

豆包 Doubao Image API 价格全面解析

基于 Hunyuan Image 的 RAG(Retrieval Augmented Generation)系统是一种创新的文本生成方法,通过结合外部知识库和视觉信息来增强模型的生成能力。在这种系统中,模型不仅从文本中提取信息,而且还利用图像数据来丰富和验证生成的内容。这种方法的核心是通过检索相关文档和图像,综合分析以提供更精确和上下文相关的生成结果。
RAG 系统的工作流程包括两个主要阶段:信息检索和文本生成。在信息检索阶段,系统会从一个多模态知识库中提取相关的文本和图像数据。在文本生成阶段,系统利用这些提取的信息生成高质量的回答。这种系统可以应用于多种场景,包括智能问答、内容创作和数据分析等。
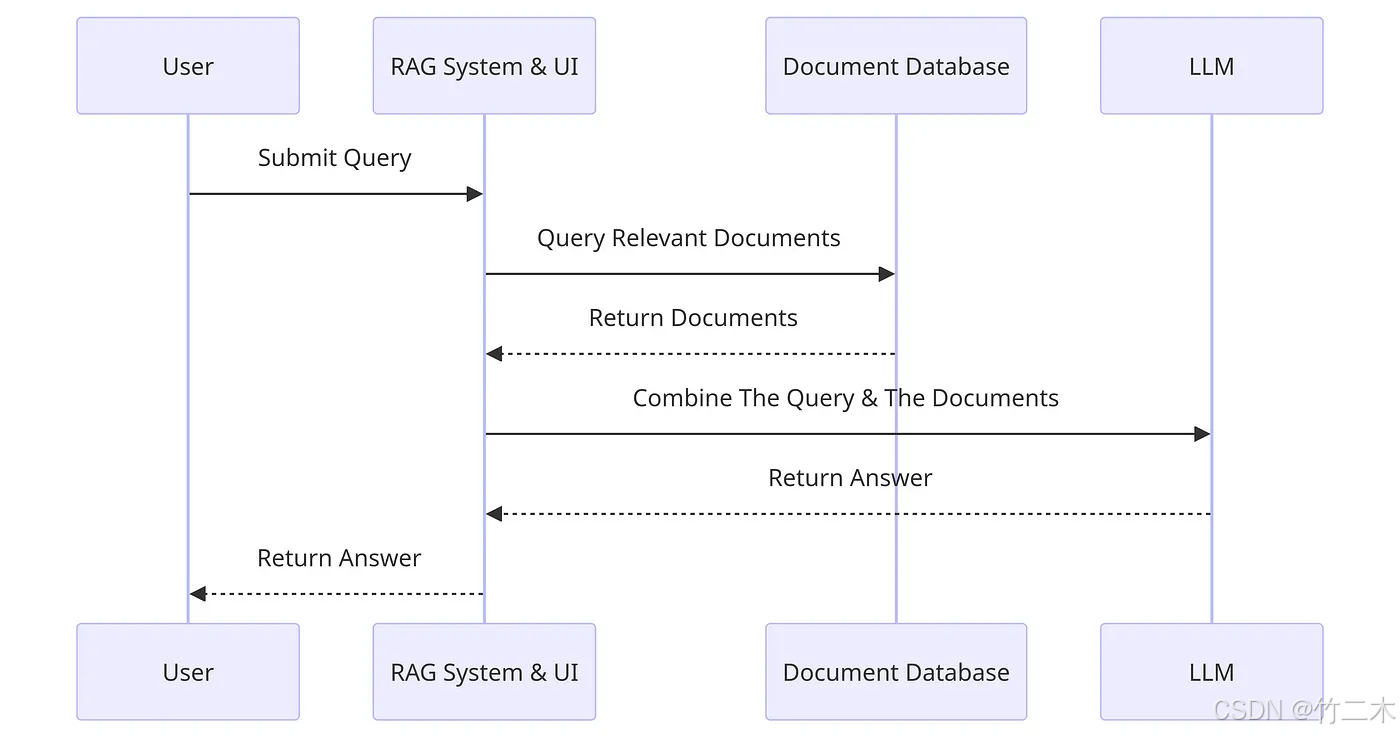
Hunyuan Image 是一种强大的图像处理工具,它能够从海量图像数据中提取有用的信息,并将这些信息转化为可用的知识。这使得它在 RAG 系统中扮演着至关重要的角色。通过结合 Hunyuan Image 的能力,RAG 系统不仅能够处理文本信息,还可以从相关图像中提取上下文和背景信息,增强生成的准确性和相关性。
在 RAG 系统中,Hunyuan Image 可以用于从图像中提取特征,并利用这些特征来增强文本生成过程。例如,在回答关于产品的具体问题时,系统可以通过分析产品图片来提供更详细的描述和建议。这种图文结合的方法不仅提高了回答的准确性,还增强了用户体验。
实现 Hunyuan Image 增强的 RAG 系统需要几个关键步骤:
构建一个多模态知识库是实现 RAG 系统的基础。在这个过程中,我们需要整合来自不同来源的文本和图像数据,并将其存储在一个高效的检索系统中。以下是构建知识库的基本步骤:
在构建知识库时,向量化技术是一个关键工具。它允许我们将文本和图像数据转化为高维向量,使得不同模态的数据可以在同一个空间中进行比较和检索。通过使用 Hunyuan Image 的嵌入模型,我们可以实现高效的多模态数据表示,从而在检索过程中获得更高的准确性。
RAG 系统在智能问答系统中的应用非常广泛。通过结合 Hunyuan Image 的能力,系统可以在回答用户问题时提供更为精确和详细的答案。例如,在医疗领域,系统不仅可以检索相关的医学文献,还可以分析医学影像来提供诊断建议。
在内容创作领域,RAG 系统可以帮助创作者生成更具创意和信息丰富的内容。通过利用文本和图像数据,系统能够在撰写文章、设计广告素材或生成报告时提供多角度的参考信息。
对于需要处理大量数据的分析任务,RAG 系统也可以发挥重要作用。通过结合文本和图像数据,系统可以为用户提供更为全面和直观的数据分析结果,帮助用户在复杂的数据集中发现有价值的信息。
实现一个基于 Hunyuan Image 的 RAG 系统,首先需要设计合理的系统架构。系统架构通常包括数据收集层、数据处理层和应用层。在数据收集层,我们需要整合来自不同来源的数据。在数据处理层,我们需要利用 Hunyuan Image 和其他工具进行数据的处理和优化。在应用层,我们需要开发用户接口和服务,以便用户可以轻松访问和利用系统的功能。
以下是一个简单的代码示例,展示如何使用 Hunyuan Image 和 Elasticsearch 构建一个 RAG 系统:
import config
from hunyuan import HunyuanEmbeddings
from langchain_elasticsearch import ElasticsearchStore
from typing import List
from langchain_core.documents import Document
secretid = config.get_settings().tcloud_secret_id
secretkey = config.get_settings().tcloud_secret_key
embeddings = HunyuanEmbeddings(secret_id=secretid, secret_key=secretkey)
ES_URL = config.get_settings().es_url
ES_API_KEY = config.get_settings().es_api_key
elastic_vector_search = ElasticsearchStore(embedding=embeddings, index_name="langchain_index", es_url=ES_URL, es_api_key=ES_API_KEY)
text = """...文档内容..."""
documents: List[Document] = [...] # 文档列表
elastic_vector_search.add_documents(documents)在构建和维护多模态知识库时,数据质量和一致性是首要挑战。为了解决这个问题,我们需要采用严格的数据清洗和标注策略,确保数据的准确性和完整性。此外,定期更新和审核数据也是保持知识库有效性的关键。
随着数据量的增加,系统的性能和扩展性可能成为瓶颈。为此,我们可以采用分布式计算和存储技术,优化数据检索和处理流程。此外,使用缓存和负载均衡技术也可以提高系统的响应速度。
在设计用户界面时,我们需要考虑到用户的使用习惯和需求。提供直观的操作界面和丰富的交互功能,可以提高用户的满意度和使用效率。
随着多模态技术的不断发展,RAG 系统的能力和应用范围将进一步扩展。未来,我们可以期待更高效的多模态数据处理算法和更智能的文本生成技术,为用户提供更丰富的服务和体验。
随着人工智能技术的普及,基于 RAG 系统的应用将越来越广泛。无论是在教育、医疗还是商业领域,RAG 系统都将成为一种重要的工具,帮助用户更好地利用信息和知识。
在未来的发展中,数据安全和隐私保护将成为 RAG 系统必须面对的重要问题。通过采用先进的加密技术和数据保护策略,我们可以在保证用户隐私的前提下,提供高质量的服务。
RAG 系统是一种结合信息检索和文本生成的技术,通过利用外部知识库来增强模型的生成能力。
Hunyuan Image 可以从图像中提取特征,并结合文本信息,增强 RAG 系统的生成能力和准确性。
构建多模态知识库需要收集和处理来自不同来源的文本和图像数据,并使用向量化技术进行索引和存储。
RAG 系统可以应用于智能问答、内容生成、数据分析等多个领域,为用户提供多样化的服务。
可以通过优化数据处理流程和采用分布式计算技术,提高 RAG 系统的性能和响应速度。





