

SQL注入攻击深度解析与防护策略

在深度学习领域,激活函数扮演着至关重要的角色,它们决定了人工神经元的输出方式,从而影响了网络的学习效率和效果。在众多激活函数中,修正线性单元(Rectified Linear Unit,ReLU)因其简单、高效而脱颖而出,成为深度神经网络中最受欢迎的激活函数之一。本文将深入探讨ReLU函数的原理、优势、应用及其在深度学习中的重要性。
ReLU函数的灵感来源于对生物神经元激活特性的研究。2001年,Dayan和Abott模拟出了脑神经元接受信号的激活模型,该模型展示了神经元的放电速率与时间的关系。下图展示了这一模型的直观表现:
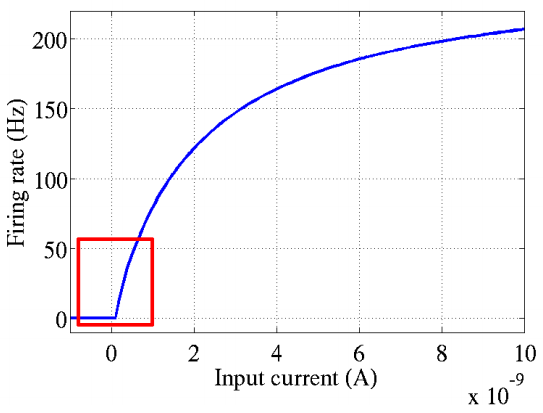
从图中可以看出,神经元的激活具有明显的稀疏性,即大部分时间神经元是不激活的,只有少数时间点神经元被激活。这种稀疏性是ReLU函数设计的重要理论基础。
ReLU函数的数学表达式非常简单:
f(x) = max(0, x)这意味着当输入x小于0时,输出为0;当输入x大于0时,输出等于x。这种非线性激活函数在数学上体现了单侧抑制的特性,即负值被抑制,而正值被保留。
ReLU函数之所以在深度学习中广泛应用,主要得益于其以下几个优势:
ReLU函数通过将负值置为0,实现了模型输出的稀疏性。这种稀疏性使得模型更加关注于那些重要的、有信息量的特征,从而提高了模型的泛化能力。
ReLU函数在正值区域的梯度恒为1,这意味着在训练过程中,梯度不会随着网络深度的增加而衰减,从而有效避免了梯度消失问题。
与其他需要复杂数学运算(如指数运算)的激活函数相比,ReLU函数的计算非常简单,只需要一个阈值判断即可,这大大加快了网络的训练速度。
ReLU函数因其上述优势,在多种深度学习模型中得到了广泛应用,特别是在卷积神经网络(CNN)中。
在CNN中,ReLU函数常用于隐藏层,以增强网络的非线性表达能力,并提高训练效率。
在处理序列数据时,ReLU函数可以减少时间步之间的依赖,从而减轻长期依赖问题。
在GAN中,ReLU函数被用于生成器和判别器的构建,以增强模型的稳定性和生成效果。
尽管ReLU函数有许多优点,但也存在一些潜在的问题需要关注。
当输入持续为负时,ReLU函数的输出将始终为0,导致相应的神经元不再更新,即所谓的神经元死亡问题。
ReLU函数在训练初期可能会导致模型权重的不稳定,需要仔细的初始化和学习率调整来控制。
ReLU函数的输出不是零对称的,这可能会影响某些算法的性能,特别是在需要零中心化数据的场景中。
为了解决ReLU函数的一些缺点,研究者们提出了一些改进版本。
Leaky ReLU允许小的梯度值当输入为负时,避免了神经元死亡问题。
Parametric ReLU是Leaky ReLU的泛化,其中的斜率参数可以通过学习得到。
Randomized ReLU对输入为负的样本随机地允许一部分梯度通过,增加了模型的鲁棒性。
ELU是另一种改进的激活函数,它对负值的输入输出负值,并且具有自归一化的特性。
在实际编程中,ReLU函数可以通过多种深度学习框架实现,以下是使用Python和TensorFlow进行ReLU函数实现的示例代码:
import tensorflow as tf
x = tf.constant([-2, -1, 0, 1, 2], dtype=tf.float32)
relu_x = tf.nn.relu(x)
print(relu_x)答:ReLU函数在正值区域的梯度恒为1,这意味着梯度不会随着网络层数的增加而衰减,有效避免了梯度消失问题。
答:ReLU函数通过将负值置为0,实现了输出的稀疏性,这有助于模型更加关注于重要的特征,提高了模型的泛化能力。
答:ReLU函数的主要缺点包括神经元死亡问题、输出不零对称以及在训练初期可能导致的不稳定性。
答:改进的ReLU函数版本包括Leaky ReLU、Parametric ReLU、Randomized ReLU和Exponential Linear Unit (ELU)等。
答:在实际编程中,可以使用多种深度学习框架如TensorFlow、PyTorch等实现ReLU函数,代码实现简单,只需要一个阈值判断即可。
通过本文的深入分析,我们可以看到ReLU函数在深度学习中的重要作用和广泛应用。尽管存在一些缺点,但其优势使其成为当前最流行的激活函数之一。随着深度学习技术的不断发展,ReLU函数及其改进版本将继续在构建高效、强大的神经网络中发挥关键作用。




