

大模型RAG技术:从入门到实践

随机森林算法是一种强大的机器学习方法,广泛应用于分类和回归问题。它通过集成多棵决策树来提高模型的准确性和鲁棒性。随机森林算法通过引入随机性来避免模型过拟合,并具有处理高维数据集和评估特征重要性的能力。本文将深入探讨随机森林算法的原理、特点、生成过程以及在数据科学中的应用。
随机森林算法是一种由多棵决策树组成的集成算法,通过对多个决策树的结果进行投票来做出分类决策。它广泛应用于分类和回归问题中,具有出色的性能和灵活性。
单一的决策树容易过拟合,而随机森林通过集成多棵树,减少了过拟合的风险。每棵树的生成过程是相互独立的,从而提高了模型的稳定性。
随机森林由Leo Breiman在2001年引入,其核心思想是通过引入随机性来增强模型的泛化能力。这种方法后来被广泛应用于各种领域。
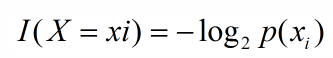
随机森林算法以其高准确率而闻名,特别是在处理复杂数据集时,能够有效地捕捉数据中的模式和特征。
它能够处理具有高维特征的数据集,而无需降维,这使得它在大数据分析中非常有用。
随机森林对于数据中的噪声和缺失值具有很好的鲁棒性,能够在不完美的数据环境中提供可靠的预测。
在构建决策树时,信息增益和熵是两个重要的概念。信息增益用于选择最佳分裂特征,而熵则用于度量数据的不确定性。
决策树是一种以特征为节点的树形结构,每个节点代表一个特征测试。常用的算法包括C4.5、ID3和CART。
集成学习是通过组合多个学习模型来解决单一预测问题的方法。随机森林就是集成学习的一种典型应用。

随机森林中的每棵树是通过从训练集随机抽样生成的。这种方法称为Bootstrap采样,即有放回地从训练集中抽取样本。
在每个树节点分裂时,随机选择一部分特征来进行判断,确保每棵树的多样性和独立性。
每棵树独立地对输入样本进行分类,最终的分类结果由所有树的投票结果决定,确保模型的稳定性。

在构建每棵树时,约有1/3的训练实例未被抽样,这部分样本称为袋外样本(OOB)。
通过对OOB样本进行分类,计算它们的误分类率,以此作为随机森林的误差估计。
OOB误差提供了一种无需交叉验证的模型评价方法,能够快速评估随机森林的泛化能力。
假设我们要预测某个人的收入层次,可以通过年龄、性别、教育程度等特征来进行预测。
每棵CART树根据不同的特征进行分类,例如根据年龄或行业对收入进行分类。
通过5棵CART树的投票结果,得出最终的收入层次预测。多数投票的结果作为最终的预测输出。
Python中可以使用Scikit-learn库来实现随机森林。以下是一个简单的示例代码。
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as np
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['is_train'] = np.random.uniform(0, 1, len(df)) <= .75
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
train, test = df[df['is_train']], df[~df['is_train']]
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2, random_state=0)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
preds = iris.target_names[clf.predict(test[features])]
pd.crosstab(test['species'], preds, rownames=['actual'], colnames=['preds'])在代码中,我们首先加载Iris数据集,然后使用随机森林算法进行训练,并对测试集进行预测。
最后,通过交叉表比较真实标签和预测结果,评估模型性能。
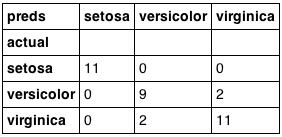
RandomForestClassifier进行训练和预测。通过交叉表比较真实标签和预测结果来评估模型性能。






