

AI视频剪辑工具:解锁创作的无限可能

在语音技术飞速发展的时代,实时语音转文字技术已成为语音助手、在线会议记录、字幕生成等应用的核心功能。此类技术通过高效的语音识别算法和深度学习模型,能够将语音数据快速转换为文本,支持多种语言并易于集成。本文将介绍几款开源的实时语音转文字工具,分析其技术优势及应用场景,帮助开发者更好地构建语音驱动应用。
RealtimeSTT是一款开源的实时语音转文字工具,它通过流式处理技术实现高效的语音转录。这使得它在需要即时反馈的应用场景中表现卓越,例如在线会议和语音助手。其低延迟的特点确保了实时性,能够在语音输入的同时输出文本。
RealtimeSTT支持多种语言的语音识别,方便全球用户使用。作为一个完全开源的项目,开发者可以根据自身需求进行功能扩展,增加新的语言支持或调整识别模型,以满足不同应用场景的需求。
这款工具支持多种输入音频流格式,并能将结果以文本或JSON格式输出,便于集成到各种应用中。这种灵活性使得它在智能家居、车载系统等应用中也能得心应手。
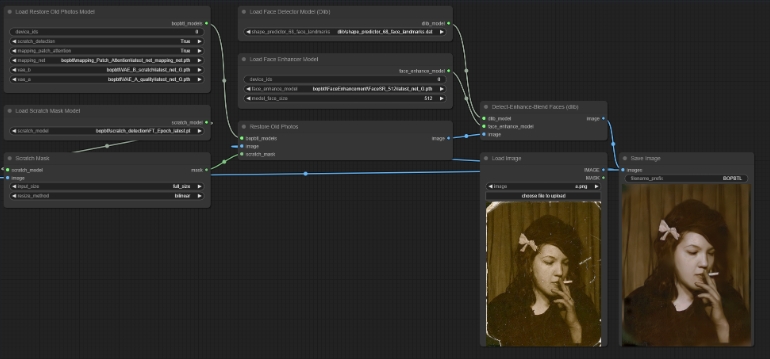
ComfyUI-Bringing-Old-Photos-Back-to-Life是一款专为修复老旧或低质量照片的工具。它能够自动去除照片中的划痕和杂质,使照片恢复到原有的清晰度和细节,通过一系列算法实现完美修复。
借助先进的面部检测和增强技术,ComfyUI能够提高照片中面部的细节和质量。这项功能尤其适合用于修复家庭合影或历史照片,使其更具现实感和生动性。
该工具集成在ComfyUI中,用户只需简单操作即可完成复杂的修复任务。通过安装小型检查点和VAE,用户可以更好地控制修复效果,提升用户体验。
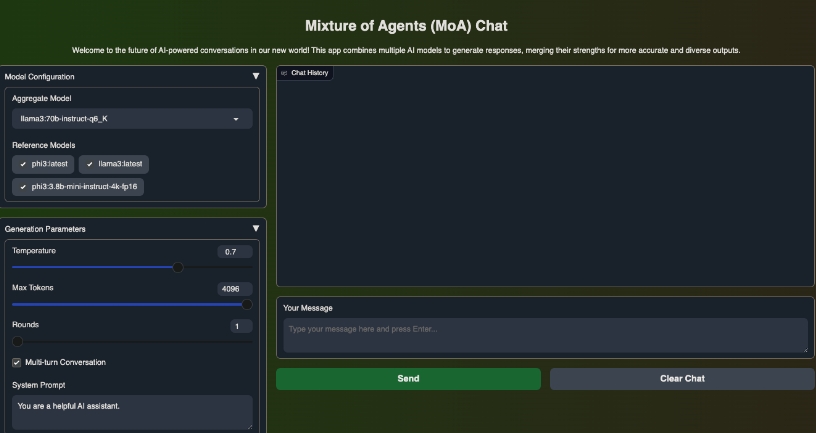
Mixture of Agents(MoA)通过整合多个大型语言模型(LLMs),实现了AI性能的提升。其分层架构允许每一层包含多个模型代理,以提供更全面和细致的输出。
用户可以选择并配置参考模型和聚合模型,以满足特定需求。通过调节参数如温度、最大标记数和处理轮次,用户可以微调生成过程,获得最佳结果。
MoA采用Gradio界面,设计直观且美观。用户可以通过简单的操作实现复杂的交互,支持单轮次和多轮次对话,提升用户体验。
“Screen to action using LLMs”项目通过大语言模型(LLM)将屏幕内容转换为具体动作。例如,它可以录制销售人员的屏幕内容,并自动将对话记录填充到CRM系统中,极大提高工作效率。
该项目能够对屏幕内容进行实时文本提取,并生成摘要。这一功能尤其适合在信息量大的场景中帮助用户快速回顾和整理信息。
项目还支持基于特定关键词或图像的自动化操作。例如,系统可识别屏幕上的狗的图片并自动触发发送推文的操作,增加了应用的智能性和自动化能力。
GPTPDF利用视觉大模型将PDF文件解析成Markdown格式,几乎完美地支持数学公式、表格等结构化内容。它能够高效地解析PDF文档中的复杂内容,保持原有的排版和格式。
该工具简单易用,每页解析费用仅为$0.013,大大降低了用户的使用成本。用户可以通过该工具轻松将复杂的PDF文件转换为可编辑的Markdown文档。
GPTPDF支持多种内容形式,包括图片、图表等。它能够将这些内容转换为结构化的Markdown格式,便于后续编辑和共享。
SherpaNCNN使用下一代Kaldi进行实时语音识别,支持iOS、Android等多平台。其离线处理能力意味着在没有互联网连接的情况下也能进行语音转文字,这在本地化应用中非常有利。
用户只需克隆仓库并进行简单编译,即可在本地使用。SherpaNCNN提供了简单的使用示例,用户可以快速上手,体验实时语音识别的强大功能。
除了离线识别,SherpaNCNN在实时识别方面也表现出色。其优化的处理架构使得即便在普通硬件环境下也能高效运行,满足多种应用场景需求。

实时语音技术在在线会议和直播中广泛应用,为参与者提供即时的字幕服务,提升沟通效率。语音转文字技术的准确性和速度直接影响会议的质量。
在客服系统和语音助手中,实时语音技术有助于提升用户体验。通过语音输入快速转换为文字,系统能够更加准确地理解用户需求,并提供相应的服务。
语音指令是智能家居和车载系统的重要交互方式。实时语音技术的高效识别能力确保了系统能够及时响应用户的指令,提供更智能的生活体验。






