文本和图像嵌入生成与相似度计算,为多模态信息检索提供了基础。
应用场景
这些开源Demo在实际应用中展示了多模态RAG的强大潜力,为开发者提供了丰富的工具选择。
FAQ
问:什么是多模态大模型,它为什么是现代人工智能发展的趋势?
- 答:多模态大模型结合了文本、图像以及其他数据类型,提升了模型的性能与应用广度。随着任务复杂性的增加,单一模式的模型已无法满足需求,因此多模态大模型成为现代人工智能发展的必然趋势。
问:Wiki-LLaVA如何增强视觉问答性能?
- 答:Wiki-LLaVA通过结合外部知识检索和多模态大模型(MLLMs),显著提升了视觉问答性能。它通过视觉编码器和分层检索模块,精确提取图像特征并注入外部知识,提高回答的准确性。
问:在Wiki-LLaVA的架构中,视觉编码器有什么作用?
- 答:在Wiki-LLaVA中,视觉编码器通过CLIP技术提取输入图像的特征。这些特征为分层检索模块提供了精确的查询基础,帮助模型在回答问题时注入外部知识。
问:如何通过多模态RAG提升模型的回答能力?
- 答:多模态RAG通过对多种模态信息的检索,增强了模型的回答能力。它不仅结合文本和图像等多种数据类型,还通过联合Embedding策略,实现对不同数据类型的统一理解,从而对复杂问题做出更准确的回答。
问:开源Demo如kotaemon和clip_blip_embedding_rag在多模态RAG的应用中有什么作用?
- 答:kotaemon和clip_blip_embedding_rag提供了支持多模态的高性能演示,处理图片、URL、PDF等多种文件格式。这些开源Demo展示了多模态RAG的强大潜力,为开发者提供了丰富的工具选择和应用场景。