

文心一言写代码:代码生成力的探索

大语言模型(LLMs)在自然语言处理领域展现出了显著的能力,然而,它们也面临着一些挑战。首先是遗忘长尾知识的问题,大语言模型倾向于记住常见的信息,而对长尾知识的掌握较差。其次,提供过时知识是另一个难题,模型可能会使用训练时的信息而不是最新的数据。此外,LLMs还会产生幻觉,生成不符合事实的内容,这些问题限制了它们的应用。
检索增强生成(RAG)是一种通过检索系统获取外部知识来增强大语言模型的方法,已经被证明有效缓解了LLMs的幻觉问题。RAG系统通常通过网络搜索引擎进行检索,然后将检索到的内容输入到大语言模型中以增强生成能力。然而,传统的RAG系统多使用纯文本作为知识格式,导致在转换过程中丢失了HTML中的结构和语义信息。

HTML格式的文档保留了文档的结构信息和语义信息,因此在RAG中使用HTML格式可以提供更丰富的信息。尽管如此,HTML格式也带来了一些挑战,例如处理更长的输入序列以及去除HTML中的噪声内容,如CSS和JavaScript。
HtmlRAG是一种使用HTML代替纯文本作为RAG系统中检索知识格式的新范式。通过保留HTML文档的语义和结构信息,HtmlRAG可以提供更准确的生成能力。这一方法通过HTML清洗和修剪来解决HTML带来的噪声问题。
HTML清洗的目的是去除不必要的内容,如CSS、JavaScript以及冗长的HTML标签属性,同时保留HTML标签提供的结构信息。通过这一过程,HtmlRAG能够减少无意义的内容,提高信息的准确性。
HtmlRAG通过构建块树,将所有检索到的HTML文档连接并解析为DOM树。块树的构建允许通过合并子节点来控制粒度,以适应不同的修剪需求。这个过程大大减少了计算成本,同时保留了关键的语义信息。

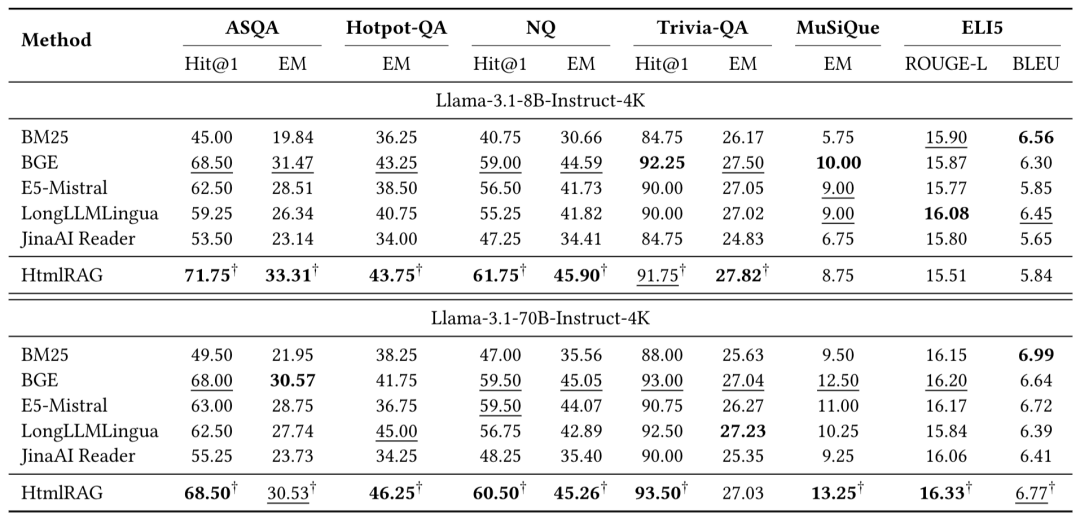
HtmlRAG在ASQA、HotPotQA等六个问答数据集上进行了测试。实验评估指标包括Exact Match、Hit@1等。实验环境使用了Llama – 3.1 – 70B – Instruct和Llama – 3.1 – 8B – Instruct,以确保实验的全面性。
实验结果显示,HtmlRAG在所有数据集上均超过了基线方法。这证明了HTML修剪的有效性,以及HtmlRAG在保留信息方面的优势。在分块精炼器中,HtmlRAG充分利用了HTML的结构信息,避免了纯文本转换中的信息丢失。
HtmlRAG提供了一个开源工具包,可以应用于任何RAG系统。用户可以通过pip安装htmlrag,也可以从源码安装。安装后,用户可以调用clean_html函数进行HTML清理,使用build_block_tree函数构建块树。
from htmlrag import clean_html, build_block_tree
simplified_html = clean_html(html_content)
block_tree, simplified_html = build_block_tree(simplified_html)HtmlRAG通过将HTML作为RAG系统的外部知识格式,显著提高了信息的保留和处理能力。实验结果验证了其在各类数据集上的有效性。
随着大语言模型能力的增强,HTML将更适合成为外部知识格式。希望未来能开发出更好的HTML处理解决方案,以进一步提升RAG系统的效率和准确性。
问:HtmlRAG如何提高生成准确性?
问:使用HtmlRAG需要什么技术条件?
问:HtmlRAG适用于哪些领域?
问:如何处理HTML中冗余的内容?
问:HtmlRAG的性能如何?





