

文心一言写代码:代码生成力的探索

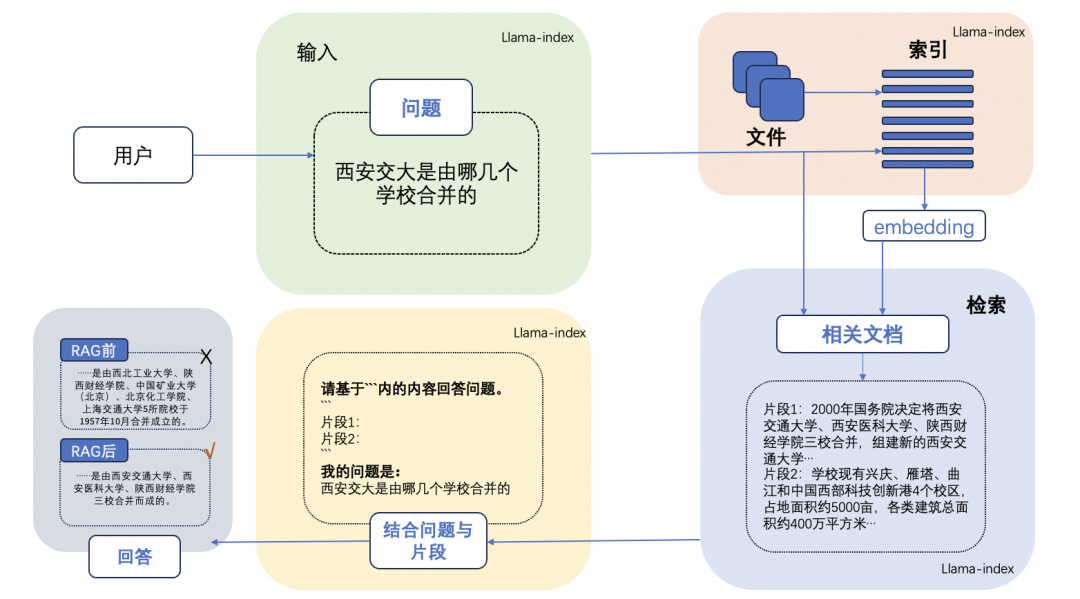
检索增强生成(RAG)技术是一种结合检索与生成的创新方法,极大地提升了大语言模型在处理复杂任务时的准确性和效率。RAG技术通过在生成答案之前,从广泛的文档数据库中检索相关信息,然后利用这些信息来指导生成过程。这样的方法不仅有效地缓解了传统语言模型可能产生的“幻觉”问题,还提高了知识更新的速度和内容生成的可追溯性。
RAG系统的运作流程主要包括三个步骤:
在RAG系统中,小型语言模型(SLMs)往往面临一些挑战,例如复杂查询的解释、多步推理以及查询与文档之间的语义匹配等问题。这些问题导致SLMs在性能上不如大型语言模型(LLMs)那么出色,特别是在需要大量计算资源的场景中表现尤为明显。
然而,小型语言模型也有其独特的优势,例如在模式匹配和局部文本处理方面的卓越表现,以及通过显式结构信息来弥补语义能力的不足。为了优化SLMs在RAG系统中的应用,研究者们提出了MiniRAG框架,该框架通过将复杂操作分解为更简单的步骤来维持系统的鲁棒性。
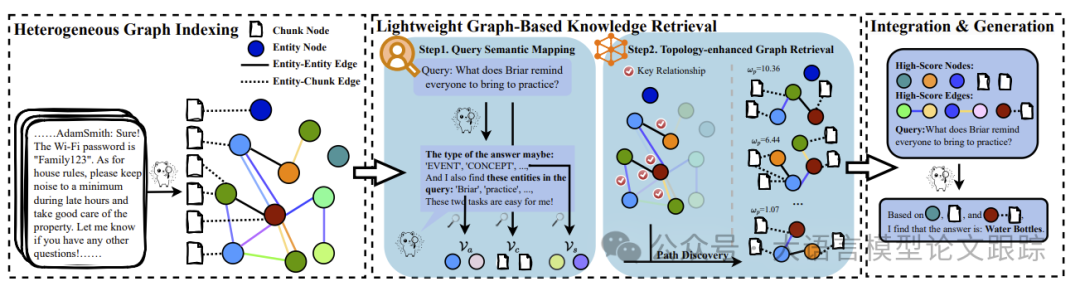
MiniRAG框架由两个核心组件组成:异构图索引和轻量级图知识检索。该框架旨在通过高效的索引和检索机制,最大化利用小型语言模型的优势。
异构图索引是MiniRAG框架的基础,旨在构建一个语义感知的知识表示结构。SLMs在这一过程中面临两大挑战:
为了解决这些问题,MiniRAG框架引入了一种数据索引机制,生成语义感知的异构图。该图结合了文本块和命名实体,创建语义网络,便于精确的信息检索。
在设备上运行的RAG系统受限于计算能力和数据隐私,因此需要依赖较小的替代方案。MiniRAG框架提出了一种基于图的知识检索机制,通过语义感知的异构图实现了高效的知识检索。
从容大模型1.5版本包括多种尺寸的基础和聊天模型,这些模型不仅在性能上有显著提升,还支持多语言。该版本的特别之处在于其强大的外部系统链接能力,结合RAG技术,可以实现更高效的智能问答系统。
与之前的版本相比,从容大模型1.5在多个基准评测中表现出色,尤其在自然语言理解、数学计算和逻辑推理等任务上。其强大的工具调用能力,以及Code Interpreter的能力,使得它能够在更多应用场景中发挥作用。
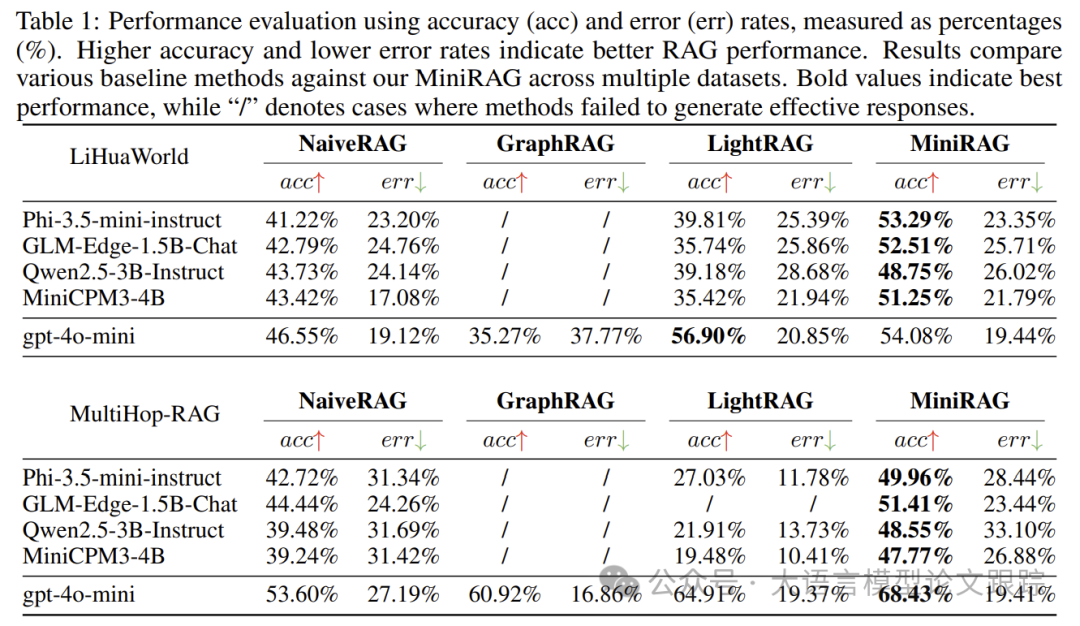
基于从容大模型1.5和LlamaIndex,可以搭建一个高效的智能问答系统。LlamaIndex提供的上下文增强功能,使得系统能够更准确地生成文本答案。
LlamaIndex是一个基于LLM的应用程序数据框架,专注于上下文增强。它提供了必要的抽象,可以更轻松地摄取、构建和访问私有或特定领域的数据。
LlamaIndex的核心功能包括数据摄取、数据结构化、数据检索和应用集成。它不仅支持向量存储索引、树索引等多种数据结构,还可以与LangChain、Flask等框架集成,极大地增强了应用的灵活性和功能性。
GTE文本向量是自然语言处理领域的重要工具,尤其在文本聚类、文本相似度计算等任务中发挥关键作用。基于GTE的文本表示模型,能够在学术研究和工业应用中提供更高效的文本处理能力。
GTE模型采用Dual Encoder框架,通过大规模弱监督数据和高质量精标数据进行训练。其应用范围包括双句文本相似度计算、query与多doc候选相似度排序等。
RAG技术是一种结合检索与生成的创新方法,通过在生成答案之前检索相关信息,极大地提升了内容生成的准确性和相关性。
小型语言模型在RAG系统中面临复杂查询解释、多步推理、语义匹配等挑战。为优化其性能,MiniRAG框架提供了有效的解决方案。
从容大模型1.5在多语言处理、工具调用和Code Interpreter能力上表现出色,是RAG系统中的强劲选择。
LlamaIndex通过提供上下文增强功能、数据结构化和检索工具,支持RAG系统构建更高效的智能问答系统。
GTE文本向量可以用于计算句子间的相似度,其模型通过Dual Encoder框架训练,使得相似度计算更为准确和高效。






