

文心一言写代码:代码生成力的探索

OpenAI 的 O1 模型在人工智能推理和多模态技术领域引发了广泛关注。本文将深入探讨基于 OpenAI O1 的 RAG(Retrieve and Generate)系统,分析其推理模式、多模态RAG进展以及在实际应用中的表现。
OpenAI O1 模型在推理阶段采用了多种策略,以提升其性能和准确性。这些策略包括 Best-of-N(BoN)、Stepwise BoN、Self-Refine 和 Agent Flow 等。
BoN 策略通过在推理阶段生成多个候选响应,利用奖励模型选择最合适的响应,提升模型的性能。这种方法允许模型在广阔的搜索空间中找到最优解,尽管可能增加计算负担,但显著提高了准确性。
Stepwise BoN 在传统 BoN 的基础上,通过分解复杂问题为多个子问题,逐步选择最佳响应。该策略在处理多步骤推理任务时尤为有效,但对模型的上下文跟随能力要求较高。
Self-Refine 通过多次迭代反馈优化模型输出,适用于需要精细调整的任务。其挑战在于设置合理的迭代终止条件,以避免计算资源的浪费。
Agent Flow 通过任务分解和使用域特定提示,减少不必要的长上下文推理步骤。这种策略在提高效率的同时,保持了推理的准确性。

多模态RAG技术通过结合文本和视觉数据,显著增强了模型的理解和生成能力。本文引用了《CUE-M: Contextual Understanding and Enhanced Search with Multimodal Large Language Model》中的研究成果,探讨了多模态嵌入和安全过滤的创新应用。
多模态RAG可以通过 MLLM(多模态大语言模型)结合图像搜索和增强检索,提升查询的准确性和丰富度。通过将图像转化为文本描述,模型能够更好地理解和处理复杂信息。
多模态RAG的安全策略包括实例级安全和类别级安全。实例级安全通过数据库匹配提供预定义响应,而类别级安全通过 API 选择器提供安全的类别级响应。
O1 模型在长上下文 RAG 任务中表现出了卓越的处理能力,尤其在复杂问题和超长文本处理中。与传统模型相比,O1 模型在多个基准测试中表现优异。
在 Databricks DocsQA 数据集上,O1 模型在长上下文下显示出显著的准确性和相关性提升,尤其在超过百万级词元的文本处理中展现了极强的能力。
FinanceBench 数据集考验模型的金融领域推理能力。在此数据集上,O1 模型在长上下文环境下保持了高质量的回答,凸显了其在处理专业术语和复杂金融逻辑方面的优势。
尽管 O1 模型在短上下文长度下存在一定的性能下降,但在更长的上下文环境中,依然能够提供高准确性的回答,显示出其强大的生成能力。

Google Gemini 1.5 是另一款长上下文 RAG 模型,其在超长上下文处理上的稳定性令人瞩目。
Gemini 1.5 在200万词元的超长上下文下,表现出一致的回答质量,优化算法有效控制了资源消耗。
Gemini 1.5 在超长上下文处理上的优势,为开发者提供了简化的开发体验,适合对开发效率要求高的项目。
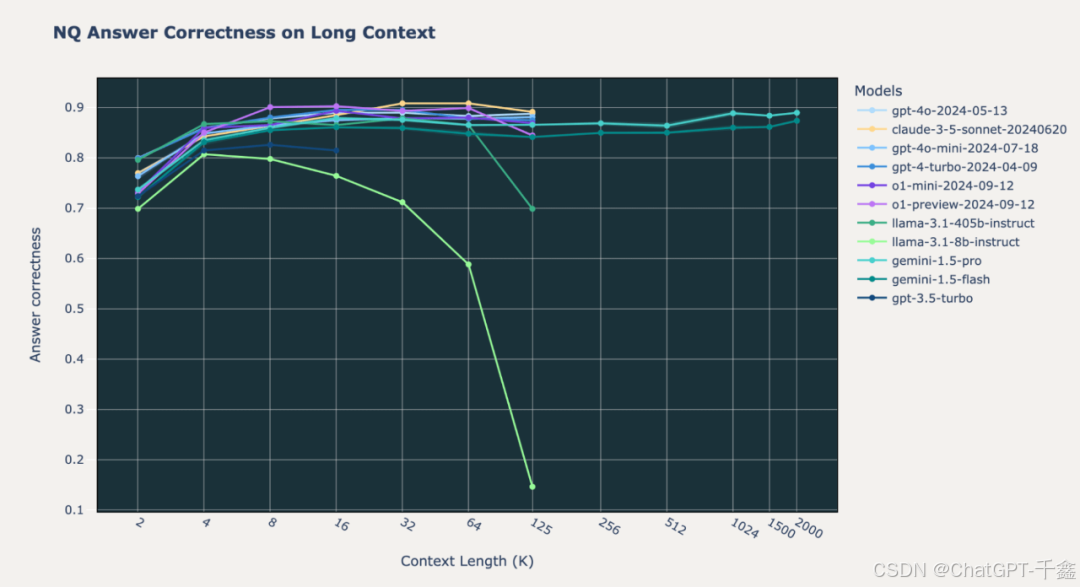
尽管 O1 和 Gemini 1.5 模型在长上下文任务中表现强大,但仍存在多种失败模式,理解这些模式有助于优化应用。
O1 模型的主要失败模式包括重复内容、随机内容和未遵循指令等。在短上下文下,模型可能简单回答“信息不可用”。
Gemini 1.5 主要问题在于主题敏感性和拒绝回答,尤其在短上下文下,常因缺失相关文档而拒绝回答。
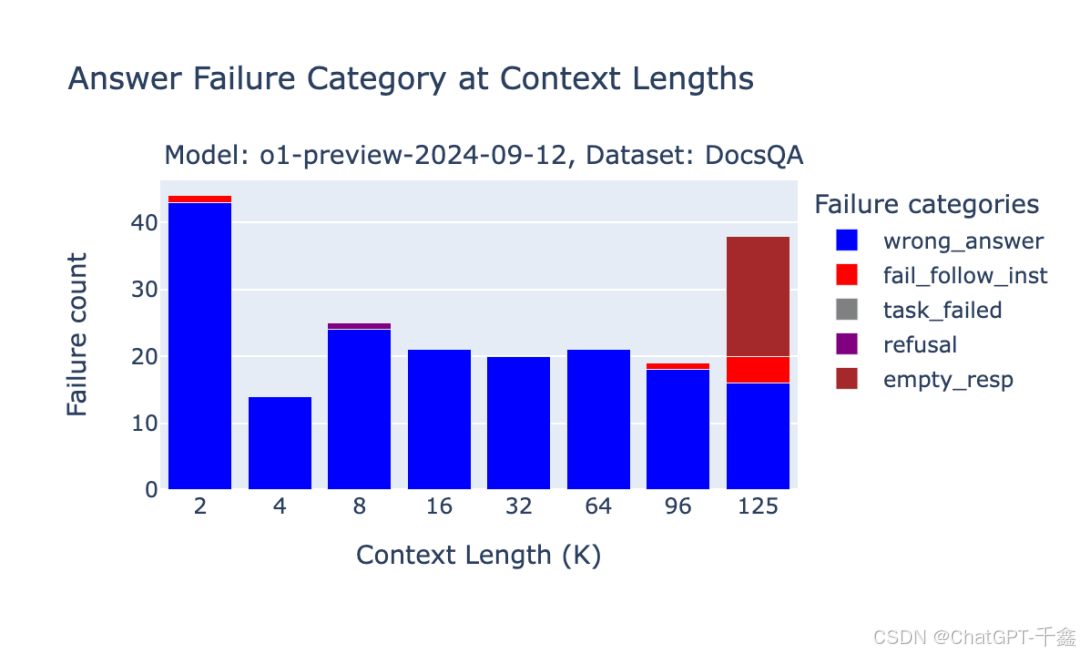
针对模型的表现与失败模式,开发者可以采取多种策略优化性能。
根据具体应用需求,选择适合的模型和上下文长度,如中短上下文下使用 O1 模型,超长上下文下使用 Gemini 1.5。
通过优化检索算法,确保检索文档与问题高度相关,动态调整上下文长度,以提升回答质量。
采取内容过滤与指令优化、多模型协同、错误监控与反馈机制等策略,提高系统稳定性和用户体验。
随着 AI 技术的进步,长上下文 RAG 在各种应用场景中的重要性日益凸显。O1 模型和 Gemini 1.5 的发布,为行业树立了新标杆,未来在海量文本数据处理中的应用值得期待。
问:什么是多模态RAG?
问:O1 模型和 Gemini 1.5 的主要区别是什么?
问:如何优化长上下文 RAG 模型的性能?






